大家都知道redis默認是16個db,但是這些db底層的設計結構是什么樣的呢?
我們來簡單的看一下原始碼,重要的欄位都有所注釋
typedef struct redisDb {
dict *dict; /* The keyspace for this DB 字典資料結構,非常重要*/
dict *expires; /* Timeout of keys with a timeout set 過期時間*/
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) list一些資料結構中用到的阻塞api*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS 事務相關處理 */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
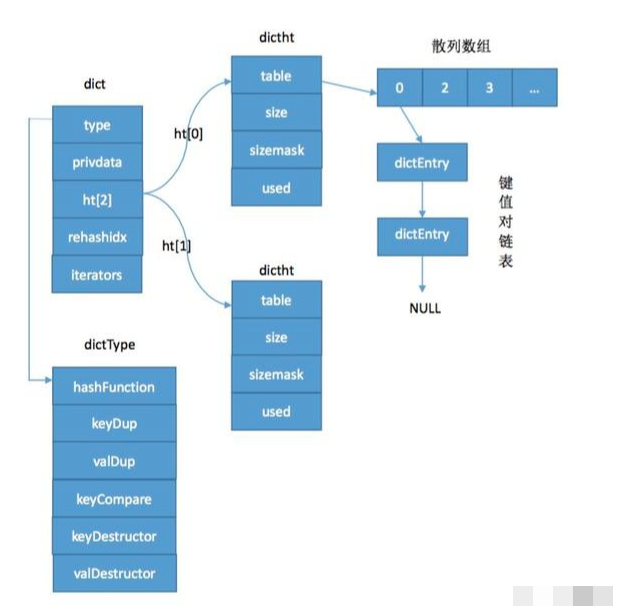
redis中的所有kv都是存放在dict中的,dict型別在redis中非常重要,
字典disc的資料結構如下
typedef struct dict {
dictType *type; //
void *privdata;
dictht ht[2]; //hashtable,每個dict都有兩個這樣的資料結構,主要用于hash擴容
long rehashidx; /* rehashing not in progress if rehashidx == -1 rehash的作用 防止鏈表無限增長*/
unsigned long iterators; /* number of iterators currently running 遍歷記錄的一些欄位*/
} dict;
redis中當出現hash沖突的時候,我們會采用頭插法(鏈表)的方式來解決,但是鏈表無限增常的話hashtable會退化,退化成一個鏈表,影響查詢效率,這個時候我們就需要對之前的陣列進行擴容,把老的資料搬到新陣列上面,這個程序就是rehash
接下來咱們來看看dictType的型別
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key); //key用于資料型別的復制
void *(*valDup)(void *privdata, const void *obj); //value用于資料型別的復制
int (*keyCompare)(void *privdata, const void *key1, const void *key2); //hash沖突的時候需要在沖突的值里面一個一個的對比
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
typedef struct dictht {
dictEntry **table; //指向陣列的首地址 是健值對的核心結構
unsigned long size;//陣列的長度
unsigned long sizemask; //恒等于size-1
unsigned long used;
} dictht;
typedef struct {
void *key; //指向SDS的資料結構
union { //聯合體表示value型別,只會用到一個欄位
void *val; //指向redis物件 redisObject
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; //頭插法解決hash沖突
} dictEntry;
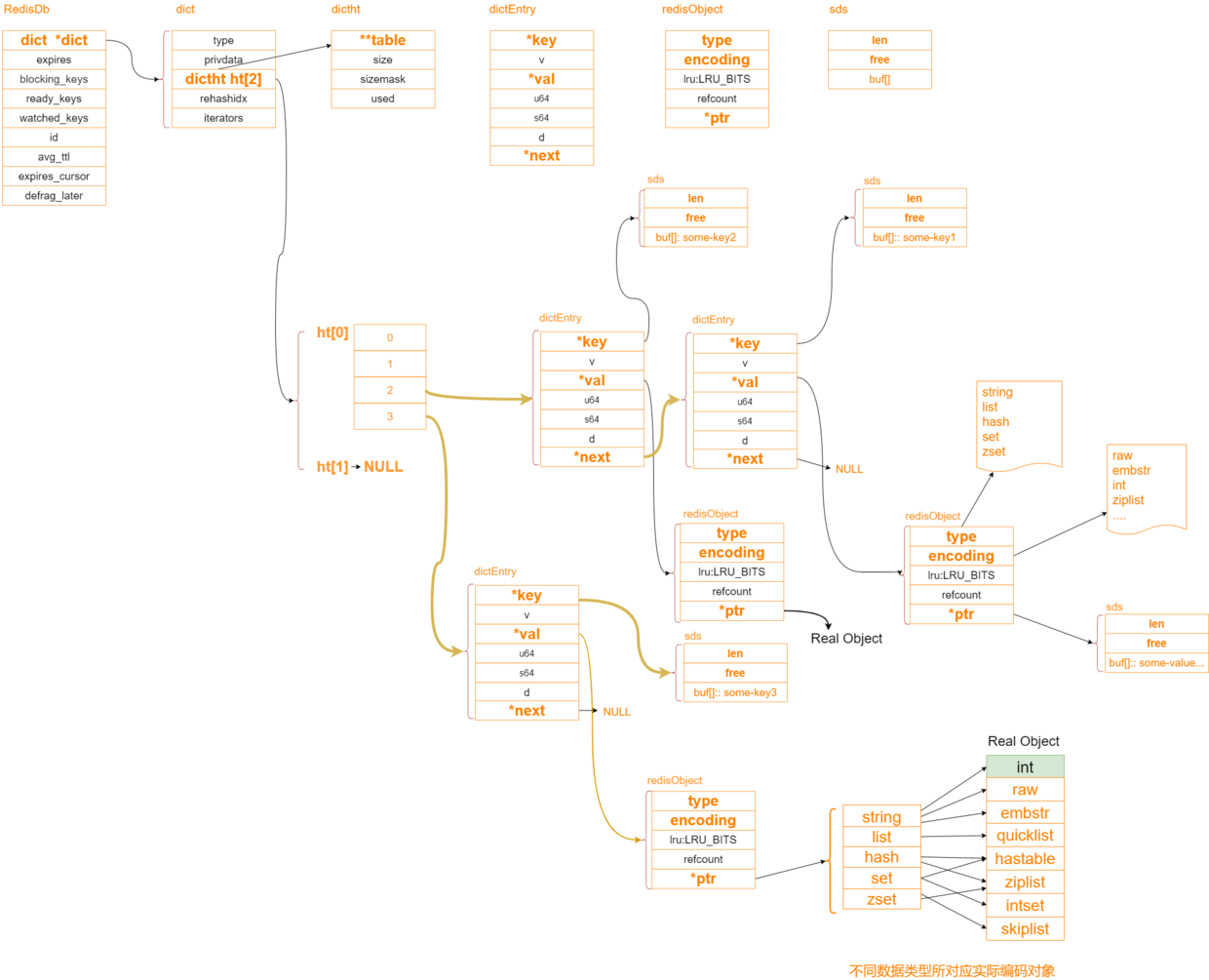
接下來我們看一下記憶體關系的對應圖
typedef struct redisObject {
unsigned type:4; //當前物件型別 list string hash set zset等
unsigned encoding:4; //redis做的底層優化(編碼)
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
最后咱們有一張總的圖來表是redis的記憶體關系
encoding存盤的優化策略
1:整型編碼的處理
我們先來看一個例子
127.0.0.1:6379> set type-int 12345
OK
127.0.0.1:6379> object encoding type-int
"int"
//回傳的encoding型別是int
127.0.0.1:6379> set type-int-long 12345678901234567890
OK
127.0.0.1:6379> object encoding type-int-long
"embstr"
//回傳的encoding型別是embstr
我們可以發現,在都是數字的時候,如果長度小于20,就會自動轉換為int型別,這是redis中專門做的處理
if (len <= 20 && string2l(s, len, &value))
在一個redisObject中,就可以直接用ptr去存盤整型值,而不用重新去開辟一塊sds的空間
2:redis物件字串存盤相關優化
127.0.0.1:6379> set type-str-short xxx
OK
127.0.0.1:6379> object encoding type-str-short
"embstr"
127.0.0.1:6379> set type-str-long xxxxxxxxxx-xxxxxxxxxx-xxxxxxxxxx-xxxxxxxxxx-x
//字串長度45
127.0.0.1:6379> object encoding type-str-long
"raw"
127.0.0.1:6379> set type-str-long2 xxxxxxxxxx-xxxxxxxxxx-xxxxxxxxxx-xxxxxxxxxx-
//字串長度44
127.0.0.1:6379> object encoding type-str-long2
"embstr"
一個redisobject是存在記憶體中的,cpu在完成一個io的時候,它是怎么來讀資料的呢,其實cup的io中有一個緩沖行的概念,在linux系統中,一個緩沖行一般是64個位元組
接下來我們看看一個redis物件大概占多大的記憶體空間,其實我們可以大概算出來,
typedef struct redisObject {
unsigned type:4; //4bit
unsigned encoding:4; //4bit
unsigned lru:LRU_BITS; //24bit
int refcount; //4byte
void *ptr; //8byte
} robj;
一個redis物件本身就需要占 (4bit+4bit+24bit = 4byte) + 4byte + 8byte = 16byte的大小
這樣的話一個緩沖行還剩余48個byte的大小,有點浪費,
48個byte,按照sds的分配策略應該在sdshdr8那個區間中,而sdshdr8本身就需要占3個位元組,sds需要兼容c語言的函式庫,都會在結尾加上\0,所以sdshdr8本身是占用4個位元組,所以一個緩沖行中還剩余44個位元組,來存盤剩余的資料,所以在redis字串物件中,當長度小于44的時候,encoding的型別是embstr,沒有新開辟一塊sds空間
關注我的技術公眾號,每周都有優質技術文章推送,
微信掃一掃下方二維碼即可關注:

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/172667.html
標籤:其它
上一篇:redis原始碼之SDS