寫在前面:想要流暢閱讀本文,需要讀者——對K8s的架構有簡單了解,理解API Server扮演的角色;具有閱讀簡單golang原始碼的能力,包括函式/類方法定義、變數宣告等,
如何理解Controller
先參考一段官方的解釋:
當你設定了溫度,告訴了溫度自動調節器你的期望狀態(Desired State),房間的實際溫度是當前狀態(Current State),通過對設備的開關控制,溫度自動調節器讓其當前狀態接近期望狀態,
控制器通過 apiserver 監控集群的公共狀態,并致力于將當前狀態轉變為期望的狀態,
上面這段話其實比較形象地說明了Controller的核心作業,就是使得集群的當前狀態符合我們所輸入的期望狀態,比如我們需要這個集群擁有3個節點,那么就有一個Node Controller來幫我們實作這個“期望”,拉起并按照我們所設定的規則部署這3個節點,
這里需要注意的是,我們所謂的Controller,其實更應該說是Controllers,因為并不是說全域只有一個Controller大包大攬,處理完成目標任務的所有邏輯,而是由許許多多個Controller分工合作、各司其職,它們分別只關心自己感興趣的資源,只有當它們感興趣的資源發生了變化(添加/更新/洗掉)時,它們才會執行自己的業務邏輯,就好比如,一個濕度控制器只關心用戶輸入的期望濕度并將房間調整到這個濕度,而一個溫度控制器只關心輸入的期望溫度并去調整室內溫度,
因此,一個最原始的Controller實作可以用下面的偽代碼表示:
for {
desired := getDesiredState()
current := getCurrentState()
makeChanges(desired, current)
}
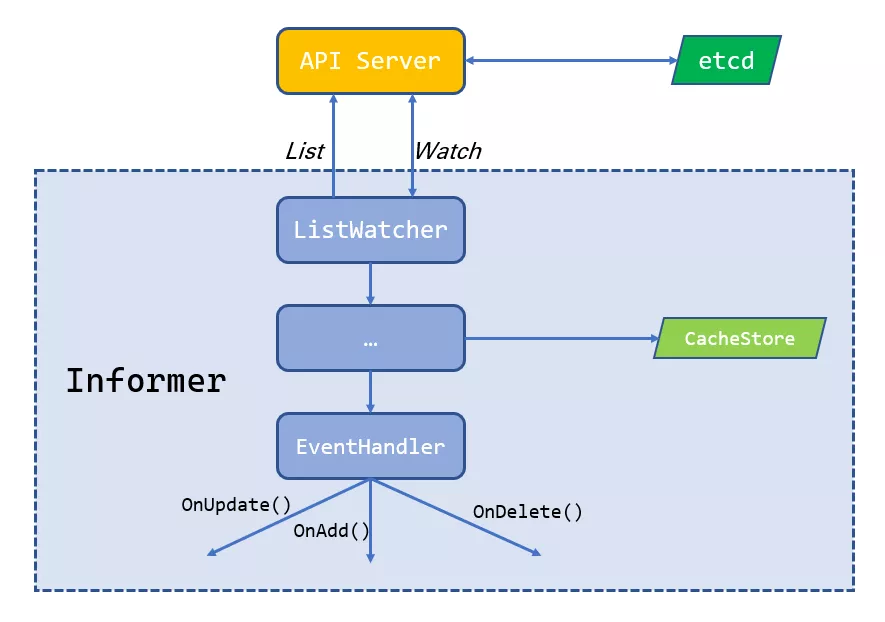
關于Controller作業機制的組成,可以宏觀地理解為一個Controller主要由Informer/SharedInformer與Workqueue兩部分組成,一個整體的作業流程可以概括為:Informer/SharedInformer監聽目標資源(Resource)的變化,并在出現變化時回應事件、發送事件給Workqueue,再由作業執行緒(Worker)從Workqueue取出事件并執行業務邏輯,下面我將結合原始碼,對Controller的作業機制進行剖析,除非特殊說明,下面出現的代碼均來自K8s的client-go庫——一個用于撰寫與K8s集群互動的客戶端(client)的golang庫;而我要介紹的Controller,本質上就是一個客戶端,通過REST請求與API Server的反復互動最終達成完成的“控制”任務,
Informer
如前面所述,Informer的職責是監聽目標資源的變化,并在出現變化時發送事件給Workqueue,將剩下的作業交給執行業務邏輯的作業執行緒,這也正如其名——Informer(通知者),扮演的是一個“打報告”的角色,
那么一個Informer是如何作業的?這一點我們可以一窺Informer的創建函式來作個初步認識(關鍵處有注釋標記,將在下文展開介紹),
// K8s.io/client-go/tools/cache/controller.go
// NewInformer returns a Store and a controller for populating the store
// while also providing event notifications. You should only used the returned
// Store for Get/List operations; Add/Modify/Deletes will cause the event
// notifications to be faulty.
//
// Parameters:
// * lw is list and watch functions for the source of the resource you want to
// be informed of.
// * objType is an object of the type that you expect to receive.
// * resyncPeriod: if non-zero, will re-list this often (you will get OnUpdate
// calls, even if nothing changed). Otherwise, re-list will be delayed as
// long as possible (until the upstream source closes the watch or times out,
// or you stop the controller).
// * h is the object you want notifications sent to.
//
func NewInformer(
lw ListerWatcher, // 2.1
objType runtime.Object, // 2.2
resyncPeriod time.Duration, // 2.3
h ResourceEventHandler, // 2.4
) (Store, Controller) {
// This will hold the client state, as we know it.
clientState := NewStore(DeletionHandlingMetaNamespaceKeyFunc) // 2.5
// This will hold incoming changes. Note how we pass clientState in as a
// KeyLister, that way resync operations will result in the correct set
// of update/delete deltas.
fifo := NewDeltaFIFO(MetaNamespaceKeyFunc, clientState)
cfg := &Config{
Queue: fifo,
ListerWatcher: lw,
ObjectType: objType,
FullResyncPeriod: resyncPeriod,
RetryOnError: false,
Process: func(obj interface{}) error {
// from oldest to newest
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Added, Updated:
if old, exists, err := clientState.Get(d.Object); err == nil && exists {
if err := clientState.Update(d.Object); err != nil {
return err
}
h.OnUpdate(old, d.Object)
} else {
if err := clientState.Add(d.Object); err != nil {
return err
}
h.OnAdd(d.Object)
}
case Deleted:
if err := clientState.Delete(d.Object); err != nil {
return err
}
h.OnDelete(d.Object)
}
}
return nil
},
}
return clientState, New(cfg)
}
一、ListWatcher
在Informer的作業中,監聽目標資源變化的任務由ListWatcher來完成,定義一個ListWatcher,實際上就是定義兩個函式——List和Watch:
// ListerWatcher is any object that knows how to perform an initial list and start a watch on a resource.
type ListerWatcher interface {
// List should return a list type object; the Items field will be extracted, and the
// ResourceVersion field will be used to start the watch in the right place.
List(options metav1.ListOptions) (runtime.Object, error)
// Watch should begin a watch at the specified version.
Watch(options metav1.ListOptions) (watch.Interface, error)
}
List所做的,就是向API Server發送一個http短鏈接請求,羅列所有目標資源的物件,而Watch所做的是實際的“監聽”作業,通過http長鏈接的方式,其與API Server能夠建立一個持久的監聽關系,當目標資源發生了變化時,API Server會回傳一個對應的事件,從而完成一次成功的監聽,之后的事情便交給后面的handler來做,
這樣一個List & Watch機制,帶來了如下幾個優勢:
-
事件回應的實時性:通過Watch的呼叫,當API Server中的目標資源產生變化時,能夠及時的收到事件的回傳,從而保證了事件回應的實時性,而倘若是一個輪詢的機制,其實時性將受限于輪詢的時間間隔,
-
事件回應的可靠性:倘若僅呼叫Watch,則如果在某個時間點連接被斷開,就可能導致事件被丟失,List的呼叫帶來了查詢資源期望狀態的能力,客戶端通過期望狀態與實際狀態的對比,可以糾正狀態的不一致,二者結合保證了事件回應的可靠性,
-
高性能:倘若僅周期性地呼叫List,輪詢地獲取資源的期望狀態并在與當前狀態不一致時執行更新,自然也可以do the job,但是高頻的輪詢會大大增加API Server的負擔,低頻的輪詢也會影響事件回應的實時性,Watch這一異步訊息機制的結合,在保證了實時性的基礎上也減少了API Server的負擔,保證了高性能,
-
事件處理的順序性:我們知道,每個資源物件都有一個遞增的ResourceVersion,唯一地標識它當前的狀態是“第幾個版本”,每當這個資源內容發生變化時,對應產生的事件的ResourceVersion也會相應增加,在并發場景下,K8s可能獲得同一資源的多個事件,由于K8s只關心資源的最終狀態,因此只需要確保執行事件的ResourceVersion是最新的,即可確保事件處理的順序性,
二、目標資源
傳入的objType形參,代表這個Informer所關心并且監聽的目標資源型別,
三、ResyncPeriod
Informer呼叫List進行輪詢的時間間隔,當其不為0時,即便沒有更新事件發生,List也會每隔一段時間被呼叫以獲得最新的資源物件狀態,從而獲得更高一級的可靠性,
四、ResourceEventHandler
當經過List & Watch得到事件時,接下來的實際回應作業就交由ResourceEventHandler來進行,這個Interface定義如下:
type ResourceEventHandler interface {
OnAdd(obj interface{})
OnUpdate(oldObj, newObj interface{})
OnDelete(obj interface{})
}
當事件到來時,Informer根據事件的型別(添加/更新/洗掉資源物件)進行判斷,將事件分發給系結的EventHandler,即分別呼叫對應的handle方法(OnAdd/OnUpdate/OnDelete),最后EventHandler將事件發送給Workqueue,
五、Local Store
如果K8s每次想查看資源物件的狀態,都要經歷一遍List呼叫,顯然對API Server也是一個不小的負擔,對此,一個容易想到的方法是使用一個cache作保存,需要獲取資源狀態時直接調cache,當事件來臨時除了回應事件外,也對cache進行重繪,
六、SharedInformer
Informer通過Local Store快取目標資源物件,且僅為自己所用,但是在K8s中,一個Controller可以關心不止一種資源,使得多個Controller所關心的資源彼此會存在交集,如果幾個Controller都用自己的Informer來快取同一個目標資源,顯然會導致不小的空間開銷,因此K8s引入了SharedInformer來解決這個問題,
SharedInformer擁有為多個Controller提供一個共享cache的能力,從而避免資源快取的重復、減小空間開銷,除此之外,一個SharedInformer對一種資源只建立一個與API Server的Watch監聽,且能夠將監聽得到的事件分發給下游所有感興趣的Controller,這也顯著地減少了API Server的負載壓力,實際上,K8s中廣泛使用的都是SharedInformer,Informer則出場甚少,
有了上面各個部分的解釋,我們再將其串起來,就可以得到一個Informer/SharedInformer作業的整體步驟:
-
通過List & Watch機制監聽目標資源的變化(即,監聽一個事件),
-
事件到來時,將目標資源的新(期望)狀態存入cache,并分發給系結的EventHandler;如果是SharedInformer,可能系結來自多個Controller的多個EventHandler,此時事件會被分發給所有EventHandler,
-
EventHandler得到事件后,將事件發送到Workqueue,
關于Informer/SharedInformer的作業原理,上面作了一個整體的介紹,但也省略了不少的具體實作細節,看過其他K8s文章的同學們可能還聽過Reflector, DeltaFIFO, ProcessListener等概念,這些都是Informer/SharedInformer在實作“監聽目標資源變化,回應事件”這一目標所引入的實作細節,本文由于篇幅所限,不對這些細節做詳細闡述,想要了解這些實作細節,可以參閱我在學習程序中找到的一篇很不錯的博文,給予了我不小的幫助,
Worlqueue
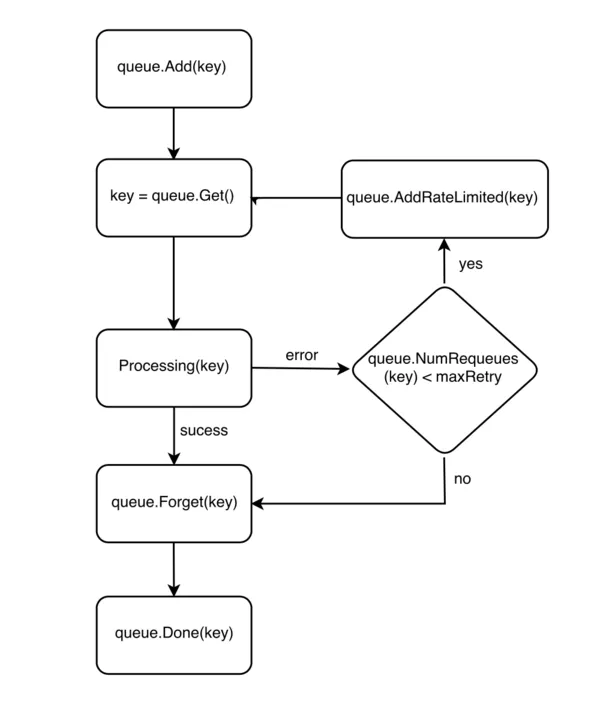
EventHandler向Workqueue加入事件的操作非常簡單粗暴,僅僅是放入一個key,這個key的內容是資源物件的命名空間與資源名的組合,即<resource_namespace>/<resource_name>,唯一地標識了一個資源物件,而Controller處理被加入Workqueue中的事件的方式,就是從Workqueue中pop出一個key,根據這個key獲取到這個資源的期望狀態——從哪里獲取呢?自然是從Informer/SharedInformer保存的cache里獲取!Controller剩下的作業,就是執行自己的一套業務邏輯,讓集群的實際狀態達到這個期望狀態,
Workqueue中的一個key的生命周期如下圖所示:
在Controller執行業務邏輯、處理事件的程序中,也許會由于某些原因遇到失敗,這時這個事件并不會被直接丟棄,Controller會呼叫AddRateLimited()方法,使得這個key過一段時間后重新被推進Workqueue,再由Controller取出、進行retry,直到retry的次數達到上限才被丟棄,當事件執行成功后,只需要將這個key從Workqueue中移除即可:Forget()方法首先被呼叫,但注意此時key并沒有從Workqueue中被移除,因為Forget()只是將這個key在“retry次數表”中的記錄洗掉;而真正將key從Workqueue中移除,是通過Done()方法的呼叫,
關于Workqueue,還有一個值得一提的設計點,我們先引入一個問題:
一、一個問題
假如用戶傳入了一個新期望狀態,想把一個資源的副本數從1變成2,經過我們上面所介紹的流程,最后輪到Controller從Workqueue中取出這個資源的key,進行事件的處理——就在處理的程序中,用戶緊跟著又傳入了一個新的期望狀態,想把該資源的副本數變成3,這時候,K8s該怎么辦?
有同學可能會說,那簡單啊,再推入一個同樣的key到Workqueue里,Controller再次取出進行處理不就行了,但若是這樣做,將會帶來兩個問題:
(1)Controller在處理事件的程序中是并行的,有許多個Worker執行緒不斷從Workqueue中取事件并處理,在上面的問題背景中,如果這個相同的key被推進Workqueue,可能馬上就有一個空閑的Worker執行緒取出并處理該事件,那么同一時刻,就會有兩個Worker執行緒在作業:一個在嘗試把資源的副本數變成2,而另一個在嘗試把資源的副本數變成3——這顯然是一個非常糟糕的情況,
(2)即便我們假設只有一個Worker執行緒來處理事件,不會有并行處理帶來的競爭,那么簡單把同一個key推入Workqueue,Controller在處理完當前的事件(把1變成2)之后再取出該key,再執行一次業務邏輯,把2變成3,聽起來沒什么問題,但是,假如用戶在短短的時間內,陸陸續續地又傳入了1000個新期望狀態(把3變成4,把4變成5…),這時Controller再反反復復地取出、處理,合理嗎?顯然不合理,因為K8s中我們只關注“最終狀態”,只執行一次業務邏輯把1變成1000,和不斷執行1000次業務邏輯把1變成1000,結果上是一樣的,但效率上卻是一個天上一個地下,
也正是因此,K8s中的Workqueue,并不是說只是一個FIFO佇列這么簡單,
二、Workqueue的設計
那么K8s是怎么設計Workqueue的呢?
在Workqueue中,有三個主要部分:一個主queue用于給Controller取出key,一個dirty set用于存放“臟key”,以及一個processing set用于存放“正在處理的key”,
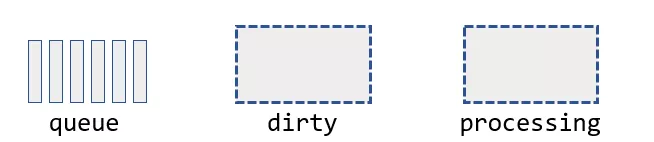
要理解Workqueue的作業程序,我們可以分別查看Workqueue的Add(), Get(), Done()方法,理解入key、取key、彈出key這三個操作中,key如何在上面這三個部分間轉換,
首先是Add()方法:
// Add marks item as needing processing.
func (q *Type) Add(item interface{}) {
q.cond.L.Lock()
defer q.cond.L.Unlock()
if q.shuttingDown {
return
}
if q.dirty.has(item) { // 如果dirty set中有該key,回傳
return
}
q.metrics.add(item)
q.dirty.insert(item) // 將key插入dirty set
if q.processing.has(item) { // 如果processing set中有該key,回傳
return
}
q.queue = append(q.queue, item) // 將key放入主queue
q.cond.Signal()
}
代碼比較清晰易懂,我們可以從上面總結Add()主要的邏輯:
(1)如果dirty set中有同一個key,則直接回傳,因為這個key已經被標記為“臟”,
(2)如果dirty set中沒有該key,先將該key插入dirty set中,
(3)如果processing set中有同一個key,說明Controller正在處理一個對應這key的事件,由于上面已經將該key標記為“臟”,此時可以直接回傳,
(4)如果dirty set和processing set中都沒有該key,則可以將該key放入主queue中,待Controller取出并處理事件,
然后是Get()方法:
// Get blocks until it can return an item to be processed. If shutdown = true,
// the caller should end their goroutine. You must call Done with item when you
// have finished processing it.
func (q *Type) Get() (item interface{}, shutdown bool) {
q.cond.L.Lock()
defer q.cond.L.Unlock()
for len(q.queue) == 0 && !q.shuttingDown {
// 主queue為空,阻塞等待事件到來
q.cond.Wait()
}
if len(q.queue) == 0 {
// We must be shutting down.
return nil, true
}
item, q.queue = q.queue[0], q.queue[1:] // 彈出主queue中最前的key
q.metrics.get(item)
q.processing.insert(item) // 將取得的key插入processing set中
q.dirty.delete(item) // 由于已經開始處理事件,key不再是“臟”的,從dirty set中洗掉key
return item, false // 回傳從主queue中彈出的key
}
可以看到取一個key的操作會將該key從主queue中彈出,并加入processing set中表示正在處理該key的事件,同時抹掉該key的“臟”標記,因為Controller已經開始處理了,
最后是Done()方法:
// Done marks item as done processing, and if it has been marked as dirty again
// while it was being processed, it will be re-added to the queue for
// re-processing.
func (q *Type) Done(item interface{}) {
q.cond.L.Lock()
defer q.cond.L.Unlock()
q.metrics.done(item)
q.processing.delete(item) // 事件已經處理完畢,從processing set中洗掉key
if q.dirty.has(item) { // 如果dirty set中有該key,說明處理事件的程序中進來了一個或者多個該key的新事件
q.queue = append(q.queue, item) // 將該key推入主queue中,等待再次處理
q.cond.Signal()
}
}
可以看到,Done()方法首先會將已經處理完的key從processing set中移除,之后,如果發現dirty set中還有該key,說明中途有個對應該key的新事件傳入,此時已經處理完的事件并不代表資源物件的“最新”期望狀態,需要重新將該key放入主queue中、重新處理;如果dirty set中沒有該key,說明中途沒有同一個key的事件發生,那么就萬事大吉,實際狀態已經與最新期望狀態符合了!
從上面的代碼來總結,我們可以得到如下圖的Workqueue內部狀態轉移圖:
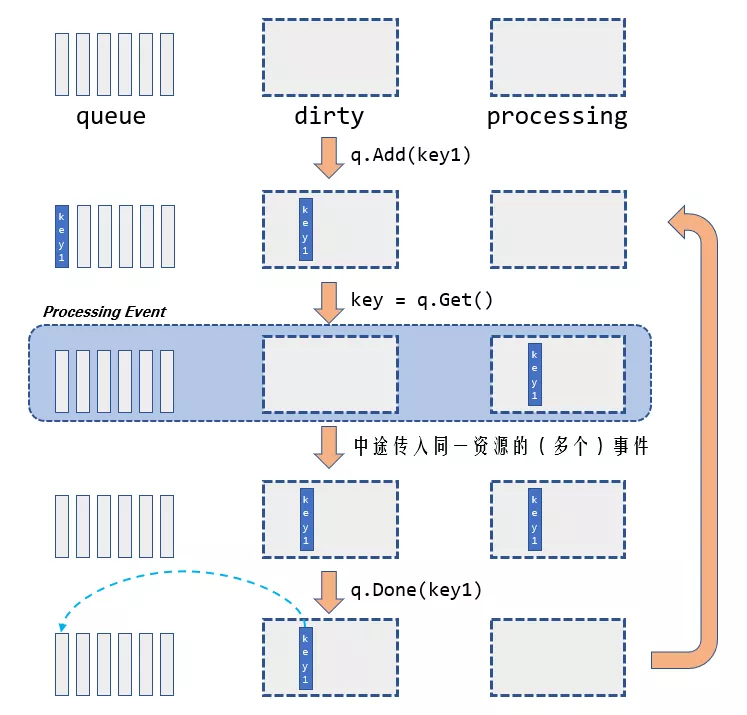
這時,針對我之前提出的問題,我們就有了K8s給出的答案了:
當Controller處理一個key的事件程序中,傳入了該key的一個新事件,Workqueue在內部會將這個key放進dirty set(標記為“臟”),當手頭的事件處理完成后,Workqueue會把這個臟key又放入主queue中等待再次處理,確保目標資源物件的實際狀態符合最新的期望狀態,與此同時,即便在處理程序中陸陸續續傳入了幾百上千個該key的新事件,dirty set中只會存放該key的單一副本,因此最后也只需要一次性地從中取出、放入主queue、處理,這也就實作了所謂的“只關心最終狀態”,而processing set的存在,則保證了同一時間不會有兩個Worker執行緒處理同一個key的事件,
EventHandler事件過濾 – controller-runtime
Informer/SharedInformer將事件分發給EventHandler之后,將由EventHandler把事件發送到Workqueue供作業執行緒“享用”,但在這之前,EventHandler實際上可以負責一定的過濾作業,因為我們不應該得到一個事件就不管三七二十一地交給作業執行緒處理:一個傳來的事件可能由于發生了某些錯誤缺少一些關鍵內容,又或者這個事件不是預定義的規則里關心的事件(比如用戶想更新某個資源的一個不允許更新的欄位),
我們以update事件的handle程序為引,對EventHandler做一個剖析,前面Informer的創建函式中,創建的config中有一個Process函式,其中有這一段代碼:
switch d.Type {
case Sync, Added, Updated:
if old, exists, err := clientState.Get(d.Object); err == nil && exists {
if err := clientState.Update(d.Object); err != nil { // 更新cache
return err
}
h.OnUpdate(old, d.Object) // 呼叫handler的OnUpdate函式
}
// ...
}
代碼比較直觀,當事件到來時,Process函式先判斷事件的型別,當識別到是一個update事件時,則呼叫EventHandler的OnUpdate方法,并將資源物件的舊狀態與新狀態作為實參傳入,而在這個OnUpdate()方法中,我們就可以塞入一些我們自己定制的過濾規則,
在此之前,先介紹一下controller-runtime庫:
controller-runtime是由Kubebuilder和Operator-SDK提供的,用于使用戶更方便地自定義Controller的go庫,與此同時,client-go是由K8s官方提供的、用于與K8s集群打交道的client端,提供了用戶自定義Controller的介面,controller-runtime在client-go的基礎上,針對常見的應用場景實作了部分介面,并且對低層介面做了一定包裝,提供了更高層的API,使得用戶自定義Controller的作業更加輕松,
以下的代碼,均來自controller-runtime庫對client-go庫所提供的介面的實作,
EventHandler struct中,對OnUpdate介面的實作如下:
// sigs.K8s.io/controller-runtime/pkg/source/internal
// OnUpdate creates and UpdateEvent and calls Update on EventHandler
func (e EventHandler) OnUpdate(oldObj, newObj interface{}) { // 實作ResourceEventHandler Interface
u := event.UpdateEvent{}
// Pull metav1.Object out of the object
if o, err := meta.Accessor(oldObj); err == nil {
u.MetaOld = o
} else {
log.Error(err, "OnUpdate missing MetaOld",
"object", oldObj, "type", fmt.Sprintf("%T", oldObj))
return
}
// Pull the runtime.Object out of the object
if o, ok := oldObj.(runtime.Object); ok {
u.ObjectOld = o
} else {
log.Error(nil, "OnUpdate missing ObjectOld",
"object", oldObj, "type", fmt.Sprintf("%T", oldObj))
return
}
// Pull metav1.Object out of the object
if o, err := meta.Accessor(newObj); err == nil {
u.MetaNew = o
} else {
log.Error(err, "OnUpdate missing MetaNew",
"object", newObj, "type", fmt.Sprintf("%T", newObj))
return
}
// Pull the runtime.Object out of the object
if o, ok := newObj.(runtime.Object); ok {
u.ObjectNew = o
} else {
log.Error(nil, "OnUpdate missing ObjectNew",
"object", oldObj, "type", fmt.Sprintf("%T", oldObj))
return
}
for _, p := range e.Predicates { // 使用預定義規則過濾事件
if !p.Update(u) {
return
}
}
// Invoke update handler
e.EventHandler.Update(u, e.Queue) // 呼叫handler的update方法,將事件加入Workqueue
}
代碼前一大段的四個if-else分支,處理的都是對傳入的資源物件舊狀態與新狀態的資訊檢驗,當出現關鍵資訊缺失時,由于更新無法進行,因此報錯并回傳,不將該事件加入Workqueue,
緊跟著最后一個if-else分支的for回圈,是我們需要關注的,它的作用是使用所有預定義的規則對傳入的事件進行過濾,controller-runtime庫中定義了一種Predicate介面,用戶可以自己實作Predicate介面來自定義過濾規則,也可以直接使用controller-runtime提供的幾個常用場景的實作,一個Predicate物件代表一種規則,由于我們現在處理的是update事件,那么就呼叫這個Predicate物件p的Update方法,當傳入事件不符合p所定義的規則時,p.Update(u)回傳false,EventHandler將過濾掉該事件,函式回傳,事件不會進入Workqueue,
為了方便理解Predicate,我們可以查看一個controller-runtime庫提供的一種Predicate——GenerationChangedPredicate,它內部的規則是過濾掉一切不改變資源物件Generation(這里注意與ResourceVersion區分)的事件,這種情況在更新資源Status的時候會發生,在我們自定義Controller的時候,有時候會在業務邏輯處理事件完畢之后加一個對Status的更新操作,這也會引發一個更新事件進入Workqueue,于是業務邏輯再次取出處理,處理完后又雙叒發起一個Status更新,最后造成一個死回圈,為了避免死回圈,所以我們會需要這個GenerationChangedPredicate對Status更新事件進行過濾,不讓它進Workqueue,
GenerationChangedPredicate中對Update方法的定義如下:
// Update implements default UpdateEvent filter for validating generation change
func (GenerationChangedPredicate) Update(e event.UpdateEvent) bool {
if e.MetaOld == nil {
log.Error(nil, "Update event has no old metadata", "event", e)
return false
}
if e.ObjectOld == nil {
log.Error(nil, "Update event has no old runtime object to update", "event", e)
return false
}
if e.ObjectNew == nil {
log.Error(nil, "Update event has no new runtime object for update", "event", e)
return false
}
if e.MetaNew == nil {
log.Error(nil, "Update event has no new metadata", "event", e)
return false
}
if e.MetaNew.GetGeneration() == e.MetaOld.GetGeneration() {
// 對比舊狀態與新狀態的Generation,相同則過濾該事件
return false
}
return true
}
可以看到關鍵的邏輯只有一個對新舊狀態的Generation對比,如果相同則回傳false,該事件就會被EventHandler過濾掉,而不加入Workqueue,
當上面的資訊檢驗、是否符合規則的判斷等邏輯走完了之后,EventHandler就會呼叫Update方法,將事件加入Workqueue中,我們取EnqueueRequestForObject對該介面方法的實作:
// Update implements EventHandler
func (e *EnqueueRequestForObject) Update(evt event.UpdateEvent, q workqueue.RateLimitingInterface) {
if evt.MetaOld != nil {
q.Add(reconcile.Request{NamespacedName: types.NamespacedName{ // 加入Workqueue
Name: evt.MetaOld.GetName(),
Namespace: evt.MetaOld.GetNamespace(),
}})
} else {
enqueueLog.Error(nil, "UpdateEvent received with no old metadata", "event", evt)
}
if evt.MetaNew != nil {
q.Add(reconcile.Request{NamespacedName: types.NamespacedName{
Name: evt.MetaNew.GetName(),
Namespace: evt.MetaNew.GetNamespace(),
}})
} else {
enqueueLog.Error(nil, "UpdateEvent received with no new metadata", "event", evt)
}
}
可以看到將事件加入Workqueue就是通過呼叫Workqueue物件的Add方法,之后的流程,想必大家通過前面對Workqueue的介紹也知道了,
小結
本篇文章中我結合原始碼,較深入地討論了Controller作業機制的整體流程,包括Informer/SharedInformer對資源變化事件進行監聽與回應、分發給EventHandler,再由EventHandler將事件發送給Workqueue,以及Workqueue的內部作業邏輯,Informer/SharedInformer與Worker執行緒的關系,實際上是一個生產者-消費者關系,利用一個Workqueue將二者分開,既實作了兩個部件的解耦,也解決了雙方處理速度不一致的問題,
K8s的許多設計點都蘊含著的十分精妙的考量,在保證可靠性的基礎上也兼顧著高性能,同時由于源代碼中大部分方法的呼叫都是Interface的呼叫,K8s也具有著十分強大的可擴展性,總而言之,K8s的內部實作是非常值得鉆研與學習的,
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/187377.html
標籤:其它
下一篇:一步步學好sql陳述句