首先IEEE802.11g 標準的OFDM的幀結構如下所示:
關于802.11g,其基本的幀結構:

短訓練序列分為10段,每段長度為16個抽樣點;長訓練序列分為2段,每段長度為128個抽樣點,總長度為160+256個抽樣點,前導碼之后是head和資料部分,
然后之前,我不知道是我講錯了,還是你聽錯了,長訓練是精同步,短是粗同步,
所以就是基本的幀結構如下所示:
| 短訓練序列 | .... | 短訓練序列 | 保護 前綴 | 長訓練 序列 | 長訓練 序列 | 保護 前綴 | Head | Data |
我們這里進行仿真,將完整的將資料幀(發送多幀,進行同步,并對最后的幀頭位置輸出使能信號,說明鑒定到了幀資料資訊了,)
然后在長碼的前后兩端,加入保護前綴
上面就是我們這里使用的完整的幀結構,另外,這里你之前提供的程式只是做了相關,但沒有做相關的鑒定,所以,這里我們還增加了這個部分的程式,
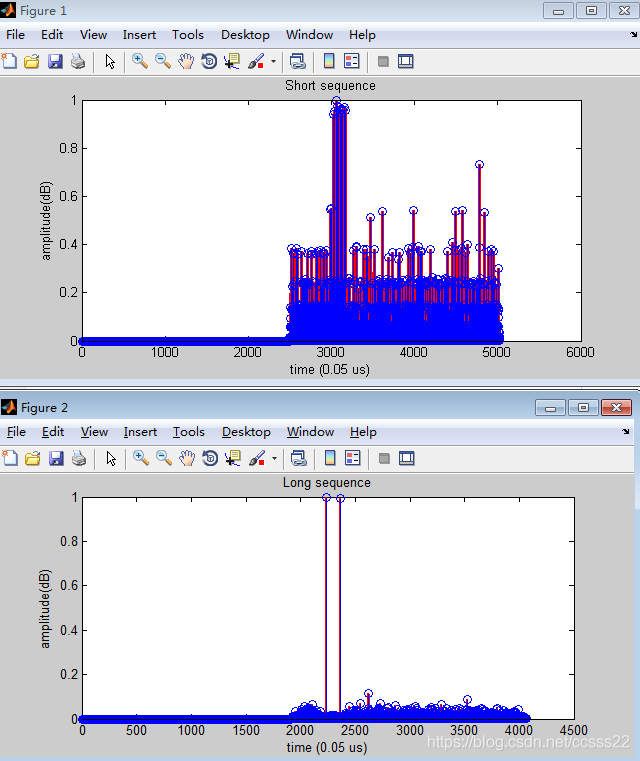
從上面的仿真結果可知,短序列 ,由于序列較短,可以快速的得到相關峰,但是由于其峰值較小,所以容易收到噪聲干擾,而長序列則相反,
下面簡單的介紹一下我們這個粗估計和精估計得程序:
步驟一:首先進行粗估計,這個時候系統對輸入的資料進行短序列相關,這里需要不斷的進行相關,直到找到短序列為止,我們在進行估計的時候(注意,如果一開始直接進行精估計,那么由于精估計序列長,所以在搜索的時候,將非常耗計算量)
在搜索到連續的相關峰值的時候,則認為找到了短序列的位置,根據OFDM幀結構,我們可以計算得到粗步估計下幀頭的位置,但是由于短序列容易收到噪聲的干擾,所以這個位置并不是準確的位置,一般會有幾個采樣點的偏差,這里我們轉入精估計
步驟二:假設由粗步估計得到幀頭位置為INDEX,然后我們開始以INDEX-32的位置開始精估計,這樣就節約了前面大量的搜索程序的計算了,然后以INDEX-32開始搜索,精估計,這個時候會得到兩個相關峰的位置,我們取第二個位置,作為幀頭計算位置,從而計算得到最后的幀頭INDEX0位置,
上面就是這個鑒定的程序,
然后簡單的介紹一下simulink模塊:
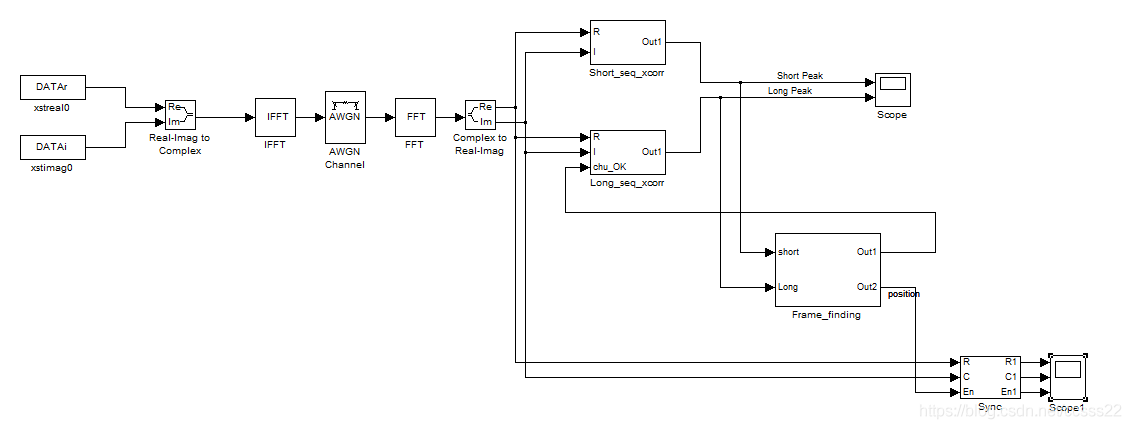
從左往右,各個模塊分別是資料加載模塊(這里,我們加載的資料是一段亂七八糟的隨機資料然后接著是三幀標準的OFDM信號,加入這個隨機的亂七八糟的資料目的是用來檢測功能的)
然后是是不虛部轉換為復數
然后是IFFT
然后是信道
然后是FFT
然后分別是短序列相關和長序列性感
然后是峰值檢測
最后顯示同步效果,
其中短序列通過檢測模塊,當短序列檢測到相關峰的時候,進行反饋,去檢測長序列,最后的效果如下所示:
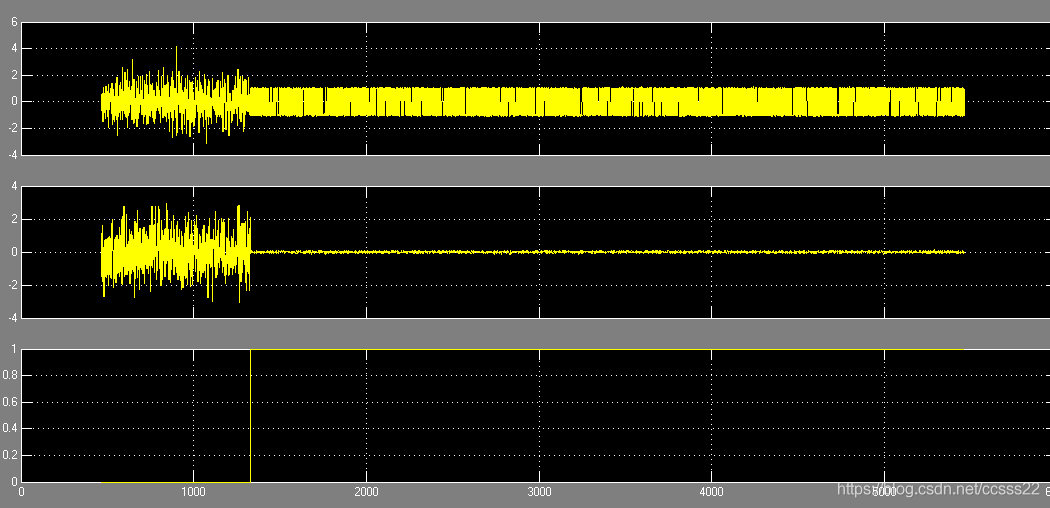
系統自動檢測好了幀的起始位置,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/161942.html
標籤:其他
上一篇:C++資訊編碼表示
下一篇:Maven白話講解