MySQL索引底層資料結構
索引是存盤引擎快速找到記錄的一種資料結構
一、 有索引與沒索引的差距
先來看一張圖:
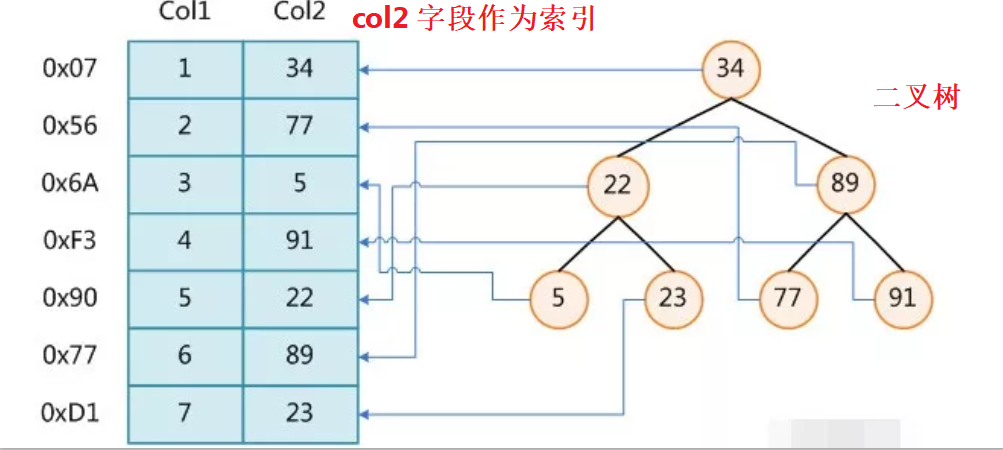
左邊是沒有索引的情況,右邊是作為col2欄位 二叉樹索引的情況,
假如執行查找(假設表為 t)
select *from t where col2 = 89;
那么,左邊的情況,需要比較6次才能找到,右邊的情況,只需要比較2次就可以找到,當資料量非常大時,要查找的資料又非常靠后,那么二叉樹結構的查詢優勢將非常明顯,
擴展:
在右邊二叉樹的結構中,每個節點都是 key-value 鍵值對的形式,
key:col2所在行在磁盤檔案中的指標(比如 34 所在行,通過 0x07 這個指標就能找到是第1行)
value:就是col2的值;
二叉樹的特點:
左子節點值 < 節點值;
右子節點值 > 節點值;
二、 二叉樹索引存在的問題
雖然二叉樹能提高查找速度,但不是最優的,存在很大的問題,
比如:
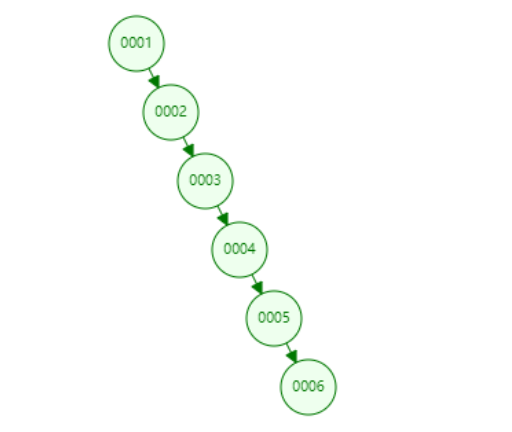
通過圖,可以看出,二叉樹出現單邊增長時,二叉樹變成了“鏈”,這樣查找一個數的時候,速度并沒有得到很大的優化,
三、 進一步優化,用紅黑樹
二叉樹出現上述情況,顯然不太好,那用紅黑樹怎樣呢?
先來看紅黑樹的結構
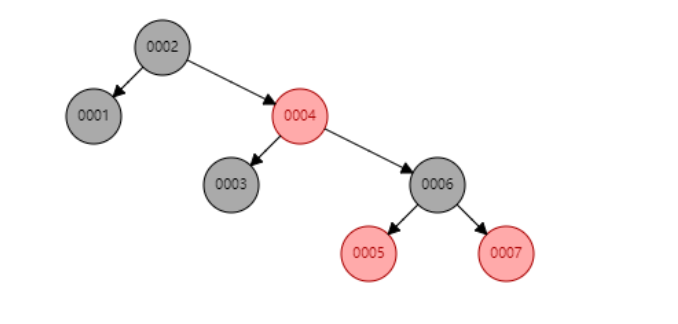
但紅黑樹最大問題是高度問題,
假設現在資料量有100萬,那么紅黑樹的高度大概為 100,0000 = 2^n, n大概為 20,
那么,至少要20次的磁盤IO,這樣,性能將很受影響,如果資料量更大,IO次數更多,性能損耗更大,
所以,如果能降低IO次數,將是一個非常好的解決方案,
四、 Hash表
Hash是MySQL中支持的兩種索引結構中的一種,
Hash的大致原理是:
- 事先將索引通過 hash演算法后得到的hash值(即磁盤檔案指標)存到hash表中,
- 在進行查詢時,將索引通過hash演算法,得到hash值,與hash表中的hash值比對,通過磁盤檔案指標,只要一次磁盤IO就能找到要的值,
例如:
在第一個表中,要查找col=6的值,hash(6) 得到值,比對hash表,就能得到89,性能非常高,
Hash表存在的問題:
但是hash表索引存在問題,如果要查詢 帶范圍的條件時,hash索引就歇菜了,
例如:
select *from t where col1>=6;
hash索引就無能為力了,作業中一般用BTree用的多,
五、 B-Tree
回到紅黑樹的問題,之所以不選中紅黑樹,最大的原因是沒有解決高度問題,(盡管高度相對無索引或普通二叉樹已經降低很多,但資料量大時,仍然要多次磁盤IO)
而BTree索引能很好解決高度問題,
B-Tree 是一種平衡的多路查找(又稱排序)樹,在檔案系統中和數據庫系統有所應用,主要用作檔案的索引,其中的B就表示平衡(Balance),
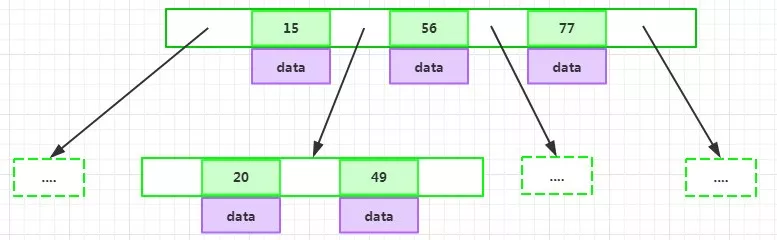
BTree 的特性:
為了描述BTree,首先定義一條資料記錄為一個二元組[key, data],key為記錄的鍵值,對于不同資料記錄,key是互不相同的;data為資料記錄除以key外的資料,那么BTree是滿足下列條件的資料結構:
- d 為大于1的一個正整數,稱為BTree的度;
- h為一個正整數,稱為BTree的高度;
- key和指標互相間隔,節點兩端是指標;
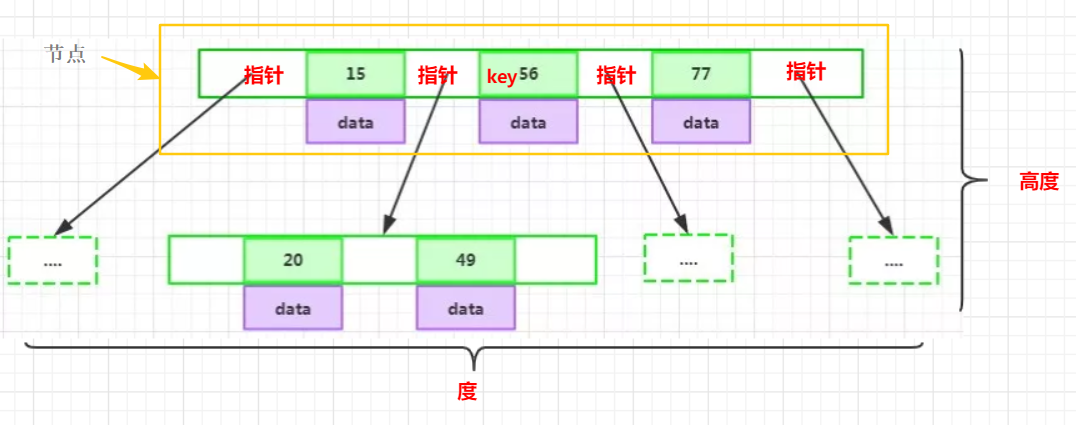
-
一個節點中的key從左到右非遞減排序
-
每個指標要么為null,要么指向另外一個節點;每個非葉子節點由 n-1 個key 和 n個指標組成,其中
d <= n <= 2d;
-
每個葉子節點最少包含一個key和兩個指標,最多包含 2d-1個key 和 2d個指標,葉節點的指標均為null
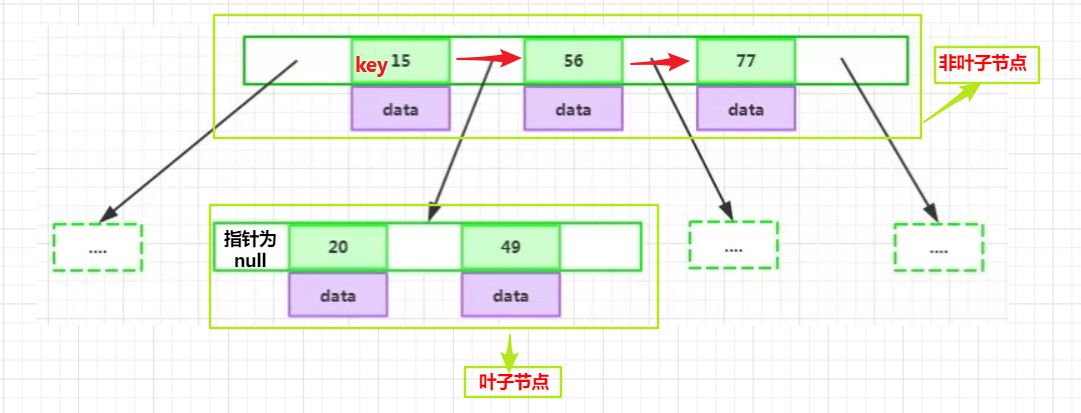
- 如圖
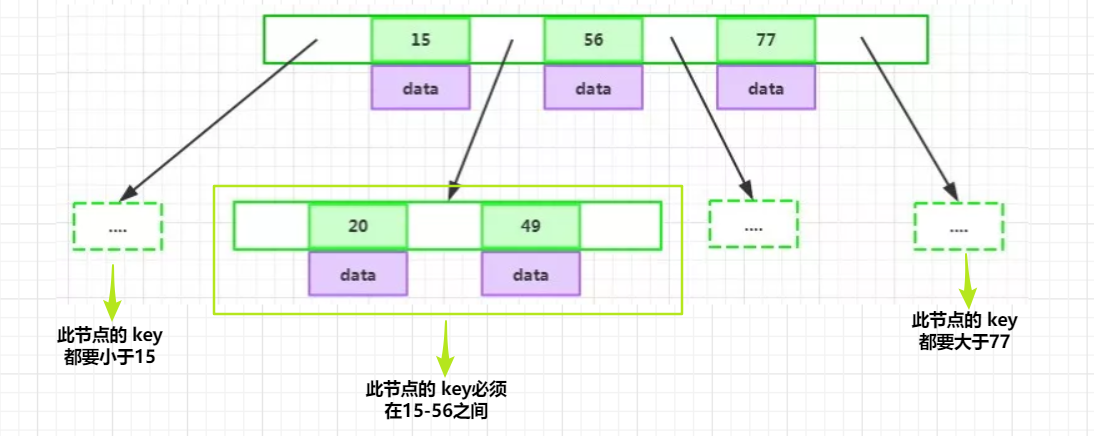
總結:
我們可以稍微總結一下,BTree具有:
- 葉節點具有相同的深度
- 葉節點的指標為空
- 節點的資料索引從左到右遞增排列
但是BTree仍然存在一些問題,比如執行下面的陳述句,查找col1 > 20 的值
select *from t where col1 > 20;
那么不但需要葉子節點>20的值,也需要非葉子節點在右邊節點的值,即下圖圈的兩部分:
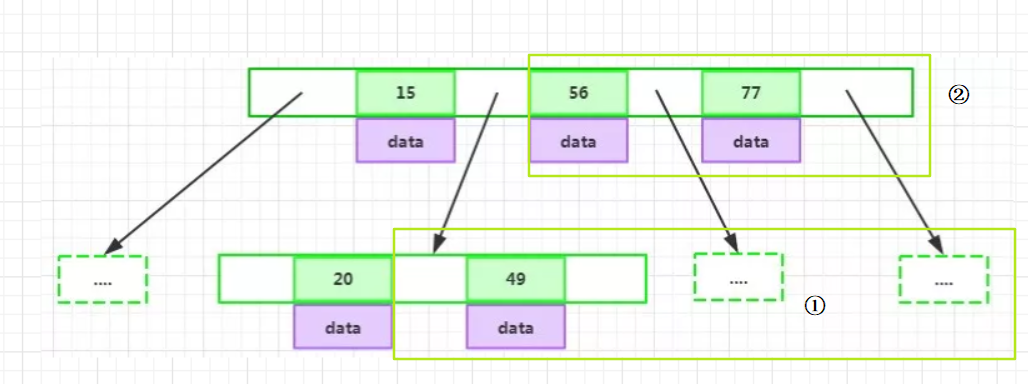
BTree似乎在范圍查找沒有更簡便的方法,為了解決這一問題,我們可以用B+Tree,
六、 B+Tree
B+Tree樹是B-Tree的變種,能更好的解決范圍查找問題,
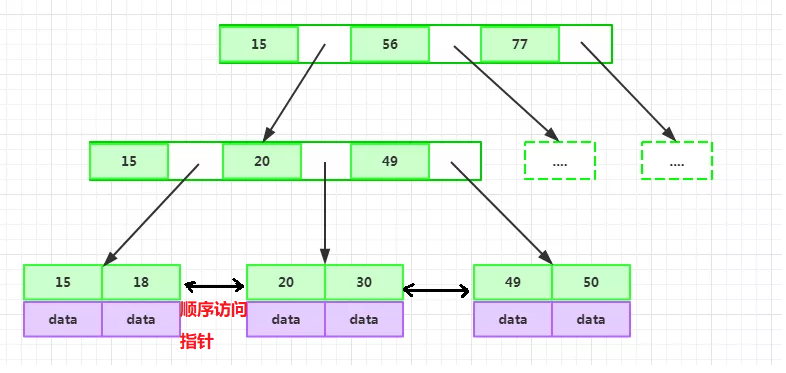
6.1 B+Tree的特性:
- 非葉子節點不存盤data,只存盤索引,可以存放更多索引
- 葉子節點不存盤指標
- 順序訪問指標,提高區間訪問性能
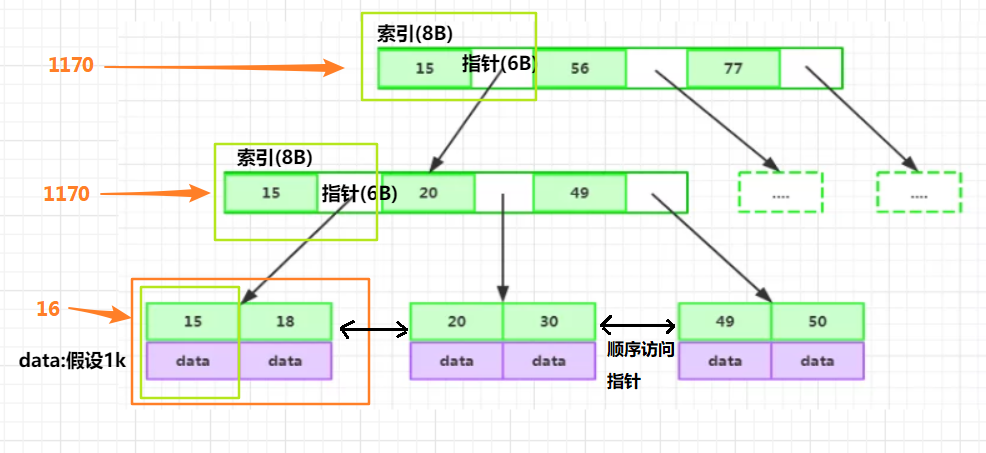
6.2 B+Tree 索引為什么可以支持千萬級別資料量的查找
分析:
MySQL 官方對非葉子節點(如最上層 h = 1的節點,B+Tree高度為3) 的大小是有限制的,通過執行
SHOW GLOBAL STATUS like 'InnoDB_page_size';
可以得到大小為 16384,即 16k大小,
那么第二層也是16k大小,
假如:B+Tree的表都存滿了,索引的節點的型別為BigInt,大小為8B,指標為6B,
最后一層,假如 存放的資料data為1k 大小,那么
- 第一層最大節點數為: 16k / (8B + 6B) = 1170 (個);
- 第二層最大節點數也應為:1170個;
- 第三層最大節點數為:16k / 1k = 16 (個),
則,一張B+Tree的表最多存放 1170 * 1170 * 16 ≈ 2千萬,
所以,通過分析,我們可以得出,B+Tree結構的表可以容納千萬資料量的查詢,
而且一般來說,MySQL會把 B+Tree 根節點放在記憶體中,那只需要兩次磁盤IO就行,
6.3 B+Tree解決范圍查找
在上述的圖中,我們可以看到B+Tree 還有一個順序訪問指標,這樣一來,當我們會到上面的范圍查找
select *from t where col1 >= 20;
時,B+Tree可以通過該指標把20 后面的直接找到,非常方便,
七、 MyISAM和InnoDB存盤引擎和索引
7.1 MyISAM
MyISAM存盤引擎在前面講過,上圖(主鍵索引)
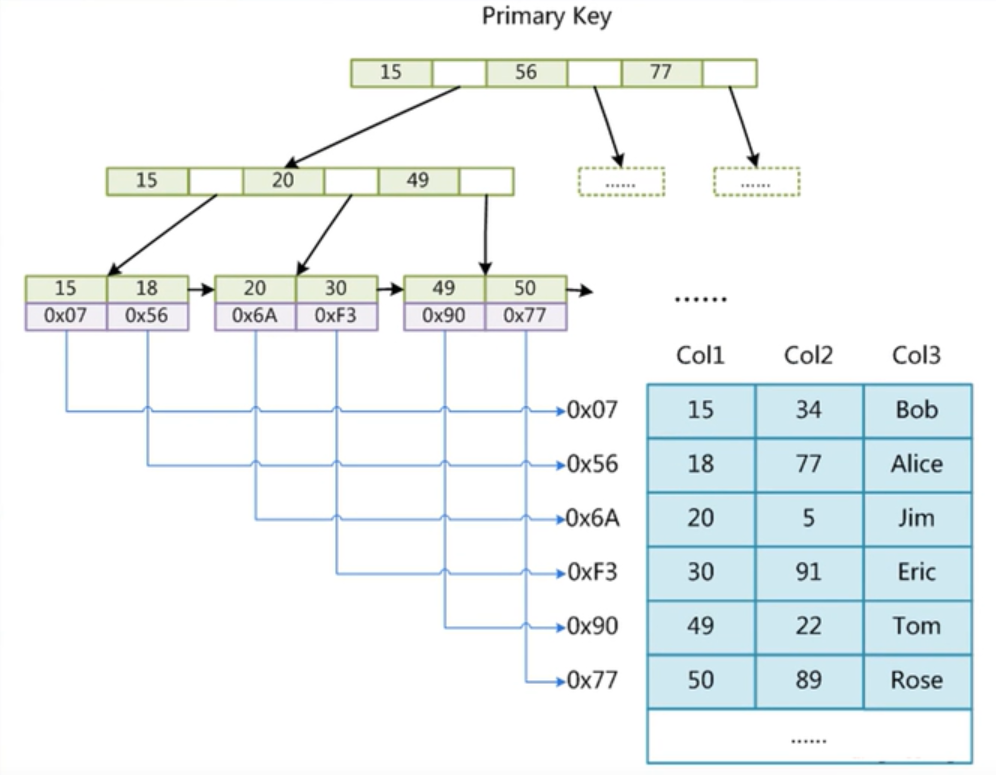
我們知道,MyISAM索引檔案和資料檔案是分開的(非聚集),存盤引擎在磁盤中檔案有三個,
一個是 .frm 檔案(資料表定義),
一個是 .MYI(索引),
一個是 .MYD(實際資料,存盤的是一整行的資料,包括索引值),
MY檔案是B+Tree為底層組織的檔案,
比如查找 49,那么再 .MYI 中找到 49對應的磁盤指標 0x49,根據 0x49 去 .MYD找到實際的資料內容 data,
7.2 InnoDB
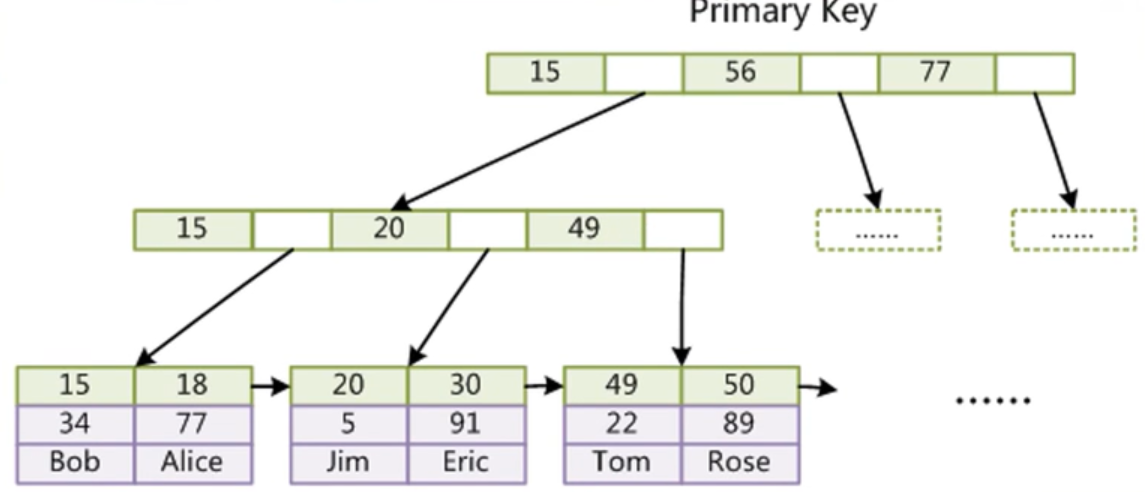
7.2.1 InnoDB結構
我們知道InnoDB存盤引擎是聚集索引的,它的表資料檔案本身就是按 B+Tree 組織的一個索引檔案,
不同于MyISAM存盤引擎是,資料不分離,
如下圖,找到49的索引之后,資料就在該節點,不必像MyISAM存盤引擎那樣,需要根據磁盤指標到另一個檔案中取資料,性能比MyISAM高,
7.2.2 InnoDB必須要有主鍵,并且推薦使用整型自增主鍵
要有主鍵:mysql底層就是用B+Tree維護的,而B+Tree的結構就決定了必須有主鍵才能構建B+Tree樹這個結構,每個表在磁盤上,是單獨的一個檔案,索引和資料都在其中,檔案是按照主鍵索引組織的一個B+TREE結構,假如沒有定義主鍵,MySQL會在挑選能唯一標識的欄位作為索引;假如找不到,會生成一個默認的隱藏列作為主鍵列,
整型主鍵:假如使用類似 UUID 的字串作為主鍵,那么在查找時,需要比較兩個主鍵是否相同,這是一個相比整型比較 非常耗時的程序,需要一個字符,一個字符的比較,自然比較慢,
自增主鍵:自增的好處體現在,
- 后面的主鍵索引總是大于前面的主鍵索引,在做范圍查詢時,非常方便找到需要的資料,
- 在添加的程序中,因為是自增的,每次添加都是在后面插入,樹分裂的機會小;而UUID大小不確定,分裂機會大,性能損耗大,
7.2.3 為什么非主鍵索引結構葉子節點存盤的是主鍵值?
非主鍵的 data存盤的是 主鍵值的好處:
-
節省空間:指向主鍵的節點,不用再存盤一份相同的資料;
-
資料一致性:如果修改索引15 的資料,那只要修改主鍵的 data,
而如果非主鍵的data也存一份的話,那得修改兩份,
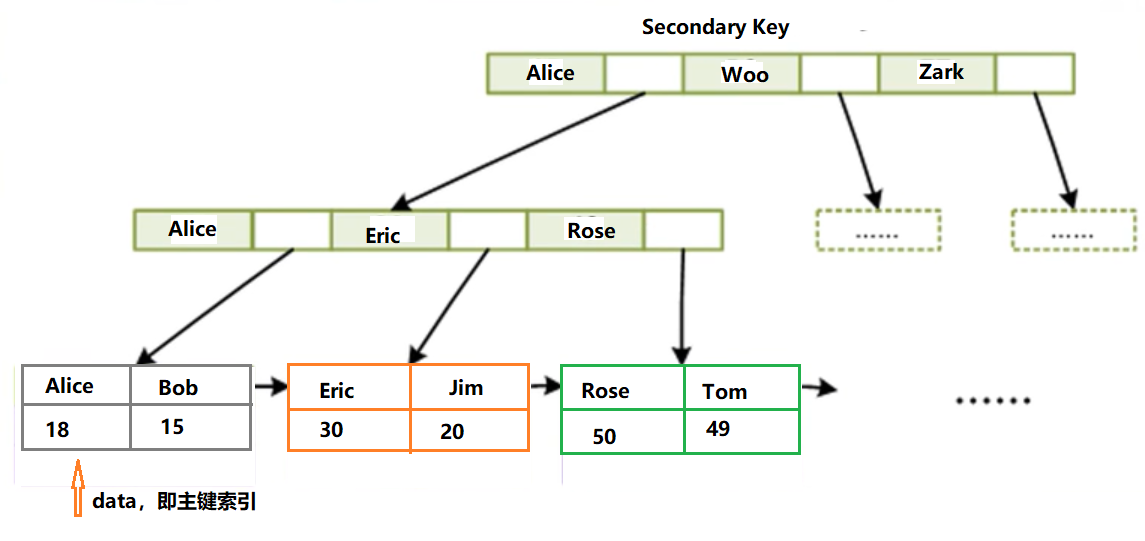
7.2.4 聯合索引的底層結構
就是排序,第一相同,排第二個,類推,
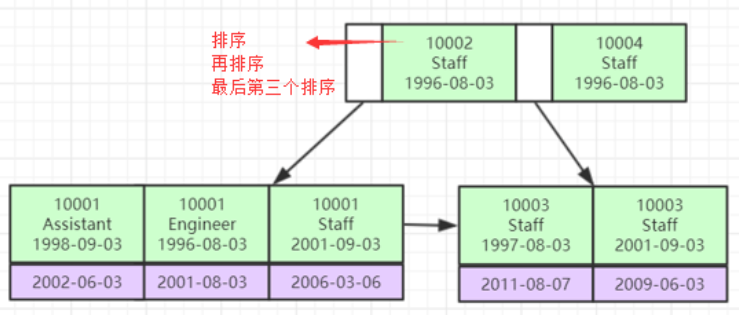
參考
深入理解Mysql索引底層資料結構與演算法
講真,MySQL索引優化看這篇文章就夠了
硬碟的讀取原理
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/173206.html
標籤:MySQL
上一篇:mysql索引