文章目錄
- 前言
- 相關資料結構對比
- ConcurrentHashMap原理
- 總結
前言
面試中常常問到Hashmap原理,這屬于第一階段的過招,之后面試官可能會順勢問一下,Hashmap是否是執行緒安全的,連環問于是開始了,如果你回答不是,那么緊接著面試官會問有沒有什么資料結構可以保證執行緒安全,有一定研究的你可以會馬上聯想到有,比如
ConcurrentHashMap,好戲開始上演……
請先看下面代碼:
public class Test {
private ConcurrentHashMap mMap = new ConcurrentHashMap();
// map中不存在才加入,否則不加入
public void addIfNotExists(String key, String value) {
if (!mMap.containsKey(key)) {
mMap.put(key, value);
}
}
}
請問:是否是執行緒安全?
可能你會條件反射的回答,是執行緒安全的,因為之前的回答已經做了一定的鋪墊,那么到底是不是執行緒安全的呢?
問題的背后,往往是深層次的原理考察,于是,我開始了相關知識模塊V1.0的構建,
第一步,了解HashMap原理和特點,并同時對比聯想相鄰的知識點,在查閱大量資料后,下面直接說結論,不再此一一展開,
相關資料結構對比
-
HashMap
讀取快,插入慢,執行緒不安全
底層是陣列+鏈表 結構,當兩個執行緒同時插入需要擴容的時候,獲得改map的size()大小不一樣,則會報錯,當有兩個執行緒在讀,第三個執行緒正好在對map擴容時,這兩個執行緒就會進入死回圈,cup占用率就會高,
在多執行緒,使用HaspMap就行put操作會引起死回圈,導致cpu100%,所在在并發情況不能使用HashMap,
HashMap在并發執行put操作時會引起死回圈,是因為多執行緒會導致HashMap的Entry鏈表形成環形資料結構,一旦形成環形資料結構,Entry的next節點永遠不為空,就會產生死回圈獲取Entry,
- LinkedHashMap
? 讀取快,插入慢
- treeMap
可以實作元素的自動排序
-
HashTable
執行緒安全,
HashTable容器使用synchronized來保證執行緒安全,但在執行緒競爭激烈的情況下HashTable的效率非常低下,因為在一個執行緒訪問HashTable的同步方法,其它執行緒也訪問HashTable的同步方法是,會進入阻塞或輪詢狀態
-
concurrentHashMap
執行緒安全,支持高并發的操作,特點:效率比Hashtable高,并發性比hashmap好,結合了兩者的特點,(本文介紹的主角)
HashTable容器在競爭激烈的并發下表現出的效率低下的原因是所有訪問HashTable的執行緒都必須競爭同一把鎖,加入容器里有多把鎖,每一把鎖用于容器其中一部分資料,那么當多執行緒訪問容器里不同的資料段是,執行緒間就不會出現鎖競爭,從而可以有效的提高并發效率,將資料分成一段一段的存盤,然后給每一段分配一把鎖,當前程占用鎖訪問其中的一個段的資料的時候,其它的資料也能被其它的執行緒訪問
ConcurrentHashMap原理
ConcurrentHashMap 采用了分段鎖技術,其中 Segment 繼承于 ReentrantLock,
不會像 HashTable 那樣不管是 put 還是 get 操作都需要做同步處理,理論上 ConcurrentHashMap 支持 CurrencyLevel (Segment 陣列數量)的執行緒并發,
每當一個執行緒占用鎖訪問一個 Segment 時,不會影響到其他的 Segment,
ConcurrentHashMap和Hashtable主要區別就是圍繞著鎖的粒度以及如何鎖,可以簡單理解成把一個大的HashTable分解成多個,形成了鎖分離,
而Hashtable的實作方式是—鎖整個hash表,
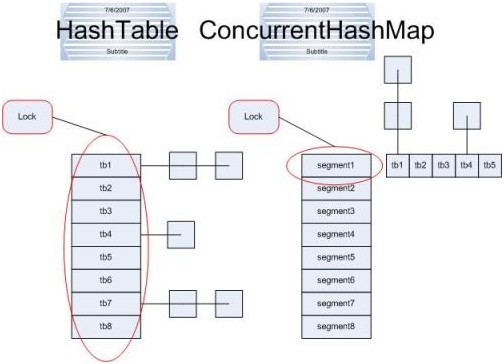
(圖片來源于網路)
走進原始碼:
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
//不允許 key或value為null
if (key == null || value == null) throw new NullPointerException();
//計算hash值
int hash = spread(key.hashCode());
int binCount = 0;
//死回圈 何時插入成功 何時跳出
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果table為空的話,初始化table
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//根據hash值計算出在table里面的位置
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//如果這個位置沒有值 ,直接放進去,不需要加鎖
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//當遇到表連接點時,需要進行整合表的操作
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//結點上鎖 這里的結點可以理解為hash值相同組成的鏈表的頭結點
synchronized (f) {
if (tabAt(tab, i) == f) {
//fh〉0 說明這個節點是一個鏈表的節點 不是樹的節點
if (fh >= 0) {
binCount = 1;
//在這里遍歷鏈表所有的結點
for (Node<K,V> e = f;; ++binCount) {
K ek;
//如果hash值和key值相同 則修改對應結點的value值
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//如果遍歷到了最后一個結點,那么就證明新的節點需要插入 就把它插入在鏈表尾部
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//如果這個節點是樹節點,就按照樹的方式插入值
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//如果鏈表長度已經達到臨界值8 就需要把鏈表轉換為樹結構
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//將當前ConcurrentHashMap的元素數量+1
addCount(1L, binCount);
return null;
}
ConcurrentHashMap的put方法和HashMap的邏輯差不多,主要是新增了執行緒安全部分,在添加元素時候,采用synchronized來保證執行緒安全,然后計算size的時候采用CAS操作進行計算,put流程小結:
1.判斷key和vaule是否為空,如果為空,直接拋出例外,
2.判斷table陣列是否已經初始化完畢,如果沒有初始化,進行初始化,
3.計算key的hash值,如果該位置為空,直接構造節點放入,
4.如果table正在擴容,進入幫助擴容方法,
5.最后開啟同步鎖,進行插入操作,如果開啟了覆寫選項,直接覆寫,否則,構造節點添加到尾部,如果節點數超過紅黑樹閾值,進行紅黑樹轉換,如果當前節點是樹節點,進行樹插入操作,
6.最后統計size大小,并計算是否需要擴容,
總結
JDK6,7中的ConcurrentHashmap主要使用Segment來實作減小鎖粒度,把HashMap分割成若干個Segment,在put的時候需要鎖住Segment,get時候不加鎖,使用volatile來保證可見性,當要統計全域時(比如size),首先會嘗試多次計算modcount來確定,這幾次嘗試中,是否有其他執行緒進行了修改操作,如果沒有,則直接回傳size,如果有,則需要依次鎖住所有的Segment來計算,
最后,回答開頭的問題,
我的研究結果是:執行緒安全,因為通過put原始碼分析,在插入資料時用了同步鎖synchronized,
對于趕時間的面試官來說,是還是不是,就夠了,至于為什么,想擴展什么的根據情況再說,但是我們自己得知道問題的背后以及是否觸及到你的知識的盲區,這也是本文總結的動機由來,
如有不足之處,歡迎PK,畢竟,知識無邊界,我們需要多個角度看世界,
參考資料:
1.多執行緒為什么要用ConcurrentHashMap
2.ConcurrentHashMap總結
3.ConcurrentHashMap的實作 get put remove 詳解
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/160258.html
標籤:其他
上一篇:Java~多執行緒關鍵字volatile和synchronized的特性比較
下一篇:隨便地記一下初次接觸爬蟲的嘗試