1、資料準備
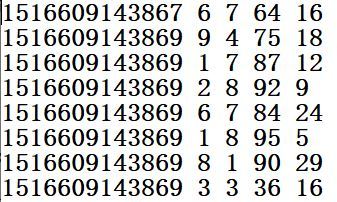
agent.log:時間戳,省份,城市,用戶,廣告,中間欄位使用空格分隔,
2、需求分析
方法一:
(1)用空格分割每一行的資料,需要的資料是省份id和廣告id
(2)將省份id和廣告id和次數1組成鍵值對,通過算子map組合成((省份id,廣告id),1)
(3)計算相同key的總和,使用算子reduceByKey將相同key的值聚合到一起,在shuffle前有combine操作
(4)用map將((省份id,廣告id),sum)改為(省份id,(廣告id,sum))
(5)將同一個省份的所有廣告進行分組聚合(省份id,List((廣告id1,sum1),(廣告id2,sum2)…))
(6)對同一個省份所有廣告的集合進行排序并取前3條
方法二:
(1)用空格分割每一行的資料,需要的資料是省份id和廣告id
(2)將同一個省份的所有廣告進行分組聚合(省份id,List(廣告id1,廣告id2,…))
(3)將廣告id和次數1組成鍵值對,通過算子map組合成(廣告id,1),并根據廣告id進行分組聚合,再通過算子map轉換成List之后取出廣告id和List大小
(4)根據List大小進行降序排序,并取出前3條
3、代碼實作
方法一:
package com.require
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo1 {
def main(args: Array[String]): Unit = {
//1、實體化conf物件以及創建sc物件
val conf = new SparkConf().setMaster("local").setAppName(Demo1.getClass.getSimpleName)
val sc = new SparkContext(conf)
//2、讀取檔案
val fileRDD: RDD[String] = sc.textFile("F:\\資料\\agent.log")
//3、切分、拼1
val toOneRDD: RDD[((String, String), Int)] = fileRDD.map { x =>
val strings: Array[String] = x.split(" ")
((strings(1), strings(4)), 1)
}
//4、聚合((province,add),sum)
val sumRDD: RDD[((String, String), Int)] = toOneRDD.reduceByKey(_ + _)
//5、將省份作為key,廣告加點擊數為value:(province,(add,sum))
val mapRDD: RDD[(String, (String, Int))] = sumRDD.map(x => (x._1._1, (x._1._2, x._2)))
//6、將同一個省份的所有廣告進行分組聚合(province,List((add1,sum1),(add2,sum2)...))
val groupRDD: RDD[(String, Iterable[(String, Int)])] = mapRDD.groupByKey()
//7、對同一個省份所有廣告的集合進行排序并取前3條
val sortRDD: RDD[(String, List[(String, Int)])] = groupRDD.mapValues { x =>
x.toList.sortWith((x, y) => x._2 > y._2).take(3)
}
//8、將資料拉取到Driver端并列印
sortRDD.collect().foreach(println)
sc.stop()
}
}
方法二:
package com.require
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo2 {
def main(args: Array[String]): Unit = {
//1、實體化conf物件以及創建sc物件
val conf = new SparkConf().setMaster("local").setAppName(Demo2.getClass.getSimpleName)
val sc = new SparkContext(conf)
//2、讀取檔案
val fileRDD: RDD[String] = sc.textFile("F:\\資料\\agent.log")
//3、切分
val mapRDD: RDD[(String, String)] = fileRDD.map(x => {
val strings: Array[String] = x.split(" ")
(strings(1), strings(4))
})
//4、根據省份進行分組(province,List(add1,add2,...))
val groupRDD: RDD[(String, Iterable[String])] = mapRDD.groupByKey()
//5、處理List
val result: RDD[(String, List[(String, Int)])] = groupRDD.map(x => {
//將廣告拼1,并分組取出大小
val stringToInt: Map[String, Int] = x._2.map((_, 1)).groupBy(_._1).map(y => {
val size: Int = y._2.toList.size
(y._1, size)
})
//根據廣告數量降序排序并取出前三
val tuples: List[(String, Int)] = stringToInt.toList.sortBy(-_._2).take(3)
(x._1, tuples)
})
//6、列印
result.foreach(println)
sc.stop()
}
}
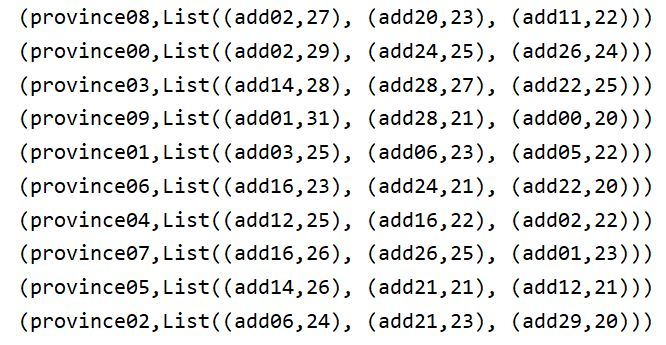
4、運行結果
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/194183.html
標籤:其他
上一篇:Python基礎語法(Python自動化測驗入門1)
下一篇:面向物件和面向程序簡述