前言
本文主要介紹的是ELK日志系統入門和使用教程,
ELK介紹
ELK是三個開源軟體的縮寫,分別表示:Elasticsearch , Logstash, Kibana , 它們都是開源軟體,新增了一個FileBeat,它是一個輕量級的日志收集處理工具(Agent),Filebeat占用資源少,適合于在各個服務器上搜集日志后傳輸給Logstash,官方也推薦此工具,
-
Elasticsearch是個開源分布式搜索引擎,提供搜集、分析、存盤資料三大功能,它的特點有:分布式,零配置,自動發現,索引自動分片,索引副本機制,restful風格介面,多資料源,自動搜索負載等,
-
Logstash 主要是用來日志的搜集、分析、過濾日志的工具,支持大量的資料獲取方式,一般作業方式為c/s架構,client端安裝在需要收集日志的主機上,server端負責將收到的各節點日志進行過濾、修改等操作在一并發往elasticsearch上去,
-
Kibana 也是一個開源和免費的工具,Kibana可以為 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以幫助匯總、分析和搜索重要資料日志,
-
Filebeat是一個輕量型日志采集器,可以方便的同kibana集成,啟動filebeat后,可以直接在kibana中觀看對日志檔案進行detail的程序,
ELasticSearch介紹
ElasticSearch是什么
Elasticsearch 是一個基于JSON的分布式搜索和分析引擎,它可以從RESTful Web服務介面訪問,并使用模式少JSON(JavaScript物件符號)檔案來存盤資料,它是基于Java編程語言,這使Elasticsearch能夠在不同的平臺上運行,使用戶能夠以非常快的速度來搜索非常大的資料量,
ElasticSearch可以做什么
- 分布式的實時檔案存盤,每個欄位都被索引并可被搜索
- 分布式的實時分析搜索引擎
- 可以擴展到上百臺服務器,處理PB級結構化或非結構化資料
Lucene是什么
ApacheLucene將寫入索引的所有資訊組織成一種倒排索引(Inverted Index)的結構之中,該結構是種將詞項映射到檔案的資料結構,其作業方式與傳統的關系資料庫不同,大致來說倒排索引是面向詞項而不是面向檔案的,且Lucene索引之中還存盤了很多其他的資訊,如詞向量等等,每個Lucene都是由多個段構成的,每個段只會被創建一次但會被查詢多次,段一旦創建就不會再被修改,多個段會在段合并的階段合并在一起,何時合并由Lucene的內在機制決定,段合并后數量會變少,但是相應的段本身會變大,段合并的程序是非常消耗I/O的,且與之同時會有些不再使用的資訊被清理掉,在Lucene中,將資料轉化為倒排索引,將完整串轉化為可用于搜索的詞項的程序叫做分析,文本分析由分析器(Analyzer)來執行,分析其由分詞器(Tokenizer),過濾器(Filter)和字符映射器(Character Mapper)組成,其各個功能顯而易見,
更多ElasticSearch的相關介紹可以查看我的這篇博文:https://www.cnblogs.com/xuwujing/p/12093933.html
Logstash介紹
Logstash是一個資料流引擎:
它是用于資料物流的開源流式ETL引擎,在幾分鐘內建立資料流管道,具有水平可擴展及韌性且具有自適應緩沖,不可知的資料源,具有200多個集成和處理器的插件生態系統,使用Elastic Stack監視和管理部署
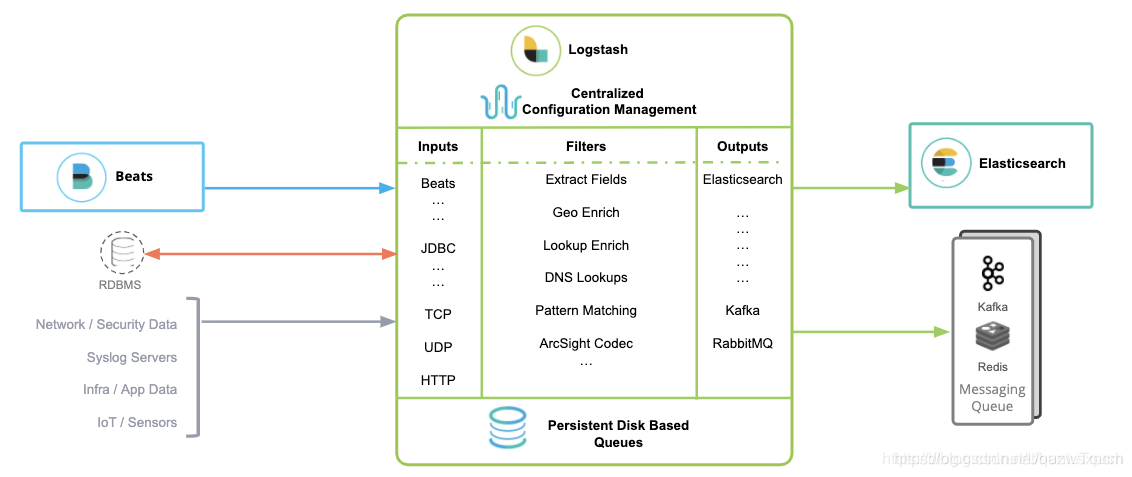
Logstash包含3個主要部分: 輸入(inputs),過濾器(filters)和輸出(outputs),
inputs主要用來提供接收資料的規則,比如使用采集檔案內容;
filters主要是對傳輸的資料進行過濾,比如使用grok規則進行資料過濾;
outputs主要是將接收的資料根據定義的輸出模式來進行輸出資料,比如輸出到ElasticSearch中.
示例圖:
Kibana介紹
Kibana 是一款開源的資料分析和可視化平臺,它是 Elastic Stack 成員之一,設計用于和 Elasticsearch 協作,您可以使用 Kibana 對 Elasticsearch 索引中的資料進行搜索、查看、互動操作,您可以很方便的利用圖表、表格及地圖對資料進行多元化的分析和呈現,
Kibana 可以使大資料通俗易懂,它很簡單,基于瀏覽器的界面便于您快速創建和分享動態資料儀表板來追蹤 Elasticsearch 的實時資料變化,
Filebeat介紹
Filebeat 是使用 Golang 實作的輕量型日志采集器,也是 Elasticsearch stack 里面的一員,本質上是一個 agent ,可以安裝在各個節點上,根據配置讀取對應位置的日志,并上報到相應的地方去,
Filebeat 的可靠性很強,可以保證日志 At least once 的上報,同時也考慮了日志搜集中的各類問題,例如日志斷點續讀、檔案名更改、日志 Truncated 等,
Filebeat 并不依賴于 ElasticSearch,可以單獨存在,我們可以單獨使用Filebeat進行日志的上報和搜集,filebeat 內置了常用的 Output 組件, 例如 kafka、ElasticSearch、redis 等,出于除錯考慮,也可以輸出到 console 和 file ,我們可以利用現有的 Output 組件,將日志進行上報,
當然,我們也可以自定義 Output 組件,讓 Filebeat 將日志轉發到我們想要的地方,
filebeat 其實是 elastic/beats 的一員,除了 filebeat 外,還有 HeartBeat、PacketBeat,這些 beat 的實作都是基于 libbeat 框架,
Filebeat 由兩個主要組件組成:harvester 和 prospector,
采集器 harvester 的主要職責是讀取單個檔案的內容,讀取每個檔案,并將內容發送到 the output, 每個檔案啟動一個 harvester,harvester 負責打開和關閉檔案,這意味著在運行時檔案描述符保持打開狀態,如果檔案在讀取時被洗掉或重命名,Filebeat 將繼續讀取檔案,
查找器 prospector 的主要職責是管理 harvester 并找到所有要讀取的檔案來源,如果輸入型別為日志,則查找器將查找路徑匹配的所有檔案,并為每個檔案啟動一個 harvester,每個 prospector 都在自己的 Go 協程中運行,
注:Filebeat prospector只能讀取本地檔案, 沒有功能可以連接到遠程主機來讀取存盤的檔案或日志,
示例圖:

ELK日志系統安裝
環境準備
ELK下載地址推薦使用清華大學或華為的開源鏡像站,
下載地址:
https://mirrors.huaweicloud.com/logstash
https://mirrors.tuna.tsinghua.edu.cn/ELK
ELK7.3.2百度網盤地址:
鏈接:https://pan.baidu.com/s/1tq3Czywjx3GGrreOAgkiGg
提取碼:cxng
ELasticSearch集群安裝
ElasticSearch集群安裝依賴JDK,本文的ElasticSearch版本為7.3.2,對應的JDK的版本為12,
1,檔案準備
將下載好的elasticsearch檔案解壓
輸入:
tar -xvf elasticsearch-7.3.2-linux-x86_64.tar.gz
然后移動到/opt/elk檔案夾 里面,沒有該檔案夾則創建,然后將檔案夾重命名為masternode.
在/opt/elk輸入
mv elasticsearch-7.3.2-linux-x86_64 /opt/elk mv
elasticsearch-7.3.2-linux-x86_64 masternode
2,配置修改
因為elasticsearch需要在非root的用戶下面操作,并且elasticsearch的檔案夾的權限也為非root權限, 因此我們需要創建一個用戶進行操作,我們創建一個elastic用戶,并賦予該目錄的權限,
命令如下:
adduser elastic
chown -R elastic:elastic /opt/elk/masternode
這里我們順便再來指定ElasticSearch資料和日志存放的路徑地址,我們可以先使用df -h命令查看當前系統的盤主要的磁盤在哪,然后在確認資料和日志存放的路徑,如果在/home 目錄下的話,我們就在home目錄下創建ElasticSearch資料和日志的檔案夾,這里為了區分,我們可以根據不同的節點創建不同的檔案夾,這里的檔案夾創建用我們剛剛創建好的用戶去創建,切換到elastic用戶,然后創建檔案夾,
su elastic
mkdir /home/elk
mkdir /home/elk/masternode
mkdir /home/elk/masternode/data
mkdir /home/elk/masternode/logs
mkdir /home/elk/datanode
mkdir /home/elk/datanode/data
mkdir /home/elk/datanode/logs
創建成功之后,我們先修改masternode節點的配置,修改完成之后在同級目錄進行copy一下,名稱為datanode,然后只需少許更改datanode節點的配置即可,這里我們要修改elasticsearch.yml和jvm.options檔案即可! 注意這里還是elastic用戶!
cd /opt/elk/
vim masternode/config/elasticsearch.yml
vim masternode/config/jvm.options
masternode配置
這里需要注意的是elasticsearch7.x的配置和6.x有一些不同,主要是在master選舉這塊,
masternode的elasticsearch.yml檔案配置如下:
cluster.name: pancm-cluster
node.name: master-1
network.host: 192.168.0.1
path.data: /home/elastic/masternode/data
path.logs: /home/elastic/masternode/logs
discovery.seed_hosts: ["192.168.0.1:9300","192.168.0.2:9300","192.168.0.3:9300"]
cluster.initial_master_nodes: ["192.168.0.1:9300","192.168.0.2:9300","192.168.0.3:9300"]
node.master: true
node.data: false
transport.tcp.port: 9301
http.port: 9201
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
cluster.routing.allocation.cluster_concurrent_rebalance: 16
cluster.routing.allocation.node_concurrent_recoveries: 16
cluster.routing.allocation.node_initial_primaries_recoveries: 16
elasticsearch.yml檔案引數配置說明:
- cluster.name: 集群名稱,同一集群的節點配置應該一致,es會自動發現在同一網段下的es,如果在同一網段下有多個集群,就可以用這個屬性來區分不同的集群,
- node.name: 該節點的名稱,命名格式建議為節點屬性+ip末尾
- path.data: 資料存放的路徑,
- path.logs: 日志存放的路徑,
- network.host: 設定ip地址,可以是ipv4或ipv6的,默認為0.0.0.0,
- transport.tcp.port:設定節點間互動的tcp埠,默認是9300,
- http.port:設定對外服務的http埠,默認為9200,
- node.master: 指定該節點是否有資格被選舉成為node,默認是true,
- node.data: 指定該節點是否存盤索引資料,默認為true,
- ,,,
將jvm.options配置Xms和Xmx改成4G,配置如下:
-Xms4g
-Xmx4g
datanode配置
在配置完masternode節點的ElasticSearch之后,我們再來配置datanode節點的,我們將masternode節點copy一份并重命名為datanode,然后根據上述示例圖中紅色框出來簡單更改一下即可,
命令如下:
cd /opt/elk/
cp -r masternode/ datanode
vim datanode/config/elasticsearch.yml
vim datanode/config/jvm.options
datenode的elasticsearch.yml檔案配置如下:
cluster.name: pancm-cluster
node.name: data-1
network.host: 192.168.0.1
path.data: /home/elastic/datanode/data
path.logs: /home/elastic/datanode/logs
discovery.seed_hosts: ["192.168.0.1:9300","192.168.0.2:9300","192.168.0.3:9300"]
cluster.initial_master_nodes: ["192.168.0.1:9300","192.168.0.2:9300","192.168.0.3:9300"]
node.master: false
node.data: true
transport.tcp.port: 9300
http.port: 9200
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
cluster.routing.allocation.cluster_concurrent_rebalance: 16
cluster.routing.allocation.node_concurrent_recoveries: 16
cluster.routing.allocation.node_initial_primaries_recoveries: 16
datanode的jvm配置請遵循如下規則,如果記憶體小于64G,則取對半,否則取32G,比如記憶體16G,該jvm設定8G,如果是128G,就可以設定32G,
將jvm.options配置Xms和Xmx改成8G,配置如下:
-Xms8g
-Xmx8g
注:配置完成之后需要使用ll命令檢查一下masternode和datanode權限是否屬于elastic用戶的,若不屬于,可以使用chown -R elastic:elastic +路徑 命令進行賦予權限,
上述配置完成之后,可以使用相同的方法在其他的機器在操作一次,或者使用ftp工具進行傳輸,又或者使用scp命令進行遠程傳輸檔案然后根據不同的機器進行不同的修改,
scp命令示例:
jdk環境傳輸:
scp -r /opt/java root@slave1:/opt
scp -r /opt/java root@slave2:/opt
ElasticSearch環境傳輸:
scp -r /opt/elk root@slave1:/opt
scp -r /home/elk root@slave1:/opt
scp -r /opt/elk root@slave2:/opt
scp -r /home/elk root@slave2:/opt
傳輸完成之后,在其他服務主要修改node.name、network.host這兩個配置即可,
3,elasticsearch啟動
完成elasticsearch集群安裝配置之后,需要使用elastic用戶來進行啟動,每臺機器的每個節點都需要進行操作!
在/opt/elk的目錄下輸入:
su elastic
cd /opt/elk
./masternode/bin/elasticsearch -d
./datanode/bin/elasticsearch -d
啟動成功之后,可以輸入jps命令進行查看或者在瀏覽器上輸入 ip+9200或ip+9201進行查看,
出現以下界面表示成功!

Elasticsearch的6.x版本可以看這篇文章:https://www.cnblogs.com/xuwujing/p/11385255.html
Kibana安裝
注:只需要在一臺服務器上安裝即可!
1,檔案準備
將下載下來的kibana-7.3.2-linux-x86_64.tar.gz的組態檔進行解壓
在linux上輸入:
tar -xvf kibana-7.3.2-linux-x86_64.tar.gz
然后移動到/opt/elk 里面,然后將檔案夾重命名為 kibana-7.3.2
輸入:
mv kibana-7.3.2-linux-x86_64 /opt/elk
mv kibana-7.3.2-linux-x86_64 kibana-7.3.2
2,配置修改
進入檔案夾并修改kibana.yml組態檔:
cd /opt/elk/kibana-7.3.2
vim config/kibana.yml
將組態檔新增如下配置:
server.port: 5601
server.host: "192.168.0.1"
elasticsearch.hosts: ["http://192.168.0.1:9200"]
elasticsearch.requestTimeout: 180000
3,Kinaba 啟動
在啟動這塊,和kibana6.x有一些區別,
root用戶下啟動
在kibana上一級檔案夾輸入:
nohup ./kibana-7.3.2/bin/kibana --allow-root >/dev/null 2>&1 &
非root用戶啟動
需要將kibana設定的權限改為對用的用戶權限
權限修改命令實體:
chown -R elastic:elastic /opt/elk/kibana-7.3.2
非root用戶啟動命令:
nohup ./kibana-7.3.2/bin/kibana >/dev/null 2>&1 &
啟動成功之后再瀏覽器輸入:
http://IP:5601

示例圖:

Logstash安裝
注:只需要在一臺服務器上安裝即可!
1,檔案準備
將下載下來的logstash-7.3.2.tar.gz的組態檔進行解壓
在linux上輸入:
tar -xvf logstash-7.3.2.tar.gz
然后移動到/opt/elk 里面,然后將檔案夾重命名為 logstash-7.3.2
輸入:
mv logstash-7.3.2.tar /opt/elk
mv logstash-7.3.2.tar logstash-7.3.2
2,配置修改
進入檔案夾并創建logstash-filebeat.conf組態檔:
cd /opt/elk/logstash-7.3.2
touch logstash-filebeat.conf
vim logstash-filebeat.conf
在組態檔新增如下配置,filter部分請根據對應情況修改
input {
beats {
type => "java"
port => "5044"
}
}filter {
grok {
match => { "message" =>"|%{DATA:log_time}|%{DATA:thread}|%{DATA:log_level}|%{DATA:class_name}|-%{GREEDYDATA:content}" }
}ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 86060)"
}
ruby {
code => "event.set('@timestamp',event.get('timestamp'))"
}
mutate {
remove_field => ["timestamp"]
}date {
match => [ "log_timestamp", "yyyy-MM-dd-HH:mm:ss" ]
locale => "cn"
}mutate {
rename => { "host" => "host.name" }
}}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["192.168.0.1:9200"]
index => "mylogs-%{+YYYY.MM.dd}"
}
}
-
port :是logstash接受filebeat資料的埠,保證filebeat傳輸到logstash的埠是該埠即可,
-
hosts: 這個填寫elasticsearch的地址和設定的埠,集群地址可以用逗號隔開,
-
Index : 寫入索引庫的名稱,%{+YYYY.MM.dd} 表示按天創建索引庫,
3,Logstash 啟動
root用戶下啟動
在 Logstash 檔案夾輸入:
nohup ./bin/logstash -f logstash-filebeat.conf >/dev/null 2>&1 &
或對組態檔進行熱加載啟動:
nohup ./bin/logstash -f logstash-filebeat.conf --config.reload.automatic >/dev/null 2>&1 &
示例圖:

Filebeat安裝
1,檔案準備
將下載下來的filebeat-7.3.2-linux-x86_64.gz的組態檔進行解壓
在linux上輸入:
tar -xvf filebeat-7.3.2-linux-x86_64.tar.gz
然后移動到/opt/elk 里面,然后將檔案夾重命名為 filebeat-7.3.2
輸入
mv filebeat-7.3.2-linux-x86_64 /opt/elk
mv filebeat-7.3.2-linux-x86_64 filebeat-7.3.2
配置啟動測驗,使用root用戶在filebeat檔案夾輸入:
./filebeat -c filebeat_test.yml test config
啟動命令:
./filebeat -e -c filebeat_logstash.yml
后臺啟動命令:
nohup ./filebeat -c filebeat_logstash.yml >/dev/null 2>&1 &
若是后臺啟動,可以在filebeat統計目錄的logs目錄查看日志資訊,
其它
ElasticSearch實戰系列:
- ElasticSearch實戰系列一: ElasticSearch集群+Kinaba安裝教程
- ElasticSearch實戰系列二: ElasticSearch的DSL陳述句使用教程---圖文詳解
- ElasticSearch實戰系列三: ElasticSearch的JAVA API使用教程
- ElasticSearch實戰系列四: ElasticSearch理論知識介紹
- ElasticSearch實戰系列五: ElasticSearch的聚合查詢基礎使用教程之度量(Metric)聚合
- ElasticSearch實戰系列六: Logstash快速入門
- ElasticSearch實戰系列七: Logstash實戰使用-圖文講解
- ElasticSearch實戰系列八: Filebeat快速入門和使用---圖文詳解
音樂推薦
<iframe frameborder="no" border="0" marginwidth="0" marginheight="0" width="330" height="86" src="https://www.cnblogs.com//music.163.com/outchain/player?type=2&id=490186189&auto=0&height=66"></iframe>原創不易,如果感覺不錯,希望給個推薦!您的支持是我寫作的最大動力!
著作權宣告:
作者:虛無境
博客園出處:http://www.cnblogs.com/xuwujing
CSDN出處:http://blog.csdn.net/qazwsxpcm
掘金出處:https://juejin.im/user/5ae45d5bf265da0b8a6761e4
個人博客出處:http://www.panchengming.com
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/189522.html
標籤:其他