索引是什么?
索引類似大學圖書館建書目索引,可以提高資料檢索的效率,降低資料庫的IO成本,MySQL在300萬條記錄左右性能開始逐漸下降,雖然官方檔案說500~800w記錄,所以大資料量建立索引是非常有必要的,
索引型別及創建
主鍵索引
主鍵索引是一種特殊的唯一索引,一個表只能有一個主鍵,不允許有空值,一般是在建表的時候同時創建主鍵索引:
CREATE TABLEtable(idint(11) NOT NULL AUTO_INCREMENT ,titlechar(255) NOT NULL , PRIMARY KEY (id));
普通索引
這是最基本的索引,它沒有任何限制
直接創建索引
CREATE INDEX index_name ON table(column(length))
修改表結構的方式添加索引
ALTER TABLE table_name ADD INDEX index_name ON (column(length))
創建表的時候同時創建索引
CREATE TABLEtable(idint(11) NOT NULL AUTO_INCREMENT ,titlechar(255) CHARACTER NOT NULL ,contenttext CHARACTER NULL ,timeint(10) NULL DEFAULT NULL , PRIMARY KEY (id), INDEX index_name (title(length)))
組合索引(復合索引)
指多個欄位上創建的索引,只有在查詢條件中使用了創建索引時的第一個欄位,索引才會被使用,使用組合索引時遵循最左前綴集合 索引第一個欄位唯一值越多越好 (離散度)
如何判斷離散度: select count( distinct id ) from A
ALTER TABLEtableADD INDEX name_city_age (name,city,age);
唯一索引
與普通索引類似,不同的就是:索引列的值必須唯一,但允許有空值,如果是組合索引,則列值的組合必須唯一,它有以下幾種創建方式:
創建唯一索引
CREATE UNIQUE INDEX indexName ON table(column(length))
修改表結構
ALTER TABLE table_name ADD UNIQUE indexName ON (column(length))
創建表的時候直接指定
CREATE TABLEtable(idint(11) NOT NULL AUTO_INCREMENT ,titlechar(255) CHARACTER NOT NULL ,contenttext CHARACTER NULL ,timeint(10) NULL DEFAULT NULL , UNIQUE indexName (title(length)));
全文索引
主要用來查找文本中的關鍵字,而不是直接與索引中的值相比較,fulltext索引跟其它索引大不相同,它更像是一個搜索引擎,而不是簡單的where陳述句的引數匹配,fulltext索引配合match against操作使用,而不是一般的where陳述句加like,它可以在create table,alter table ,create index使用,不過目前只有char、varchar,text 列上可以創建全文索引,值得一提的是,在資料量較大時候,現將資料放入一個沒有全域索引的表中,然后再用CREATE index創建fulltext索引,要比先為一張表建立fulltext然后再將資料寫入的速度快很多,
CREATE TABLEtable(idint(11) NOT NULL AUTO_INCREMENT ,titlechar(255) CHARACTER NOT NULL ,contenttext CHARACTER NULL ,timeint(10) NULL DEFAULT NULL , PRIMARY KEY (id), FULLTEXT (content));
索引的優缺點
以上介紹了索引型別 也介紹了索引會增加 資料檢索的效率,降低資料庫的IO成本 ,但是 是索引越多越好嗎?如果一張表所有欄位都創建了索引 會怎么樣?
優點
可以大大加快資料的檢索速度,這也是創建索引的最主要的原因,通過使用索引,可以在查詢的程序中,使用優化隱藏器,提高系統的性能,
缺點
創建索引和維護索引要耗費時間,具體地,當對表中的資料進行增加、洗掉和修改的時候,索引也要動態的維護,會降低增/改/刪的執行效率;占用物理空間,
如何正確創建索引
盡量使用自增長主鍵
首先能有效減少頁分裂,MySQL中資料是以頁為單位存盤的且每個頁的大小是固定的(默認16kb),如果一個資料頁的資料滿了,則需要分成兩個頁來存盤,這個程序就叫做頁分裂,
如果使用了自增主鍵的話,新插入的資料都會盡量的往一個資料頁中寫,寫滿了之后再申請一個新的資料頁寫即可(大多數情況下不需要分裂,除非父節點的容量也滿了),
選擇性高的列優先
在創建索引的時候通常要求將選擇性高的列放在最前面,對于選擇性不高的列甚至可以不創建索引,如果選擇性不高,極端性情況下可能會掃描全部或者大多數索引,然后再回表,這個程序可能不如直接走主鍵索引性能高,
索引列的選擇往往需要根據具體的業務場景來選擇,但是需要注意的是索引的區分度越高則價值就越高,意味著對于檢索的性價比就高,索引的區分度等于count(distinct 具體的列) / count(*),表示欄位不重復的比例,(例如TYPE 值 1 2 3 索引意義不大)
聯合索引優先于多列獨立索引
聯合索引優先于多列獨立索引, 假設有三個欄位a,b,c, 索引(a)(a,b),(a,b,c)可以使用(a,b,c)代替,MySQL中的索引并不是越多越好,各個公司的規定中往往會限制單表中的索引的個數,原因在于,索引本身也會占用一定的空間,并且維護一個索引時有一定的代碼的,所以在滿足需求的情況下一定要盡可能創建更少的索引,
覆寫索引避免回表 (使用聯合索引會出現)
覆寫索引如果執行的陳述句是 select ID from T where k between 3 and 5,這時只需要查 ID 的值,而 ID 的值已經在 k 索引樹上了,因此可以直接提供查詢結果,不需要回表,也就是說,在這個查詢里面,索引 k 已經“覆寫了”我們的查詢需求,我們稱為覆寫索引,由于覆寫索引可以減少樹的搜索次數,顯著提升查詢性能,所以使用覆寫索引是一個常用的性能優化手段,
覆寫索引的查詢優化
覆寫索引同時還會影響索引的選擇,對于(a,b,c)索引來說,理論上來說不滿足最左匹配原則,但是實際上也會走索引,原因在于,優化器認為(a,b,c)索引的性能會高于全表掃描,實際情況也是這樣的,感興趣的小伙伴不妨分析一下上文中介紹的資料結構,
explain select a,b,c from test_table where b = “188466668888” and c = “23”;

滿足查詢和排序
索引要滿足查詢和排序,大部分同學在創建索引時,通常第一反應是查詢條件來選擇索引列,需要注意的是查詢和排序同樣重要,我們建立的索引要同時滿足查詢和排序的需求.
包含要排序的列
select c, d from test_table where a = 1 and b = 2 order by c;
雖然查詢條件只使用了a,b兩個欄位,但是由于排序用到了c欄位,我們能可以建立(a,b,c)聯合索引來進行優化,
保證索引欄位順序
如上文中的介紹,索引的欄位順序決定了索引資料的組織順序,要想更高性能的檢索資料,一定要盡可能的借助底層資料結構的特點來進行,如,索引(a, b)的默認組織形式就是先根據a排序,在a相同的情況下再根據b排序,
考慮索引的大小
記憶體中的空間十分寶貴,而索引往往又需要在記憶體中,為了在有限的記憶體中存盤更多的索引,在設計索引時往往要考慮索引的大小,比如我們常用的郵箱,xxxx@xx.com, 假設都是abc公司的,則郵箱后綴完全一致為@abc.com, 索引的區分度完全取決于@前面的字串,
>針對上述情況,MySQL 是支持前綴索引的,也就是說,你可以定義字串的一部分作為索引,默認地,如果你創建索引的陳述句不指定前綴長度,那么索引就會包含整個字串,(如何創建 alter table x_test add index(x_name(1)))
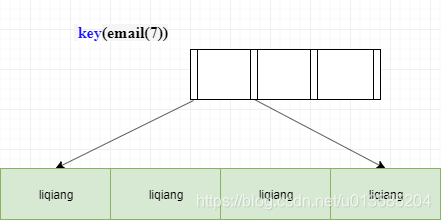
如果使用的 email 整個字串的索引結構執行順序是這樣的:從 index1 索引樹找到滿足索引值是’liqiang156@11.com’的這條記錄,取得 id (主鍵)的值ID2;到主鍵上查到主鍵值是ID2的行,將這行記錄加入結果集;
取 email 索引樹上剛剛查到的位置的下一條記錄,發現已經不滿足 email='liqiang156@qq.com’的條件了,回圈結束,這個程序中,只需要回主鍵索引取一次資料,所以系統認為只掃描了一行,但是它的問題就是索引的后半部分都是重復的,浪費記憶體,
這時我們可以考慮使用前綴索引,如果使用的是 index2 (email(7) 索引結構),執行順序是這樣的:從 index2 索引樹找到滿足索引值是’liqiang’的記錄,找到的第一個是 ID1,到主鍵上查到主鍵值是 ID1 的行,判斷出 email 的值是’liqiang156@xxx.com’,加入結果集,
取 index2 上剛剛查到的位置的下一條記錄,發現仍然是’liqiang’,取出 ID2,再到 ID 索引上取整行然后判斷,這次值仍然不對,則丟棄繼續往下取,
重復上一步,直到在 index2 上取到的值不是’liqiang’或者索引搜索完畢之后,回圈結束,在這個程序中,要回主鍵索引取 4 次資料,也就是掃描了 4 行,通過這個對比,你很容易就可以發現,使用前綴索引后,可能會導致查詢陳述句讀資料的次數變多,
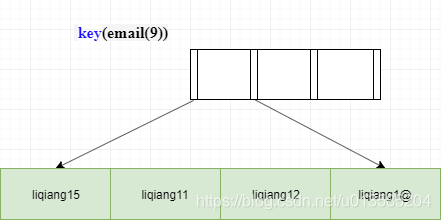
不過方法總比困難多,我們在建立索引時可以先通過陳述句查看一下索引的區分度,或者提前預估余下前綴長度,對于上述問題我們可以將前綴長度調整為9即可達到效果,索引,在使用前綴索引時,一定要充分考慮資料的特征,選擇合適的
對于一些比較長的欄位的等值查詢,我們也可以采用其他方式來縮短索引的長度,比如url一般都是比較長,我們可以冗余一列存盤其Hash值,
select field_list from t where id_card_crc=crc32(‘input_id_card_string’) and id_card=‘input_id_card_string’
對于我們國家的身份證號,一共 18 位,其中前 6 位是地址碼,所以同一個縣的人的身份證號前 6 位一般會是相同的,為了提高區分度,我們可以將身份證號碼倒序存盤,
select field_list from t where id_card = reverse(‘input_id_card_string’);
如何正確使用索引
不在索引上進行任何操作
索引上進行計算,函式,型別轉換等操作都會導致索引從當前位置(聯合索引多個欄位,不影響前面欄位的匹配)失效,可能會進行全表掃描,
對于需要計算的欄位,則一定要將計算方法放在“=”后面,否則會破壞索引的匹配,目前來說MySQL優化器不能對此進行優化,
隱式型別轉換
需要注意的是,在查詢時一定要注意欄位型別問題,比如a欄位時字串型別的,而匹配引數用的是int型別,此時就會發生隱式型別轉換,相當于相當于在索引上使用函式,
只查詢需要的列
在日常開發中很多同學習慣使用 select * … 來構建查詢陳述句,這種做法也是極不推薦的,主要原因有兩個,首先查詢無用的列在資料傳輸和決議系結程序中會增加網路IO,以及CPU的開銷,盡管往往這些消耗可以被忽略,但是我們也要避免埋坑,
其次就是會使得覆寫索引"失效", 這里的失效并非真正的不走索引,覆寫索引的本質就是在索引中包含所要查詢的欄位,而 select * 將使覆寫索引失去意義,仍然需要進行回表操作,畢竟索引通常不會包含所有的欄位,這一點很重要,
不等式條件
查詢陳述句中只要包含不等式,負向查詢一般都不會走索引,如 !=, <>, not in, not like等,
模糊匹配查詢
最左前綴在進行模糊匹配時,一般禁止使用%前導的查詢,如like “%zhangsan”,
最左匹配原則
索引是有順序的,查詢條件中缺失索引列之后的其他條件都不會走索引,比如(a, b, c)索引,只使用b, c索引,就不會走索引,
如果索引從中間斷開,索引會部分失效,這里的斷開指的是缺失該欄位的查詢條件,或者說滿足上述索引失效情況的任意一個,不過這里的仍然會使用到索引,只不過只能使用到索引的前半部分,
值得注意的是,如果使用了不等式查詢條件,會導致索引完全失效,而上一個例子中即使用了不等式條件,也使用了隱式型別轉換卻能用到索引,
同理,根據最左前綴匹配原則,以下如果使用b,c作為查詢條件則不會使用(a, b, c)索引,
下一章: B樹與B+樹
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/167412.html
標籤:其他
下一篇:用戶登錄案例實作