我們需要接受失望,因為它是有限的;我們不會失去希望,因為它是無窮的,
一、概述
隨著時間和業務的發展,資料庫中表的資料量會越來越大,相應地,資料操作,增刪改查的開銷也會越來越大,因此,把其中一些大表進行拆分到多個資料庫中的多張表中,
本篇文章是基于非事務訊息的異步確保的方式來完成分庫分表中的事務問題,
二、需要解決問題
2.1 原有事務
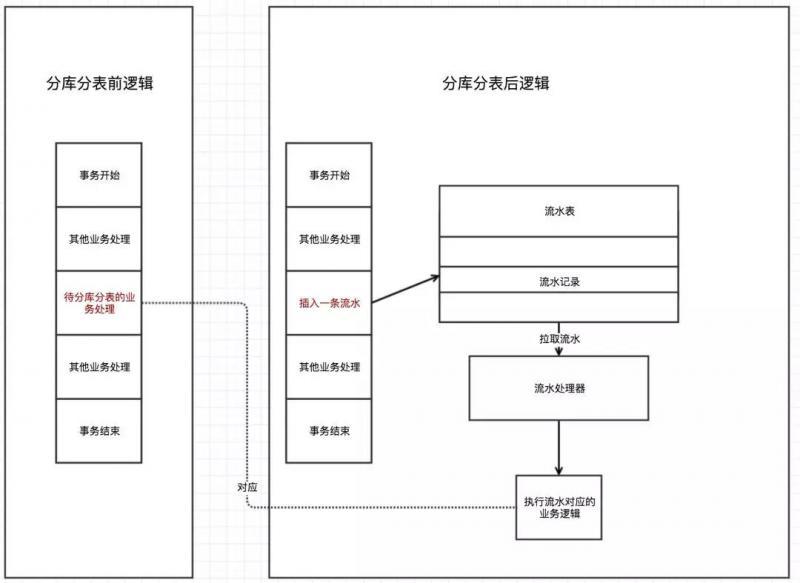
由于分庫分表之后,新表在另外一個資料庫中,如何保證主庫和分庫的事務性是必須要解決的問題,
解決辦法:通過在主庫中創建一個流水表,把操作資料庫的邏輯映射為一條流水記錄,當整個大事務執行完畢后(流水被插入到流水表),然后通過其他方式來執行這段流水,保證最終一致性,
2.2 流水
所謂流水,可以理解為一條事務訊息
上面通過在資料庫中創建一張流水表,使用一條流水記錄代表一個業務處理邏輯,因此,一個流水一定是能最終正確執行的.因此,當把一段業務代碼提取流水中必須要考慮到:
-
流水延遲處理性,流水不是實時處理的,而是用過流水執行器來異步執行的,因此,如果在原有邏輯中,需要特別注意后續流程對該流水是不是有實時依賴性(例如后續業務邏輯中會使用流水結果來做一些計算等),
-
流水處理無序性,保證即使后生成的流水先執行,也不能出現問題,
-
流水最終成功性,對每條插入的流水,該條流水一定要保證能執行成功
因此,提取流水的時候:
-
流水處理越簡單越好
-
流失處理依賴越少越好
-
提取的流水在該業務邏輯中無實時性依賴
2.4 流水處理完成
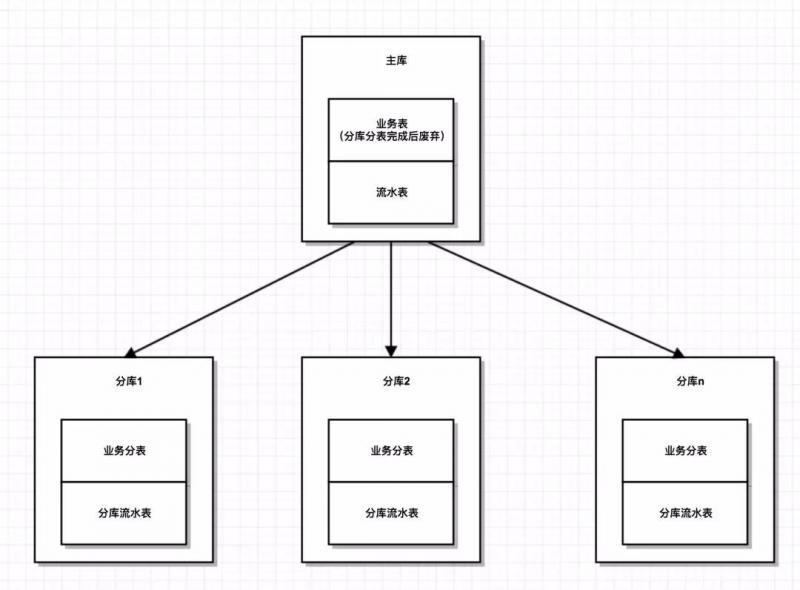
因為流水表是放在原資料庫中,而流水處理完成后是操作分庫,如果分庫操作完成去更新老表流水訊息,那么又是夸庫事務,如何保證流水狀態的更新和分庫也是在一個事務的?
解決辦法是:在分庫中創建一個流水表,當流失處理完成以后,不是去更新老表狀態,而是插入分庫流水表中、
這樣做的好處:
-
一般會對流水做唯一索引,那么如果流水重復多次執行的時候,插入分庫流水表的時候肯定由于唯一索引檢測不通過,整個事務就會回滾(當然也可以在處理流水事前應該再做一下冪等性判斷)
-
這樣通過判斷主庫流水是否在分庫中就能判斷一條流水是否執行完畢
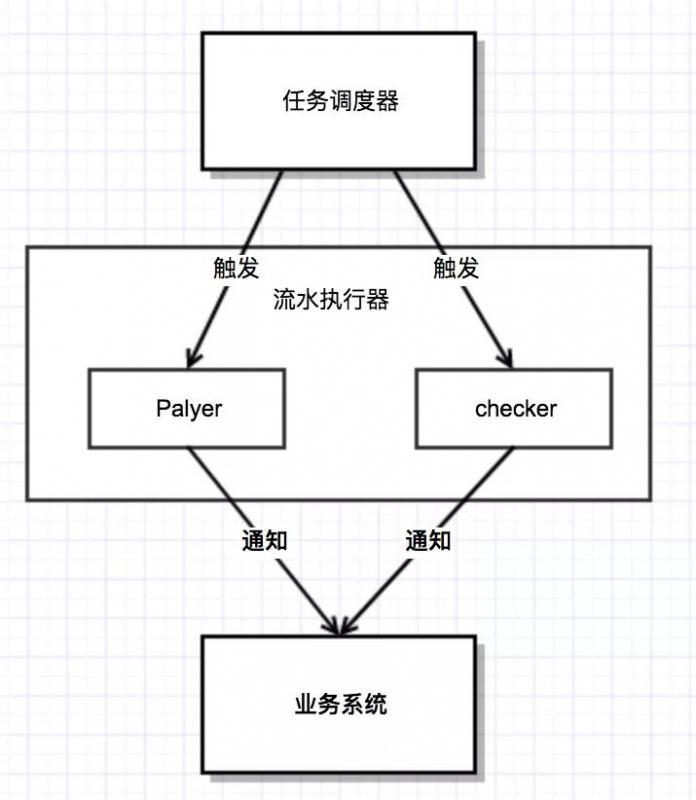
三、流水處理器基本框架
流水處理器其實不包含任何業務相關的處理邏輯,核心功能就是:
-
通知業務接入方何時處理什么樣的流水
-
檢驗流水執行的成功
注:流水執行器并不知道該流水表示什么邏輯,具體需要業務系統去識別后去執行相對應業務邏輯,
3.1 流水執行任務
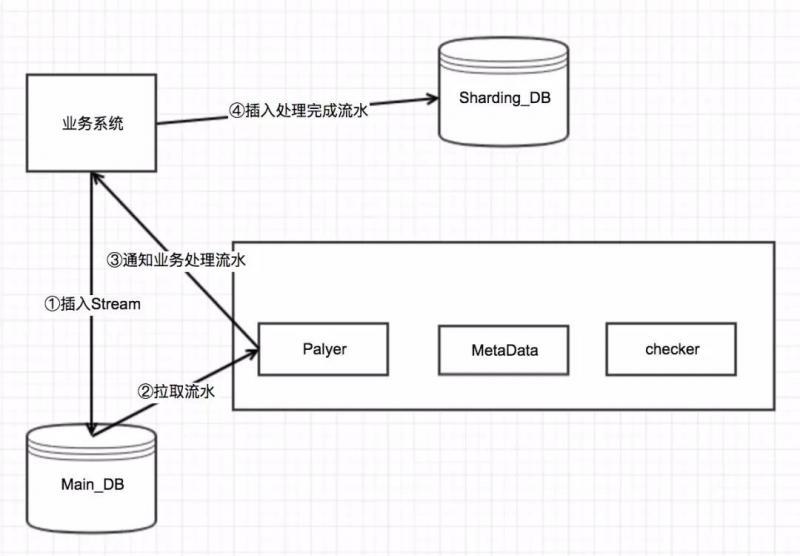
流水處理調度任務就是通過掃描待處理的流水,然后通知業務系統該執行哪一條流水,
示意圖如下:
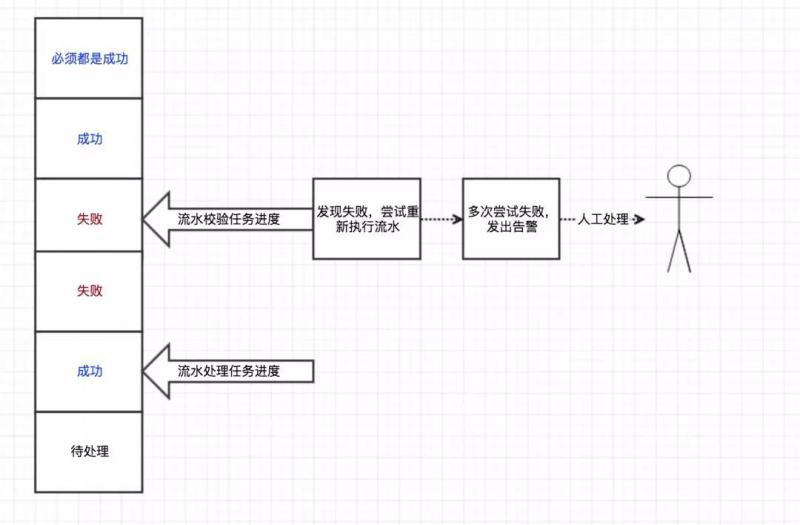
3.2 流水校驗任務
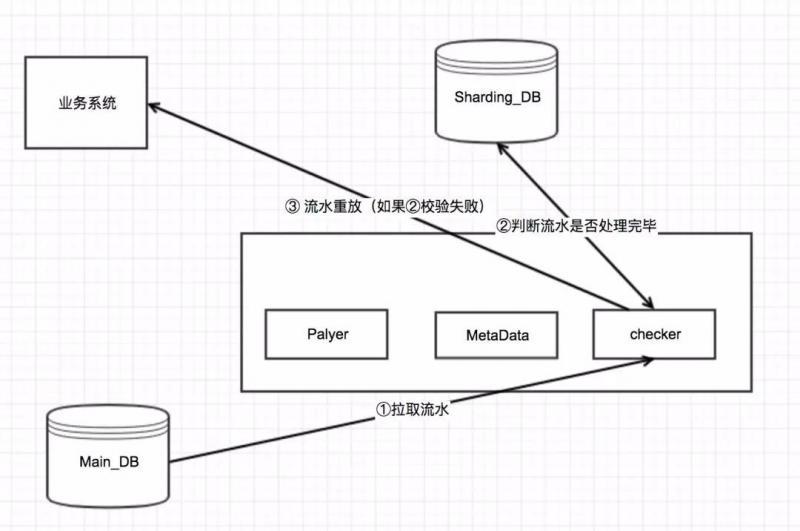
流水校驗任務就是要比較主庫和分庫中的流水記錄,對執行未成功的流水通知業務系統進行重新處理,如果多次重試失敗則發出告警,
流程示意圖:
四、為什么不用事務訊息
由于是既有專案(互聯網金融,所以是絕對不容忍有任何訊息丟失或者訊息處理失敗)進行改造,不使用事務訊息有1個原因
-
需要額外引入訊息佇列,增加系統的復雜度,而且也需要額外的邏輯保證和訊息佇列通訊失敗的時候處理
-
其實1不算是主要原因,而是因為事務訊息需要手動的commit和rollback(使用資料庫不需要),那么問題來了,spring中事務是有傳遞性的,那我們事務訊息何時提交又是個大問題,例如 A.a()本來就是一個事務, 但是另外一個事務B.b()中又呼叫了A.a() 那事務訊息提交是放在A.a()還是B.b()中呢?
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/16386.html
標籤:MySQL
上一篇:請問有沒有存盤SQL腳本的工具啊