在近期的 Apache Kylin × Apache Hudi Meetup 直播上,Apache Kylin PMC Chair 史少鋒和 Kyligence 解決方案工程師劉永恒就 Hudi + Kylin 的準實時數倉實作進行了介紹與演示,下文是分享現場的回顧,
我的分享主題是《基于 Hudi 和 Kylin 構建準實時、高性能資料倉庫》,除了講義介紹,還安排了 Demo 實操環節,下面是今天的日程:
01 資料庫、資料倉庫
先從基本概念開始,我們都知道資料庫和資料倉庫,這兩個概念都已經非常普遍了,資料庫 Database,簡稱 DB,主要是做 OLTP(online transaction processing),也就是在線的交易,如增刪改;資料倉庫 Data Warehouse,簡稱 DW,主要是來做OLAP(online analytics processing),也就是在線資料分析,OLTP 的典型代表是 Oracle、MySQL,OLAP 則像 Teradata、Greenplum,近些年有 ClickHouse、Kylin 等,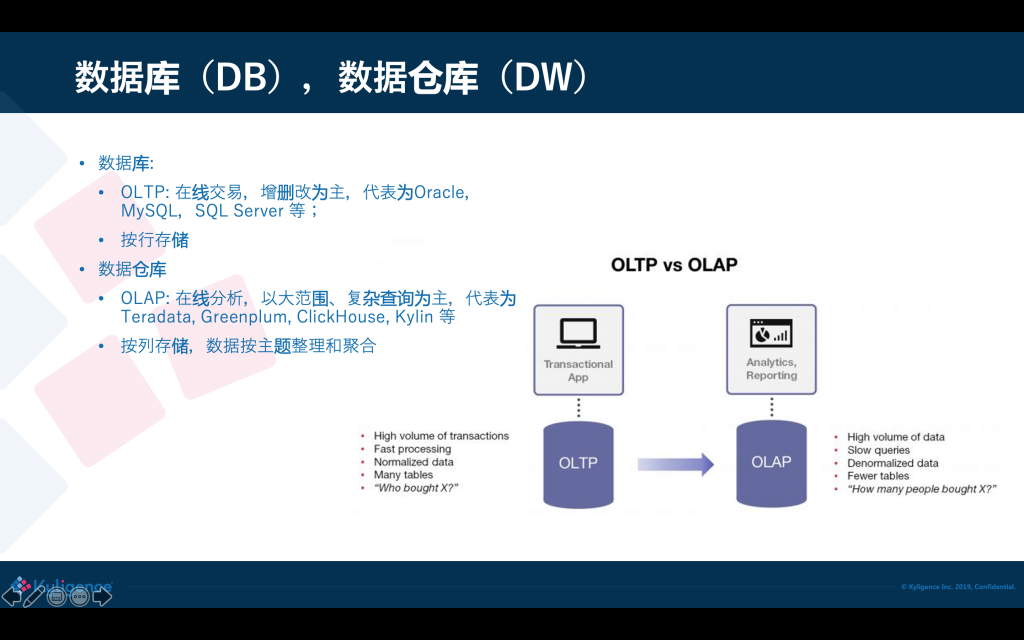 資料庫和資料倉庫兩者在存盤實作上是不一樣的,資料庫一般是按行存,這樣可以按行來增加、修改;資料倉庫是按列來存盤,是為了分析的時候可以高效訪問大量的資料,同時跳過不需要的列;這種存盤差異導致兩個系統難以統一,資料從資料庫進入到資料倉庫需要一條鏈路去處理,
資料庫和資料倉庫兩者在存盤實作上是不一樣的,資料庫一般是按行存,這樣可以按行來增加、修改;資料倉庫是按列來存盤,是為了分析的時候可以高效訪問大量的資料,同時跳過不需要的列;這種存盤差異導致兩個系統難以統一,資料從資料庫進入到資料倉庫需要一條鏈路去處理,
02 資料湖
近些年出現了資料湖(Data Lake)的概念,簡單來說資料湖可以存盤海量的、不同格式、匯總或者明細的資料,資料量可以達到 PB 到 EB 級別,企業不僅可以使用資料湖做分析,還可以用于未來的或未曾預判到的場景,因此需要的原始資料存盤量是非常大的,而且模式是不可預知的,資料湖產品典型的像 Hadoop 就是早期的資料湖了,現在云上有很多的資料湖產品,比方 Amazon S3,Azure Blob store,阿里云 OSS,以及各家云廠商都有自己的存盤服務,有了資料湖之后,企業大資料處理就有了一個基礎平臺,非常多的資料從源頭收集后都會先落到資料湖上,基于資料湖再處理和加載到不同的分析庫去,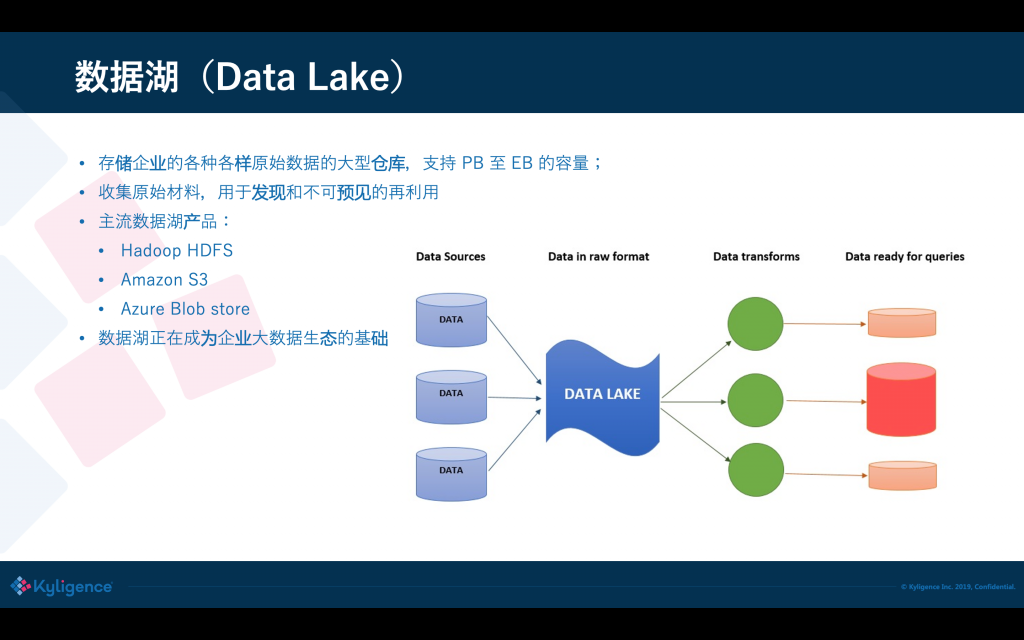
但是,資料湖開始設計主要是用于資料的存盤,解決的是容量的水平擴展性、資料的持久性和高可用性,沒有太多考慮資料的更新和洗掉,例如 HDFS 上通常是將檔案分塊(block)存盤,一個 block 通常一兩百兆;S3 同樣也是類似,大的 block 可以節省管理開銷,并且這些檔案格式不一,通常沒有高效的索引,如果要修改檔案中的某一行記錄,對于資料湖來說是非常難操作的,因為它不知道要修改的記錄在哪個檔案的哪個位置,它提供的方式僅僅是做批量替換,代價比較大,
 另外一個極端的存盤則是像 HBase 這樣的,提供高效的主鍵索引,基于主鍵就可以做到非常快的插入、修改和洗掉;但是 HBase 在大范圍讀的效率比較低,因為它不是真正的列式存盤,對于用戶來說面臨這么兩個極端:一邊是非常快的讀存盤(HDFS/S3),一邊是非常快速的寫存盤;如果取中間的均衡比較困難,有的時候卻需要有一種位于兩者之間的方案:讀的效率要高,但寫開銷不要那么大,
另外一個極端的存盤則是像 HBase 這樣的,提供高效的主鍵索引,基于主鍵就可以做到非常快的插入、修改和洗掉;但是 HBase 在大范圍讀的效率比較低,因為它不是真正的列式存盤,對于用戶來說面臨這么兩個極端:一邊是非常快的讀存盤(HDFS/S3),一邊是非常快速的寫存盤;如果取中間的均衡比較困難,有的時候卻需要有一種位于兩者之間的方案:讀的效率要高,但寫開銷不要那么大,
03 資料倉庫的加載鏈路
在有這么一個方案之前,我們怎樣能夠支撐到資料的修改從 OLTP 到 OLAP 之間準實時同步呢?通常大家會想到,通過 CDC/binlog 把修改增量發出來,但 binlog 怎么樣進入到 Hive 中去呢?我們知道 Hive 很難很快地修改一條記錄,修改只能把整張表或者整個磁區重新寫一遍,為了接收和準實時消費 binlog,可能需要引入一個只讀的 Database 或 MPP 資料庫,專門復制上游業務庫的修改;然后再從這個中間的資料庫匯出資料到資料湖上,供下一個階段使用,這個方案可以減少對業務庫的壓力和影響,但依然存在一些問題,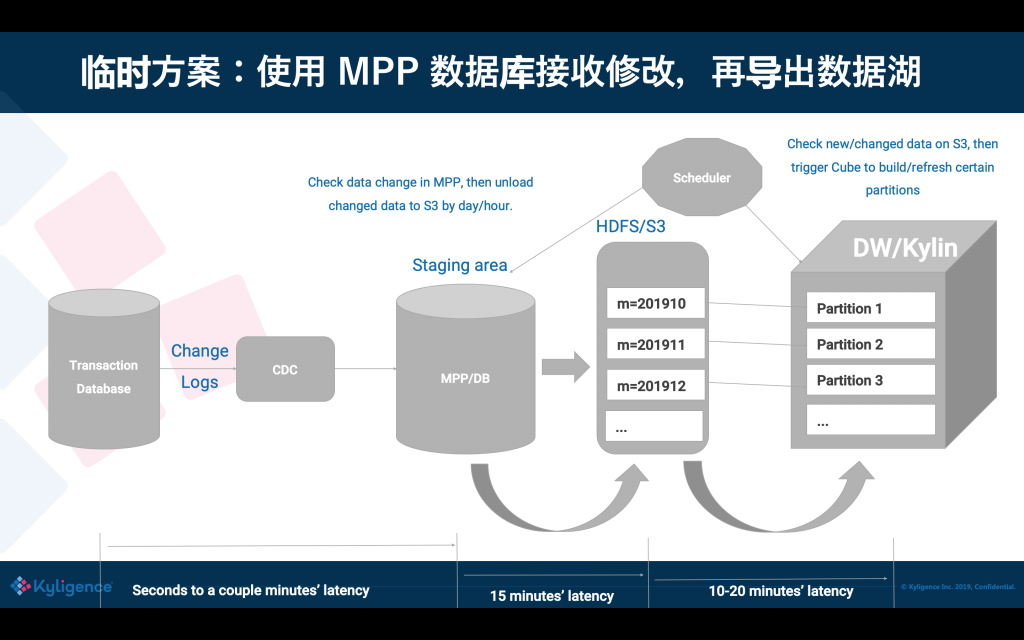
這里有一個生動的例子,是前不久從一個朋友那里看到的,各位可以感受一下,
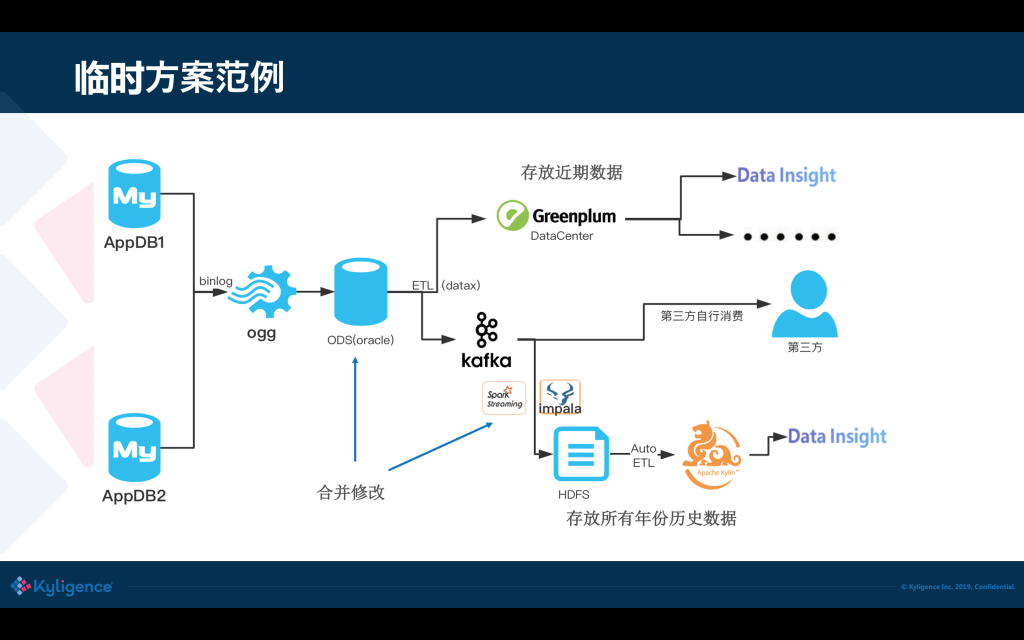
可以看到在過去的方案是非常復雜的,又要用 MPP 又要用資料湖,還要用 Kylin,在這中間資料頻繁的被匯出匯入,浪費是非常嚴重的,而且維護成本高,容易出錯,因為資料湖和資料庫之間的檔案格式往往還存在兼容性問題,
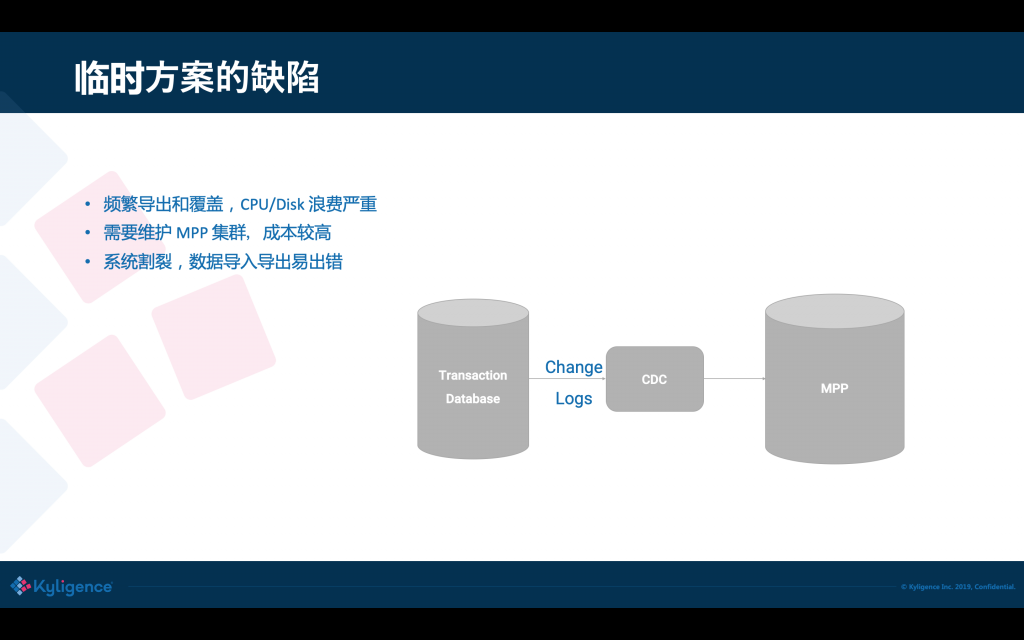
04 Hudi:新一代資料湖專案
后來我們注意到 Hudi 這個專案,它的目的就是要在大資料集上支持 Upsert(update+insert),Hudi 是在大資料存盤上的一個資料集,可以將 Change Logs 通過 upsert 的方式合并進 Hudi;Hudi 對上可以暴露成一個普通的 Hive 或 Spark 的表,通過 API 或命令列可以獲取到增量修改的資訊,繼續供下游消費;Hudi 還保管了修改歷史,可以做時間旅行或回退;Hudi 內部有主鍵到檔案級的索引,默認是記錄到檔案的布隆過濾器,高級的有存盤到 HBase 索引提供更高的效率,
05 基于 Hudi+Kylin 的準實時數倉實作
有了 Hudi 之后,可以跳過使用中間資料庫或 MPP,直接微批次地增量消費 binlog,然后插入到 Hudi;Hudi 內的檔案直接存放到 HDFS/S3 上,對用戶來說存盤成本可以大大降低,不需要使用昂貴的本地存盤,Hudi 表可以暴露成一張 Hive 表,這對 Kylin 來說是非常友好,可以讓 Kylin 把 Hudi 當一張普通表,從而無縫使用,Hudi 也讓我們更容易地知道,從上次消費后有哪些 partition 發生了修改,這樣 Kylin 只要重繪特定的 partition 就可以,從而端到端的資料入庫的延遲可以降低到1小時以內,從 Uber 多年的經驗來說,對大資料的統計分析,入庫小于 1 小時在大多數場景下都是可以接受的,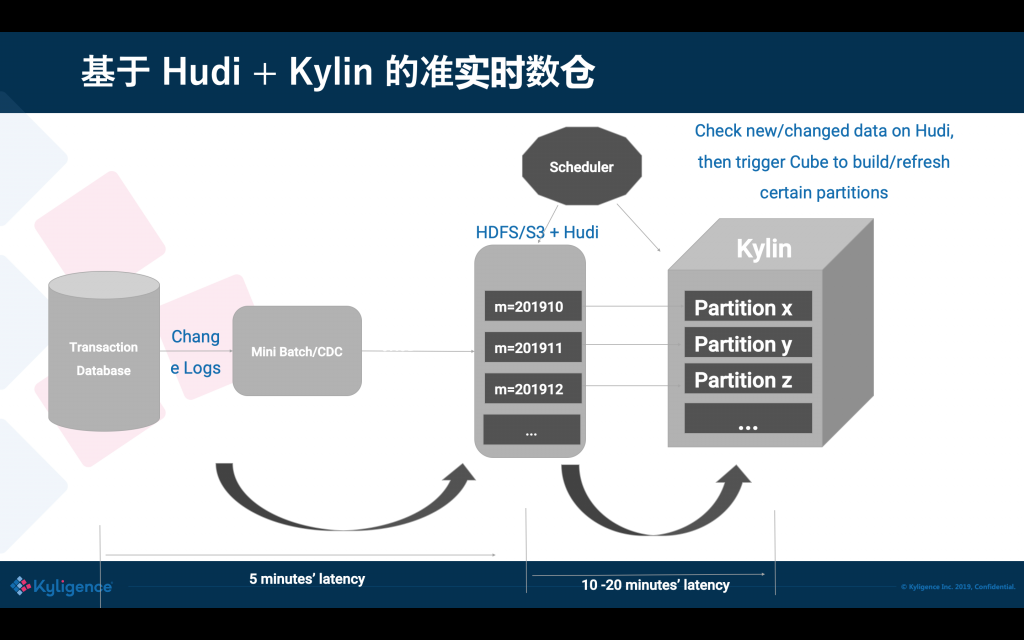
這里再總結一下,使用 Hudi 來做 DW 資料加載的前置存盤給我們帶來的諸多的好處:首先,它可以支持準實時的插入、修改和洗掉,對保護用戶資料隱私來說是非常關鍵的(例如 GDPR );它還可以控制小檔案,減少對 HDFS 的壓力;第二,Hudi 提供了多種訪問視圖,可以根據需要去選擇不同的視圖;第三,Hudi 是基于開放生態的,存盤格式使用 Parquet 和 Avro,目前主要是使用 Spark 來做資料操作,未來也可以擴展;支持多種查詢引擎,所以在生態友好性上來說,Hudi 是遠遠優于另外幾個競品的,

06 使用 Kyligence Cloud 現場演示
前面是一個基本的介紹,接下來我們做一個 Live Demo,用到 Kyligence Cloud(基于 Kylin 內核)這個云上的大資料分析平臺;你可以一鍵在 Azure/AWS 上來啟動分析集群,內置多種大資料組件來做建模加速,可直接從云上存盤或云上的資料庫抽取資料,提供了自動的監控和運維,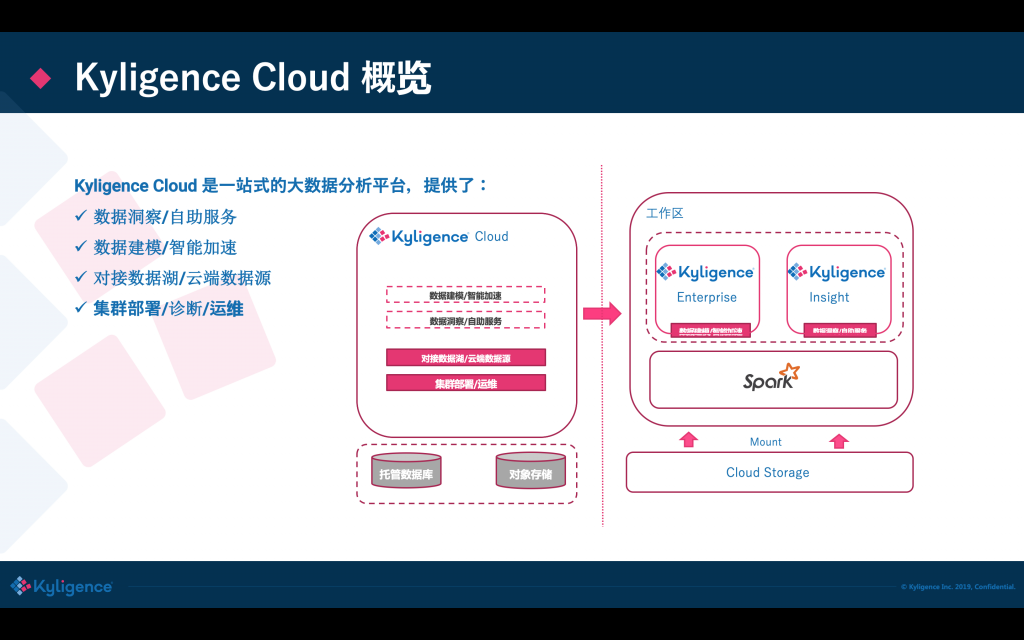
目前 Kyligence Cloud 已經不需要依賴 Hadoop 了,直接使用 VM 來做集群的計算力,內置了 Spark 做分布式計算,使用 S3 做資料存盤;還集成了 Kylignece Insight 做可視化分析,底層可以對接常見的資料源,也包括 Hudi,在最新發布版的 Hudi 已經被集成進來了,
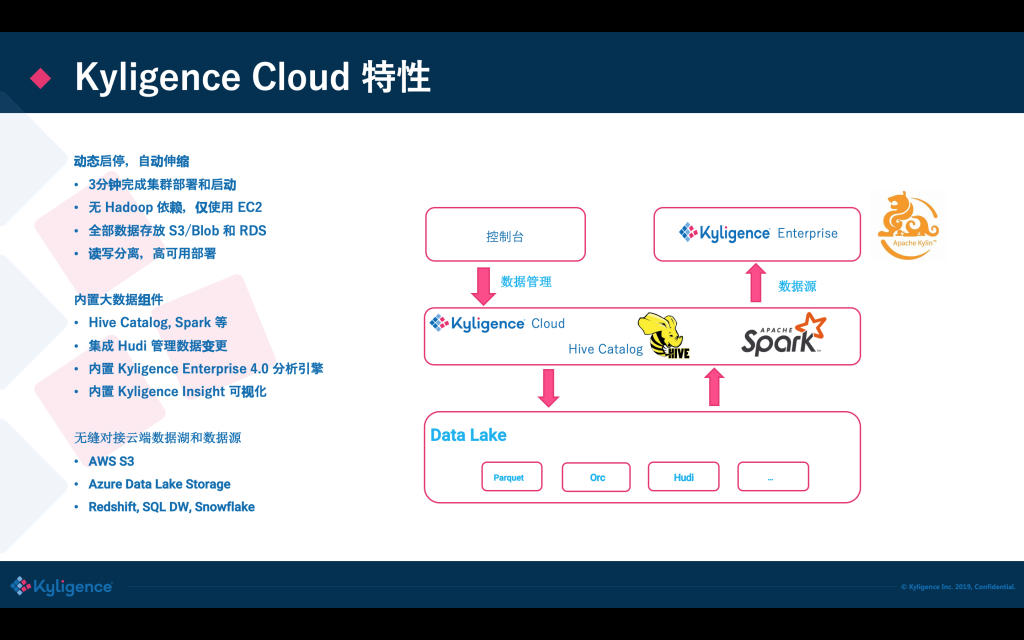
接下來,劉永恒將帶來 Live Demo,他是從業務庫到處資料加載到 Hudi 中,然后 Hudi 隨后就可以從這當中來被訪問,接下來他會演示做一些資料修改,再把這個資料修改合并到 Hudi,在 Hudi 中就可以看到這些資料的改變,接下來的時間就交給劉永恒,
 想了解劉永恒老師的 Demo 詳情?請點擊播放下方現場回顧視頻,拖動進度條至 19:50 的位置,即可開始觀看:
https://v.qq.com/x/page/l0935oplxeh.html
了解更多大資料資訊,點擊進入Kyligence官網
想了解劉永恒老師的 Demo 詳情?請點擊播放下方現場回顧視頻,拖動進度條至 19:50 的位置,即可開始觀看:
https://v.qq.com/x/page/l0935oplxeh.html
了解更多大資料資訊,點擊進入Kyligence官網
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/16340.html
標籤:大數據
上一篇:求大佬們出出主意