前言
先簡單聊聊分布式演算法的重要性問題
在分布式微服務系統的專案中,最重要的是 如何選擇或者設計合適的演算法,來解決一致性問題以及可用性等相關問題
而分布式系統的最關鍵之處,在于根據場景的需要選擇合適的演算法,在一致性和可用性之間權衡(注:因為磁區容錯性是必須滿足的),而權衡妥協的關鍵在于是否了解各個演算法的特點,對于其他技術也適用,找到影響選擇的因素,了解各個技術的特點,根據場景需要權衡選擇,
下面是一些分布式演算法的比較:
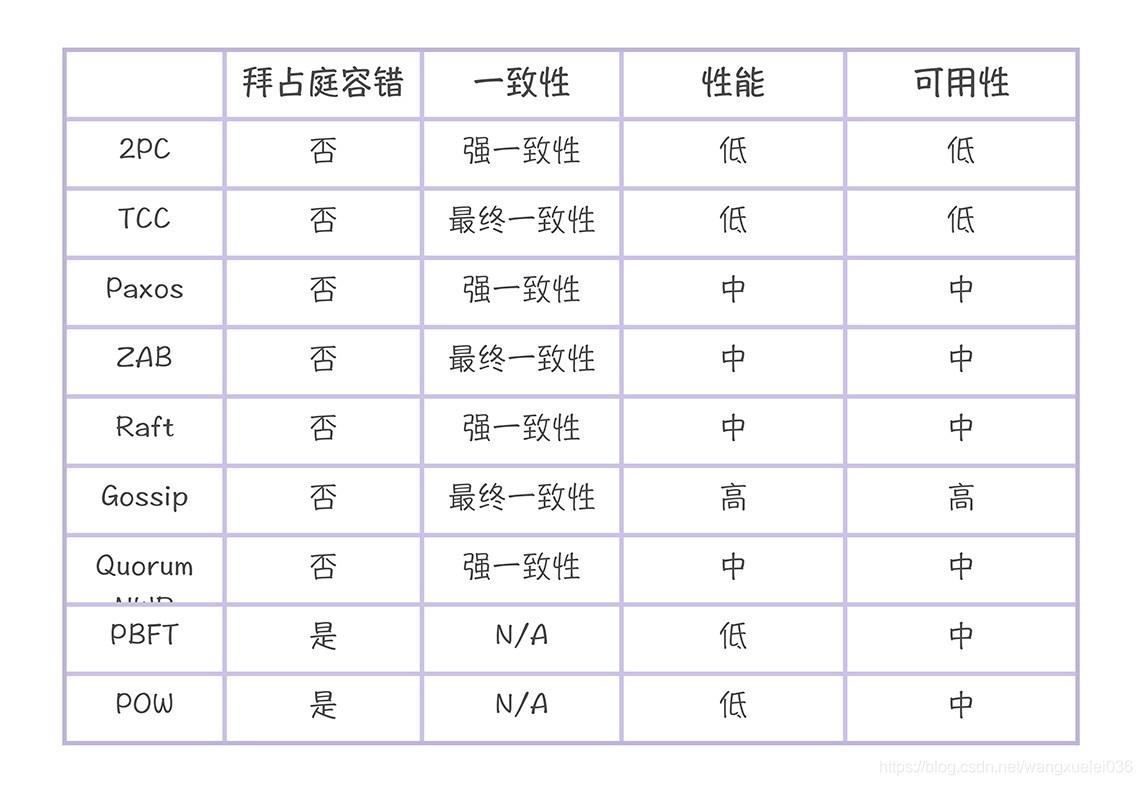
當然本章不是介紹所有的分布式演算法,我也沒法僅僅使用一篇文章就把上面表格中覆寫的分布式演算法知識清晰的講述,
所有我們重點講解的是現在分布式演算法或者說現在分布式資料一致性首選演算法:Raft 演算法
raft是工程上使用較為廣泛的強一致性、去中心化、高可用的分布式協議,在這里強調了是在工程上,因為在學術理論界,最耀眼的還是大名鼎鼎的Paxos,但Paxos是:少數真正理解的人覺得簡單,尚未理解的人覺得很難,大多數人都是一知半解,本人也花了很多時間、看了很多材料也沒有真正理解,直到看到raft的論文,兩位研究者也提到,他們也花了很長的時間來理解Paxos,他們也覺得很難理解,于是研究出了raft演算法,
?? raft是一個共識演算法(consensus algorithm),所謂共識,就是多個節點對某個事情達成一致的看法,即使是在部分節點故障、網路延時、網路分割的情況下,這些年最為火熱的加密貨幣(位元幣、區塊鏈)就需要共識演算法,而在分布式系統中,共識演算法更多用于提高系統的容錯性,raft協議就是一種leader-based的共識演算法,與之相應的是leaderless的共識演算法,
??本文基于論文In Search of an Understandable Consensus Algorithm對raft協議進行分析,當然,還是建議讀者直接看論文,
簡單提一下,因為Raft協議也是基于CAP理論,但是現在大部分人對CAP 存在一個誤解,認為無論在什么情況下,A和C 只能選擇一個,因為P必選,其實,在不存在網路磁區的情況下或者網路故障等問題的時候,也就是分布式系統正常,P 不需要的時候,C和P是能同時保證的,只有發生故障磁區的時候,在需要的P的時候,才會在C和P 中抉擇,
Raft協議
首先來一句話簡單說下Raft 是什么:從本質上,Raft協議就是一切以領導者為準的方式,實作一系列值的共識和各節點日志的一致性
現在我們帶著一些問題,邊思考邊分析Raft協議
(1)如何選舉leader?
(2)節點間是如何通訊的呢?
(3)資料一致性是如何保證的?
(4)資料不一種的時候如何進行修復?
leader選舉
領導者周期性地向所有跟隨者發送心跳訊息(即不包含日志項的日志復制 RPC 訊息),通知大家我是領導者,阻止跟隨者發起新的選舉,
如果在指定時間內,跟隨者沒有接收到來自領導者的訊息,那么它就認為當前沒有領導者,推舉自己為候選人,發起領導者選舉,
在一次選舉中,贏得大多數選票的候選人,將晉升為領導者,在一個任期內,領導者一直都會是領導者,直到它自身出現問題(比如宕機),或者因為網路延遲,其他節點發起一輪新的選舉,
在一次選舉中,每一個服務器節點最多會對一個任期編號投出一張選票,并且按照“先來先服務”的原則進行投票,比如節點 C 的任期編號為 3,先收到了 1 個包含任期編號為 4 的投票請求(來自節點 A),然后又收到了 1 個包含任期編號為 4 的投票請求(來自節點 B),
那么節點 C 將會把唯一一張選票投給節點 A,當再收到節點 B 的投票請求 RPC 訊息時,對于編號為 4 的任期,已沒有選票可投了,
🤔思考:萬一節點都同時選舉自己,那不是一直都沒法重新選舉leader成功?
Raft 演算法實作了隨機超時時間的特性,也就是說,每個節點等待領導者節點心跳資訊的超時時間間隔是隨機的,集群中沒有領導者,而節點 A 的等待超時時間最小(150ms),它會最先因為沒有等到領導者的心跳資訊,發生超時,這個時候,節點 A 就增加自己的任期編號,并推舉自己為候選人,先給自己投上一張選票,然后向其他節點發送請求投票 RPC 訊息,請它們選舉自己為領導者,如果選舉失敗,各個節點就會隨機進入一個睡眠時間,因為各個節點隨機,一般最多幾次一定能選舉成功,
在 Raft 演算法中,隨機超時時間是有 2 種含義的,這里是很多同學容易理解出錯的地方,需要你注意一下:
(1) 跟隨者等待領導者心跳資訊超時的時間間隔,是隨機的;
(2)如果候選人在一個隨機時間間隔內,沒有贏得過半票數,那么選舉無效了,然后候選人發起新一輪的選舉,也就是說,等待選舉超時的時間間隔,是隨機的,
🤔思考:raft協議是以leader為準的協議,那新leader節點資料是完整的?
在Raft 中,副本資料是以日志的形式存在的,其中日志項中的指令表示用戶指定的資料,蘭伯特的 Multi-Paxos 不要求日志是連續的,但在 Raft 中日志必須是連續的,
因為在 Raft 中,日志不僅是資料的載體,同時,日志的完整性還影響領導者選舉的結果,也就是說,日志完整性最高的節點才能當選領導者
在選舉中,會選擇日志完整性高的跟隨者(也就是最后一條日志項對應的任期編號值更大,索引號更大),拒絕投票給日志完整性低的候選人,比如節點 B 的任期編號為 3,節點 C 的任期編號是 4,節點 B 的最后一條日志項對應的任期編號為 3,而節點 C 為 2,那么當節點 C 請求節點 B 投票給自己時,節點 B 將拒絕投票,也就是日志完整度不比半數節點低的節點),才能當選領導者;其次,在 Raft 中,日志必須是連續的,這個很重要,
第二個問題沒怎么懂,沒多大關系,你只需要知道,選舉的時候,類似于kafka里面的high watermark機制,從滿足最全副本中選舉出一個新leader領導者,
但這里希望你能又想到兩個問題,為什么副本資料是以日志的形式存在的?那什么時候日志資料轉為真正的資料集?
注 : 方式得當,知識不難學,每個人有每個人的學習方式,如果你還沒找到屬于自己的獨特方式,可以多借鑒別人的,我個人喜歡學一個知識,就提出一些關鍵的疑問,先自己分析思考,然后查閱相關的文章,
Raft一次請求流程
共識演算法的實作一般是基于復制狀態機(Replicated state machines),何為復制狀態機:
If two identical, deterministic processes begin in the same state and get the same inputs in the same order, they will produce the same output and end in the same state.
簡單來說:相同的初識狀態 + 相同的輸入 = 相同的結束狀態,引文中有一個很重要的詞deterministic,就是說不同節點要以相同且確定性的函式來處理輸入,而不要引入一下不確定的值,比如本地時間等,如何保證所有節點 get the same inputs in the same order,使用replicated log是一個很不錯的注意,log具有持久化、保序的特點,是大多數分布式系統的基石,
?因此,可以這么說,在raft中,leader將客戶端請求(command)而不是值,封裝到一個個日志項(log entry),將這些log entries復制(replicate)到所有follower節點,然后大家按相同順序應用(apply)log entry中的command,則狀態肯定是一致的,
下圖形象展示了這種log-based replicated state machine:
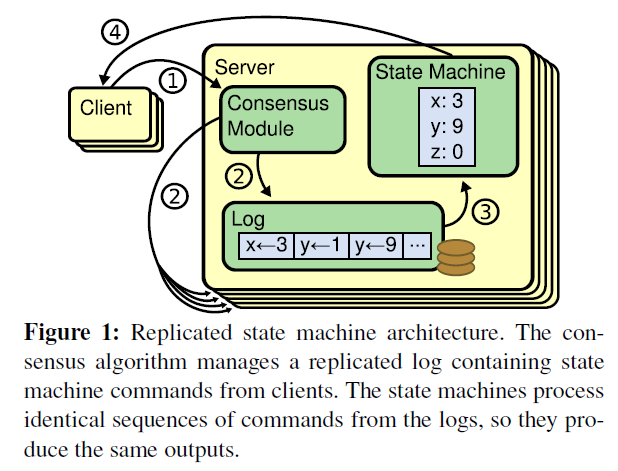
State Machine 可以理解為是命令運行后的值區域或者說是一個值狀態等,
流程提交程序:
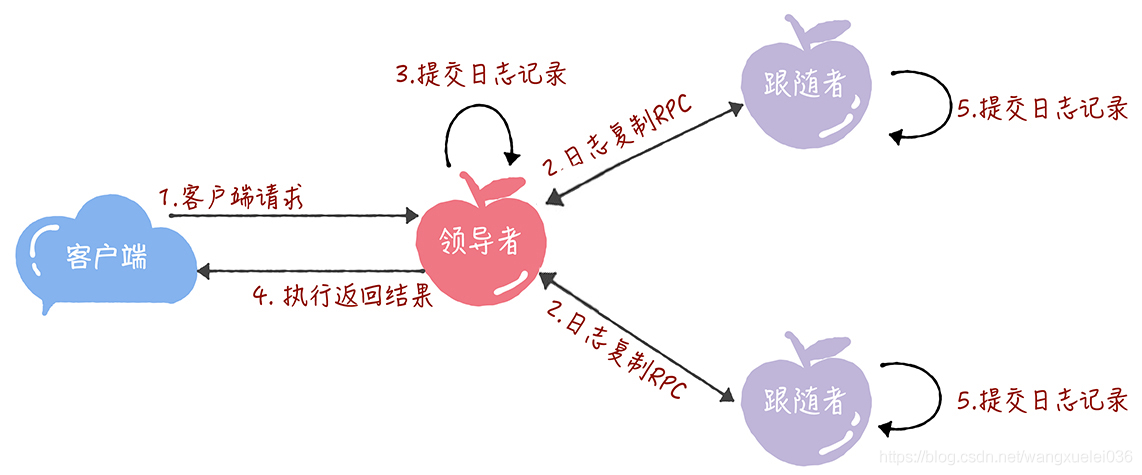
- 接收到客戶端請求后,領導者基于客戶端請求中的指令,創建一個新日志項(log entry),并附加到本地日志中,
- 領導者通過日志復制 RPC,將新的日志項(log entry)并行復制到其他的服務器,
- 等待領導者將日志項,成功復制到大多數的服務器上,
- 領導者會將這條日志項應用到它的狀態機中(state machine),
- 領導者將執行的結果回傳給客戶端,
- 當跟隨者接收到心跳資訊,或者新的日志復制 RPC 訊息后(注:心跳資訊和日志復制資訊中會攜帶提交資訊),如果跟隨者發現領導者已經提交了某條日志項,而它還沒應用,那么跟隨者就將這條日志項應用到本地的狀態機中,
思考🤔:為什么是日志復制,日志復制能復制資料?日志復制里面存盤的資料格式是如何?
Raft協議中,副本資料是以日志的形式存在,日志中存盤的是日志項,日志項是一種資料格式,它主要包含用戶指定的資料,也就是指令(Command),還包含一些附加資訊,比如索引值(Log index)、任期編號(Term),那你該怎么理解這些資訊呢?如下:
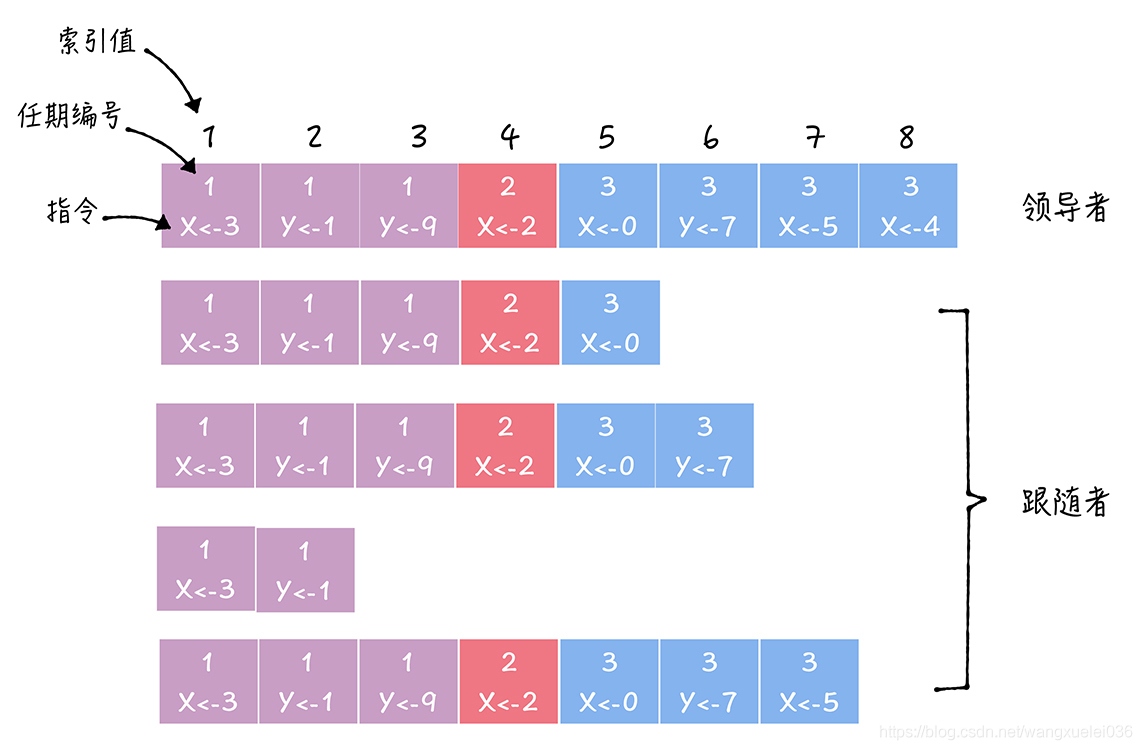
指令:一條由客戶端請求指定的、狀態機需要執行的指令,你可以將指令理解成客戶端指定的資料,
索引值:日志項對應的整數索引值,它其實就是用來標識日志項的,是一個連續的、單調遞增的整數號碼,(進行日志糾錯 一致性檢測的時候需要使用)
任期編號:創建這條日志項的領導者的任期編號,
理解了日志復制程序,以及日志格式, 那么如果宕機故障等導致日志不一致的情況 該如何是好?Raft 協議又如何處理?
回想一下,我們上文一直提到的日志連續性,是不是想到了什么,遵循約定號的規則,對于違反規則的地方,那么就是問題節點,是不是跟我code時候,約定大于配置類似,找到一個合適的方式來判定不一致的節點,這里利用的就是順序性,
簡單的說 : 每個新的日志項會帶有上一個日志項的任期(PreLogTerm)和索引值(PreLogEntry),follewer節點會先檢查自己上一個日志項(log entry) 和 這次新到來日志項(log entry )帶有的資訊是否一致,
大致流程如下:
- 領導者通過日志復制 RPC 訊息,發送當前最新日志項到跟隨者(為了演示方便,假設當前需要復制的日志項是最新的),這個訊息中包含的 PrevLogEntry(上一個日志項的索引值) 值為 7,PrevLogTerm(上一個日志項的任期) 值為 4,
- 如果跟隨者在它的日志中,找不到與 PrevLogEntry 值為 7、PrevLogTerm 值為 4 的日志項,也就是說它的日志和領導者的不一致了,那么跟隨者就會拒絕接收新的日志項,并回傳失敗資訊給領導者,
- 這時,領導者會遞減要復制的日志項的索引值,并發送新的日志項到跟隨者,這個訊息的 PrevLogEntry 值為 6,PrevLogTerm 值為 3,
- 如果跟隨者在它的日志中,找到了 PrevLogEntry 值為 6、PrevLogTerm 值為 3 的日志項,那么日志復制 RPC 回傳成功,這樣一來,領導者就知道在 PrevLogEntry 值為 6、PrevLogTerm 值為 3 的位置,跟隨者的日志項與自己相同,
- 領導者通過日志復制 RPC,復制并更新覆寫該索引值之后的日志項(也就是不一致的日志項),最終實作了集群各節點日志的一致,
網路磁區導致多leader 怎么辦
答:raft協議中有一個約定,不能提交之前任期內log 記錄作為commit點,
原因是如果在這一程序中,發生了網路磁區或者網路通信故障,使得Leader不能訪問大多數Follwers了,那么Leader只能正常更新它能訪問的那些Follower服務器,而大多數的服務器Follower因為沒有了Leader,他們重新選舉一個候選者作為Leader,然后這個Leader作為代表于外界打交道,如果外界要求其添加新的日志,這個新的Leader就按上述步驟通知大多數Followers,如果這時網路故障修復了,那么原先的Leader就變成Follower,在失聯階段這個老Leader的任何更新都不能算commit,都回滾,接受新的Leader的新的更新,
簡單來說:就是follewer 節點只聽從當前任期內leader 的資料變更,所以任期(term) 這個也是一個核心概念,后續如果old leader 連入進來會發現當前任期大于自己任期,自己將會變成follewer節點,
🤔繼續思考下一個問題:raft協議是基于日志追加和不可回滾性來實作(append-only),那么日志檔案越來越多咋辦?
想想Mysql 作資料恢復的時候一般是怎么弄得?dump(快照) + binlog,也就是 快照 + 日志追加方式 來實作資料恢復
其實Raft協議中也差不多
日志壓縮
在實際的系統中,不能讓日志無限增長,否則系統重啟時需要花很長的時間進行回放,從而影響可用性,Raft采用對整個系統進快照行來處理,快照之前的日志都可以丟棄,
每個server獨立的對自己的系統狀態進行快照,并且只能對已經committed log entry(已經應用到了狀態機)進行快照,快照有一些元資料,包括last_included_index,即快照覆寫的最后一條commited log entry的 log index,和last_included_term,即這條日志的termid,這兩個值在快照之后的第一條log entry的AppendEntriesRPC的一致性檢查的時候會被用上,之前講過,一旦這個server做完了快照,就可以把這條記錄的最后一條log index及其之前的所有的log entry都刪掉,
snapshot的缺點就是不是增量的,即使記憶體中某個值沒有變,下次做snapshot的時候同樣會被轉存到磁盤,
當leader需要發給某個follower的log entry被丟棄了(因為leader做了快照),leader會將快照發給落后太多的follower,或者當新加進一臺機器時,也會發送快照給它,
發送快照時使用新的RPC,InstalledSnapshot,
做snapshot有一些需要注意的性能點:
- 不要做太頻繁,否則消耗磁盤帶寬,
- 不要做的太不頻繁,否則一旦server重啟需要回放大量日志,影響availability,系統推薦當日志達到某個固定的大小做一次snapshot,
- 做一次snapshot可能耗時過長,會影響正常log entry的復制,這個可以通過使用寫時復制的技術來避免快照程序影響正常log entry的復制,
小結
上述介紹總結下來大致為以下幾點
- Election Safty :每一個任期內只能有一個領匯入
- Leader Append-Only:leader只能追加日志條目,不能重寫或者洗掉日志條目
- Log Maching:如果兩個日志條目的index和term都相同,則兩個如果日志中,兩個條目及它們之前的日志條目也完全相同
- Leader Completeness:如果一條日志被commited過,那么大于該日志條目任期的日志都應該包含這個點,也就是說當一個新的leader產生時它一定包含著前一個leader所處理過的commited點,
- State Machine Safety :如果一個server將某個特定index的日志條目交由狀態機處理了,那么對于其他server,交由狀態及處理的log中相同index的日志條目應該相同
Raft將共識問題分解成兩個相對獨立的問題,leader election,log replication,流程是先選舉出leader,然后leader負責復制、提交log(log中包含command)
??為了在任何例外情況下系統不出錯,即滿足safety屬性,對leader election,log replication兩個子問題有諸多約束
leader election約束:
- 同一任期內最多只能投一票,先來先得
- 選舉人必須比自己知道的更多(比較term,log index)
log replication約束:
- 一個log被復制到大多數節點,就是committed,保證不會回滾
- log entry 是連續的
- leader一定包含最新的committed log,因此leader只會追加日志,不會洗掉覆寫日志
- 不同節點,某個位置上日志相同,那么這個位置之前的所有日志一定是相同的
- Raft never commits log entries from previous terms by counting replicas.
??本文是自己學習極客時間 《分布式協議與演算法實踐 》作的總結,整體評價,課程還行,如果有什么錯誤之錯,請留言告知,感謝,

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/158500.html
標籤:其他