oracle11g資料庫匯入匯出:
①:傳統方式——exp(匯出)和(imp)匯入:
②:資料泵方式——expdp匯出和(impdp)匯入;
③:第三方工具——PL/sql Develpoer;
一、什么是資料庫匯入匯出?
oracle11g資料庫的匯入/匯出,就是我們通常所說的oracle資料的還原/備份,
資料庫匯入:把.dmp 格式檔案從本地匯入到資料庫服務器中(本地oracle測驗資料庫中);
資料庫匯出:把資料庫服務器中的資料(本地oracle測驗資料庫中的資料),匯出到本地生成.dmp格式檔案,
.dmp 格式檔案:就是oracle資料的檔案格式(比如視頻是.mp4 格式,音樂是.mp3 格式);
二、二者優缺點描述:
1.exp/imp:
優點:代碼書寫簡單易懂,從本地即可直接匯入,不用在服務器中操作,降低難度,減少服務器上的操作也就 保證了服務器上資料檔案的安全性,
缺點:這種匯入匯出的速度相對較慢,合適資料庫資料較少的時候,如果檔案超過幾個G,大眾性能的電 腦,至少需要4~5個小時左右,
2.expdp/impdp:
優點:匯入匯出速度相對較快,幾個G的資料檔案一般在1~2小時左右,
缺點:代碼相對不易理解,要想實作匯入匯出的操作,必須在服務器上創建邏輯目錄(不是真正的目錄),我們 都知道資料庫服務器的重要性,所以在上面的操作必須慎重,所以這種方式一般由專業的程式人員來完 成(不一定是DBA(資料庫管理員)來干,中小公司可能沒有DBA),
3.PL/sql Develpoer:
優點:封裝了匯入匯出命令,無需每次都手動輸入命令,方便快捷,提高效率,
缺點:長時間應用會對其產生依賴,降低對代碼執行原理的理解,
三、特別強調:
目標資料庫:資料即將匯入的資料庫(一般是專案上正式資料庫);
源資料庫:資料匯出的資料庫(一般是專案上的測驗資料庫);
1.目標資料庫要與源資料庫有著名稱相同的表空間,
2.目標資料在進行匯入時,用戶名盡量相同(這樣保證用戶的權限級別相同),
3.目標資料庫每次在進行資料匯入前,應做好資料備份,以防資料丟失,
4.使用資料泵時,一定要現在服務器端建立可用的邏輯目錄,并檢查是否可用,
5.弄清是匯入匯出到相同版本還是不同版本(oracle10g版本與oracle11g版本),
6.目標資料匯入前,弄清楚是資料覆寫(替換),還是僅插入新資料或替換部分資料表,
7.確定目標資料庫磁盤空間是否足夠容納新資料,是否需要擴充表空間,
8.匯入匯出時注意字符集是否相同,一般Oracle資料庫的字符集只有一個,并且固定,一般不改變,
9.匯出格式介紹:
? Dmp格式:.dmp是二進制檔案,可跨平臺,還能包含權限,效率好;
? Sql格式:.sql格式的檔案,可用文本編輯器查看,通用性比較好,效率不如第一種,
適合小資料量匯入匯出,尤其注意的是表中不能有大欄位 (blob,clob,long),如果有,會報錯;
? Pde格式:.pde格式的檔案,.pde為PL/SQL Developer自有的檔案格式,只能用PL/SQL Developer工具
匯入匯出,不能用文本編輯器查看;
10.確定操作者的賬號權限,
原諒色走一波......
四、二者的匯入匯出方法:
1、傳統方法:
dmp檔案的匯出
首先,我們先了解dmp檔案的匯出
dmp檔案匯出一般用的比較多的是三種,分別是: 匯出整個資料庫實體的所有資料,匯出指定用戶的所有的表,匯出指定表.
我們以自己的資料庫為例,假設我們的資料庫的實體為"Oracle"
可以通過"任務管理器---->服務"中查看自己的資料庫實體
一般資訊是 已啟用 自動 本地系統
打開cmd命令列 :
1: 將資料庫Oracle完全匯出,用戶名system密碼manager匯出到 c:\daochu.dmp中
exp system/manager@Oracle file=c:\daochu.dmp full=y
2: 將資料庫中RFD用戶與,JYZGCX用戶的表匯出
exp system/manager@ORACLE file=d:\daochu.dmp owner=(RFD,JYZGCX)
3: 將資料庫中的表T_USER,T_ROLE匯出
ystem為用戶名,manager為密碼,ORACLE為資料庫實體名,其實不一定非的用system用戶,只要是擁有管理員權限的用戶都可以
exp JYZGCX/JYZGCX@Oracle file = d:\data\newsmgnt.dmp tables = (T_USER,T_ROLE)
dmp檔案的匯入
步驟如下:
機器環境是windows7,其實也無所謂,命令列不都是樣的么
1. 打開"開始" --->輸入cmd,打開cmd命令視窗,輸入: sqlplus/as sysdba; 然后使用conn / as sysdba;這樣就可以以超級管理員的最高權限登錄,當然這決定于init.ora檔案中的資料庫初始化引數.
2. 上面sysdba登錄后,就可以創建表空間和用戶了.
(打開"開始"-->輸入cmd-->sqlplus/nolog; 輸入conn/as sysdba 管理員賬戶登錄;)
由于我們已經有dmp檔案了,可以用notepad++ 打開dmp檔案,進去按ctrl+f 去查找tablespace,可以找到這個dmp檔案對應的表空間,然后根據表空間的資訊去創建表空間,這樣才能匯入dmp檔案.
然后就是創建表空間,命令如下:
create tablespace USERS
logging
datefile 'D:\oracle\product\10.2.0\oradata\orcl\USERS.dnf'
size 32m
autoxtend on
next 32m maxsize 2048m
extend management local;
創建test用戶,密碼也是test222,使用上面創建的表空間
create user test identifiles by test222
default tablespace USERS
給創建的test用戶分配權限,為了方便可以直接分配dba權限
grant dba to test;
這樣一來,我們前期的準備作業就完成了,然后就可以關掉剛剛的命令視窗了.
打開"開始" --->輸入cmd(是cmd視窗不是sqlplus視窗)
由于上面的步驟中,創建了test用戶,所以我們往test用戶去匯入資料
直接輸入如下的陳述句:
imp test/test222@localhost/orcl file="C:\Users\xiejiachen\Desktop\test20190630.DMP" full =y;
下面解釋一下上面的陳述句:
test是上面創建的登錄資料庫的用戶名
test222是上面的登錄資料庫的密碼
localhost: 代表你的資料庫是本機還是遠程匯入,需要的可以隨時替換ip地址
orcl: 是實體的名稱
file: 后面是你的dmp的檔案路徑
full=y : 全部匯入
以上就是oracle資料庫匯出和匯入dmp檔案的兩種方法.
2、資料泵方法:
創建directory:
expdp(impdp) username/password@SERVICENAME:1521
schemas=username dumpfile=file1.dmp logfile=file1.log
directory=testdata1 remap_schema=test:test;
資料庫匯出舉例:
expdp xinxiaoyong/123456@127.0.0.1:1521 schemas=xinxiaoyong dumpfile=test.dmp
logfile=test.log directory=testdata1;
exp:匯出命令,匯出時必寫,
imp:匯入命令,匯入時必寫,每次操作,二者只能選擇一個執行,
username:匯出資料的用戶名,必寫;
password:匯出資料的密碼,必寫;
@:地址符號,必寫;
SERVICENAME:Oracle的服務名,必寫;
1521:埠號,1521是默認的可以不寫,非默認要寫;
schemas:匯出操作的用戶名;
dumpfile:匯出的檔案;
logfile:匯出的日志檔案,可以不寫;
directory:創建的檔案夾名稱;
remap_schema=源資料庫用戶名:目標資料庫用戶名,二者不同時必寫,相同可以省略;
1.查看表空間:
select * from dba_tablespaces;
2.查看管理理員目錄(同時查看作業系統是否存在,因為Oracle并不關心該目錄是否存在,如果不存在,則出錯),
select * from dba_directories;
3.創建邏輯目錄,該命令不會在作業系統創建真正的目錄,最好以system等管理員創建,
create directory testdata1 as 'd:\test\dump';
4.給xinxiaoyong用戶賦予在指定目錄的操作權限,最好以system等管理員賦予,
//xinxiaoyong 是用戶名(123456是用戶密碼)
grant read,write on directory testdata1 to xinxiaoyong;
5.匯出資料
1)按用戶導
expdp xinxiaoyong/123456@orcl schemas=xinxiaoyong dumpfile=expdp.dmp directory=testdata1;
2)并行行程
parallel expdp xinxiaoyong/123456@orcl
directory=testdata1 dumpfile=xinxiaoyong3.dmp parallel=40 job_name=xinxiaoyong3
3)按表名導
expdp xinxiaoyong/123456@orcl tables=emp,dept dumpfile=expdp.dmp directory=testdata1;
4)按查詢條件導
expdp xinxiaoyong/123456@orcl
directory=testdata1 dumpfile=expdp.dmp tables=emp query='WHERE deptno=20';
5)按表空間導
expdp system/manager directory=testdata1 dumpfile=tablespace.dmp tablespaces=temp,example;
6)導整個資料庫
expdp system/manager directory=testdata1 dumpfile=full.dmp FULL=y;
6.還原資料
1)導到指定用戶下
impdp xinxiaoyong/123456 directory=testdata1 dumpfile=expdp.dmp schemas=xinxiaoyong;
2)改變表的
owner impdp system/manager
directory=testdata1 dumpfile=expdp.dmp tables=xinxiaoyong.dept remap_schema =xinxiaoyong:system;
3)匯入表空間
impdp system/manager directory=testdata1 dumpfile=tablespace.dmp tablespaces=example;
4)匯入資料庫
impdb system/manager directory=dump_dir dumpfile=full.dmp FULL=y;
5)追加資料
impdp system/manager
directory=testdata1 dumpfile=expdp.dmp schemas=system table_exists_action;
3、PLSQL方法:
登錄plsql工具,所使用用戶為源資料庫有匯出權限(exp_full_database,dba等)的用戶,
? 1.匯出建表陳述句(包括存盤結構)
? 匯出步驟tools ->export user object,選擇要匯出的物件,匯出.sql格式檔案并等待匯出完成,如 下圖:
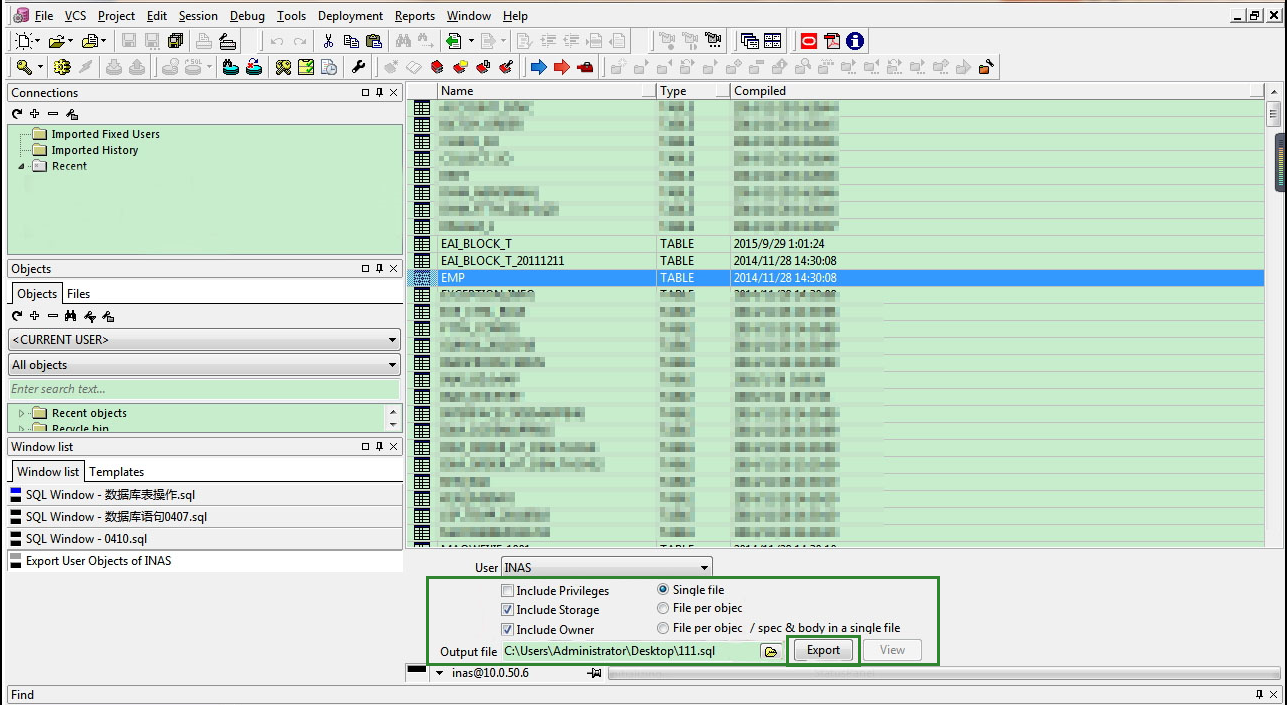
匯出資料檔案 ;
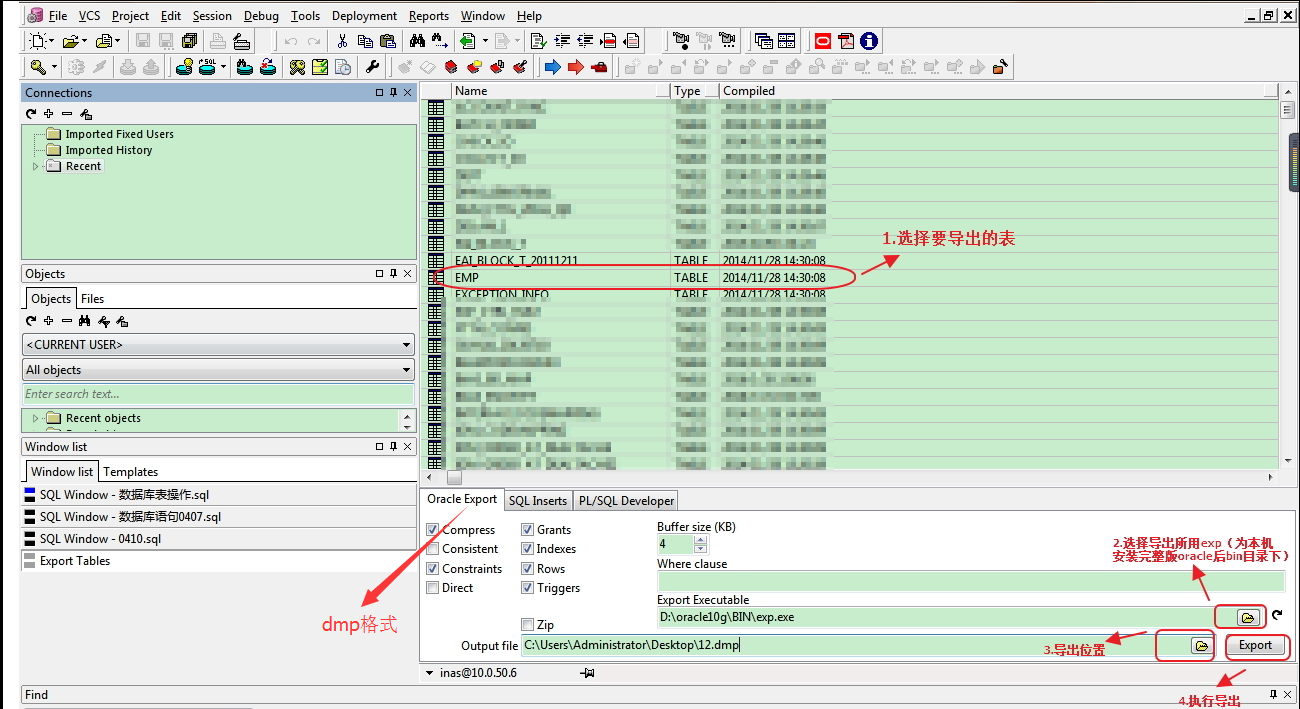
?? 2.匯出步驟tools ->export tables,選擇要匯出的表及匯出的格式進行匯出,
?? 匯出為dmp格式,如下圖:
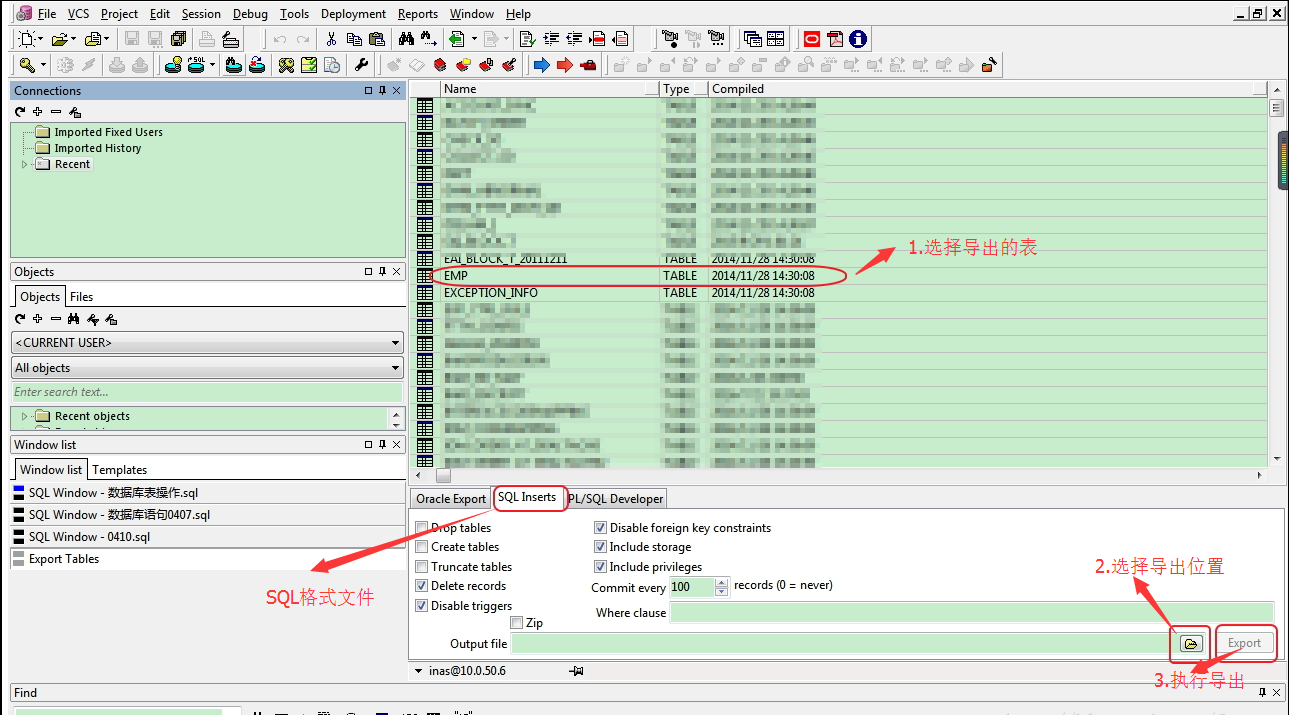
匯出為sql格式,如下圖:
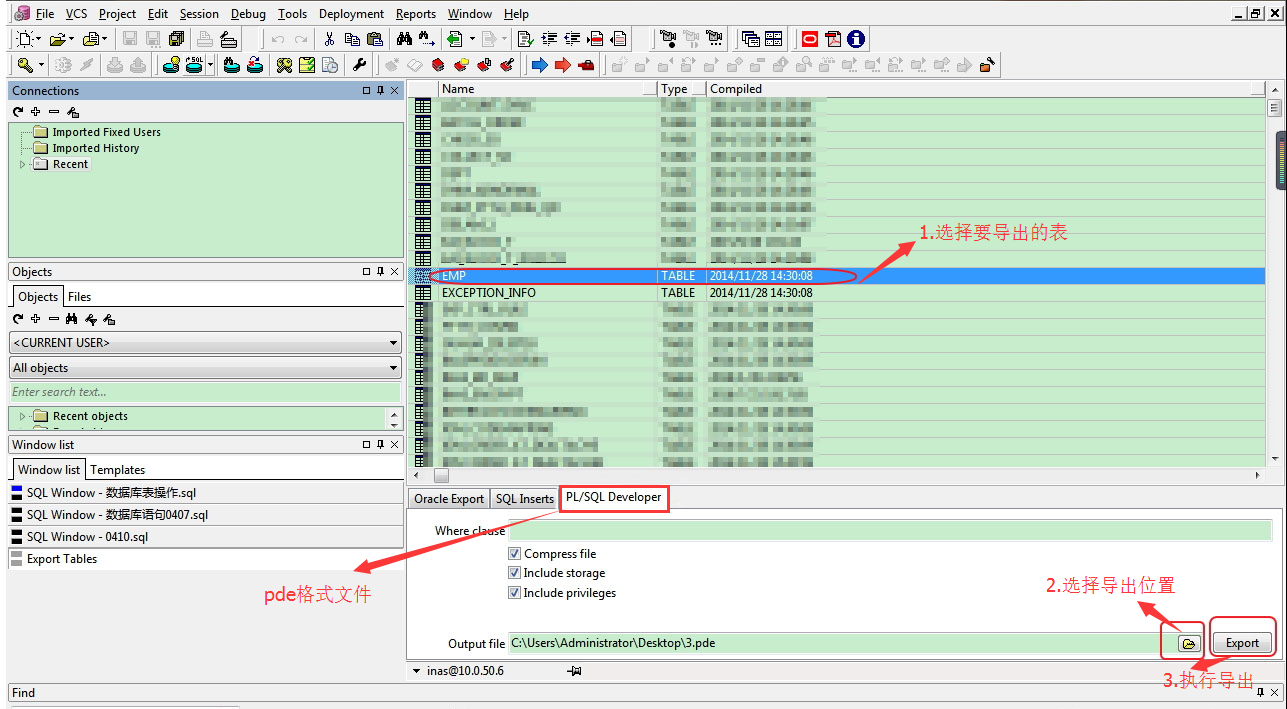
匯出為pde格式,如下圖:
提示說明:采用第三方工具匯出匯入整個資料庫的話,耗時較長,一定要有足夠
的時間來操作(資料量大的話需要好幾個小時),
3.匯入建表陳述句
?? 匯入步驟tools->import tables->SQL Inserts 匯入.sql檔案
4.匯入資料;
?? tools->import talbes,然后再根據匯出的資料格式選擇匯入dmp檔案,或者sql檔案,
或者pde檔案,
?? 提示說明:匯入之前最好把以前的表洗掉,當然匯入另外資料庫除外,
????? 另外匯入時當發現進度條一直卡在一個點,而且匯出的檔案不再增大時,甚至是提示程式
未回應,千萬不要以為程式卡死了,這個匯入匯出就是比較緩慢,只要沒有提示報錯,
或者匯入完成就不要停止程式,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/196093.html
標籤:其他
上一篇:Redis 安裝與部署