計算機學習者經常會用到諸如Sqlserver Mysql Orcal 等“關系型”資料庫,
問題一:那么,到底什么是“關系”呢?
首先,我們來看以下三組資料

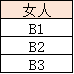
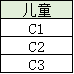
注:A1,A2表示具體的某個人,比如張三,李四
我們用數學集合的形式對其進行表達,得到三個集合
男人: D1 { A1,A2,A3 }
女人: D2 { B1,B2,B3 }
小孩: D3 { C1,C2,C3 }
我們稱 D1 D2 D3 為 “域”
接來下,我們將這三個集合取笛卡爾積(如果不懂的話,請自行查閱,簡單理解就是從三個集合中元素里各取一個,能夠形成的所有組合)
D1*D2*D3=? 直觀來說,結果顯示在下表內
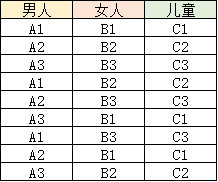
顯然,該結果整體并沒有什么真實含義,單純的作為一些資料的組合,于是,我們便通過“某一關系”將表中含有意義的部分選擇出來,如下圖:
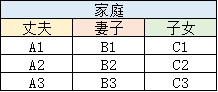
通過“家庭”這種“關系”我們便得到了上表,其中意義顯而易見且通俗易懂,正是我們人類,資料庫管理人員、開發者等所需要的,這個表再關系型資料庫中被稱為“關系”,
其中,丈夫,妻子,子女統稱為屬性名,家庭作為關系名或表名,
由此表,可得到一些解釋:
1.元組:一行完整的資料,如A1 B1 C1
2.關系:屬性名+表名+資料
3.關系模式:屬性名+表名
通過對比可看出關系與關系模式的異同,同一關系模式下可能存在多種關系,比如隨著時間的推移,人口的更變,表中資料發生了變化,所以關系模式是穩定的,關系是不穩定的,
問題二:那么,我們為什么要通過求笛卡爾積這種思路來理解這部分的學習呢?計算機與數學到底是什么關系呢?
有人說,“數學是上帝的語言”,我們作為開發者,雖然我們最常使用的是高級語言,諸如C++ JAVA C#,他們代碼的書寫方式,語法,編程范式,編程思想都更加接近于人類的思考
縱觀計算機語言發展歷史,語言的目的在于溝通,作為一端,計算機本質上只是一門工具,語言的發展本質上是應該更好的服務于開發者,使其更容易專注于業務,而非機器邏輯,
但是,為了讓機器更加高效的服務,我們不得不在一些事上有所側重,一些底層系統更是如此,
顯然,計算機并不能直接理解我們的話,他直接理解的可能只有01,只有邏輯運算,只有線性運算(只有加法與乘法構成的運算),因此,我們為了讓計算機能夠聽懂并且好用,我們需要定義“數學模型”!
看到這里,很多問題迎刃而解,為什么我們要用笛卡爾積,為什么我們要取他的子集,甚至為什么我們要在每個列上取一個新的名字并且標注他的型別(如,學生表中的年齡(int)),
歸根結底,我們在尋求一種來自于數學的精準定義,計算機能夠理解并執行的數學模型! 模型如下:
關系模式 R(A1:D1,A2:D2,...,An:Dn);
舉個例子,家庭(丈夫:男人,妻子:女人,孩子:兒童);
家庭作為關系名,丈夫作為屬性,:后面跟著的男人就是丈夫所屬的“域”(你可以理解為,領域或型別,比如1、2、3的域可以是整數),
那么,為什么既然有域了,我還要有屬性名呢?
因為,實際業務中,很多屬性都來源于同一個域,我們可以有效地區分,例如:身高和體重都來源于浮點型域,姓名和地址都來源于字串型別域,
至此,什么是關系,什么是表,在資料庫使用中,我們為什么要這么定義表,從根本上都是有原因的,相信,你已經明白了,再見~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/18475.html
標籤:SQL Server
上一篇:select count(1)和select count(*)的區別
下一篇:Unity性能優化技巧