一、什么是Presto?
- 背景知識:Hive的缺點和Presto的背景
Hive使用MapReduce作為底層計算框架,是專為批處理設計的,但隨著資料越來越多,使用Hive進行一個簡單的資料查詢可能要花費幾分到幾小時,顯然不能滿足互動式查詢的需求,Presto是一個分布式SQL查詢引擎,它被設計為用來專門進行高速、實時的資料分析,它支持標準的ANSI SQL,包括復雜查詢、聚合(aggregation)、連接(join)和視窗函式(window functions),這其中有兩點就值得探究,首先是架構,其次自然是怎么做到低延遲來支持及時互動,
- PRESTO是什么?
Presto是一個開源的分布式SQL查詢引擎,適用于互動式分析查詢,資料量支持GB到PB位元組,Presto的設計和撰寫完全是為了解決像Facebook這樣規模的商業資料倉庫的互動式分析和處理速度的問題,
- 它可以做什么?
Presto支持在線資料查詢,包括Hive, Cassandra, 關系資料庫以及專有資料存盤, 一條Presto查詢可以將多個資料源的資料進行合并,可以跨越整個組織進行分析,Presto以分析師的需求作為目標,他們期望回應時間小于1秒到幾分鐘, Presto終結了資料分析的兩難選擇,要么使用速度快的昂貴的商業方案,要么使用消耗大量硬體的慢速的“免費”方案,
- 誰在使用它?
Facebook使用Presto進行互動式查詢,用于多個內部資料存盤,包括300PB的資料倉庫, 每天有1000多名Facebook員工使用Presto,執行查詢次數超過30000次,掃描資料總量超過1PB,領先的互聯網公司包括Airbnb和Dropbox都在使用Presto,
二、Presto的體系架構
Presto是一個運行在多臺服務器上的分布式系統, 完整安裝包括一個coordinator和多個worker, 由客戶端提交查詢,從Presto命令列CLI提交到coordinator, coordinator進行決議,分析并執行查詢計劃,然后分發處理佇列到worker,
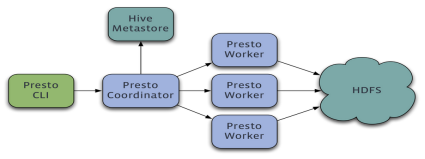
Presto查詢引擎是一個Master-Slave的架構,由一個Coordinator節點,一個Discovery Server節點,多個Worker節點組成,Discovery Server通常內嵌于Coordinator節點中,Coordinator負責決議SQL陳述句,生成執行計劃,分發執行任務給Worker節點執行,Worker節點負責實際執行查詢任務,Worker節點啟動后向Discovery Server服務注冊,Coordinator從Discovery Server獲得可以正常作業的Worker節點,如果配置了Hive Connector,需要配置一個Hive MetaStore服務為Presto提供Hive元資訊,Worker節點與HDFS互動讀取資料,
三、安裝Presto Server
- 安裝介質
presto-cli-0.217-executable.jar presto-server-0.217.tar.gz
- 安裝配置Presto Server
1、解壓安裝包
tar -zxvf presto-server-0.217.tar.gz -C ~/training/
2、創建etc目錄
cd ~/training/presto-server-0.217/ mkdir etc
3、需要在etc目錄下包含以下組態檔
Node Properties: 節點的配置資訊 JVM Config: 命令列工具的JVM配置引數 Config Properties: Presto Server的配置引數 Catalog Properties: 資料源(Connectors)的配置引數 Log Properties:日志引數配置
- 編輯node.properties
#集群名稱,所有在同一個集群中的Presto節點必須擁有相同的集群名稱, node.environment=production #每個Presto節點的唯一標示,每個節點的node.id都必須是唯一的,在Presto進行重啟或者升級程序中每個節點的node.id必須保持不變,如果在一個節點上安裝多個Presto實體(例如:在同一臺機器上安裝多個Presto節點),那么每個Presto節點必須擁有唯一的node.id, node.id=ffffffff-ffff-ffff-ffff-ffffffffffff # 資料存盤目錄的位置(作業系統上的路徑),Presto將會把日期和資料存盤在這個目錄下, node.data-dir=/root/training/presto-server-0.217/data
- 編輯jvm.config
由于OutOfMemoryError將會導致JVM處于不一致狀態,所以遇到這種錯誤的時候我們一般的處理措施就是收集dump headp中的資訊(用于debugging),然后強制終止行程,Presto會將查詢編譯成位元組碼檔案,因此Presto會生成很多class,因此我們我們應該增大Perm區的大小(在Perm中主要存盤class)并且要允許Jvm class unloading,
-server -Xmx16G -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:+UseGCOverheadLimit -XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError -XX:+ExitOnOutOfMemoryError
- 編輯config.properties
coordinator的配置
coordinator=true node-scheduler.include-coordinator=false http-server.http.port=8080 query.max-memory=5GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery-server.enabled=true discovery.uri=http://192.168.157.226:8080
workers的配置
coordinator=false http-server.http.port=8080 query.max-memory=5GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery.uri=http://192.168.157.226:8080
如果我們想在單機上進行測驗,同時配置coordinator和worker,請使用下面的配置:
coordinator=true node-scheduler.include-coordinator=true http-server.http.port=8080 query.max-memory=5GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery-server.enabled=true discovery.uri=http://192.168.157.226:8080
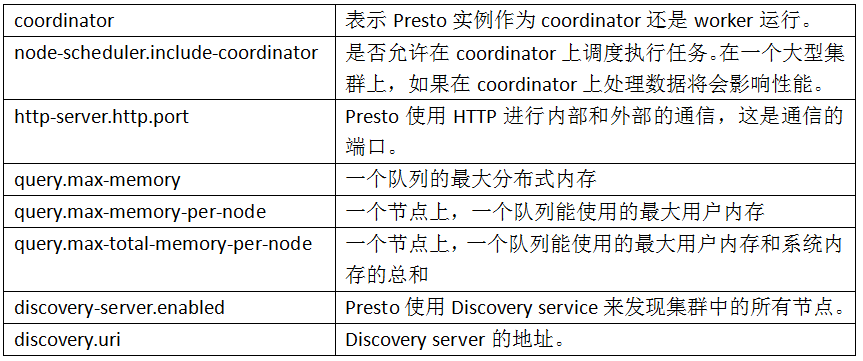
引數說明:
- 編輯log.properties
配置日志級別,
com.facebook.presto=INFO
- 配置Catalog Properties
Presto通過connectors訪問資料,這些connectors掛載在catalogs上, connector可以提供一個catalog中所有的schema和表,例如:Hive connector 將每個hive的database都映射成為一個schema,所以如果hive connector掛載到了名為hive的catalog, 并且在hive的web有一張名為clicks的表, 那么在Presto中可以通過hive.web.clicks來訪問這張表,通過在etc/catalog目錄下創建catalog屬性檔案來完成catalogs的注冊, 如果要創建hive資料源的連接器,可以創建一個etc/catalog/hive.properties檔案,檔案中的內容如下,完成在hivecatalog上掛載一個hiveconnector,
#注明hadoop的版本 connector.name=hive-hadoop2 #hive-site中配置的地址 hive.metastore.uri=thrift://192.168.157.226:9083 #hadoop的組態檔路徑 hive.config.resources=/root/training/hadoop-2.7.3/etc/hadoop/core-site.xml,/root/training/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
注意:要訪問Hive的話,需要將Hive的MetaStore啟動:hive --service metastore

四、啟動Presto Server
./launcher start
五、運行presto-cli
- 下載:presto-cli-0.217-executable.jar
- 重命名jar包,并增加執行權限
cp presto-cli-0.217-executable.jar presto chmod a+x presto
- 連接Presto Server
./presto --server localhost:8080 --catalog hive --schema default
六、使用Presto
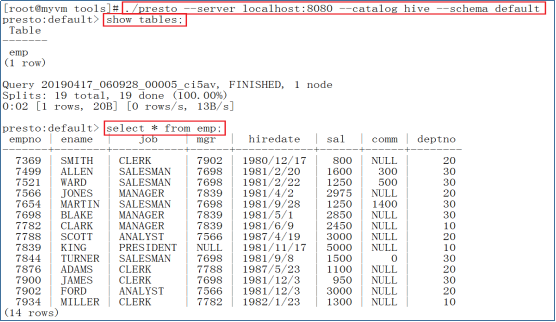
- 使用Presto操作Hive
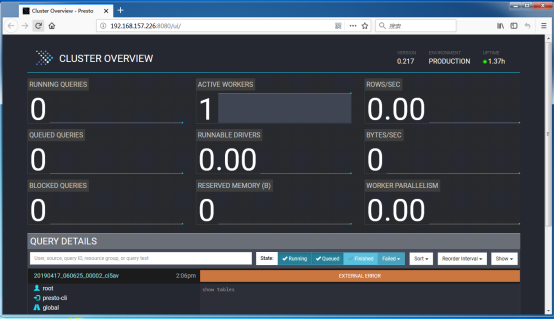
- 使用Presto的Web Console:埠:8080
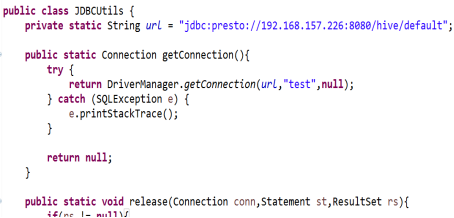
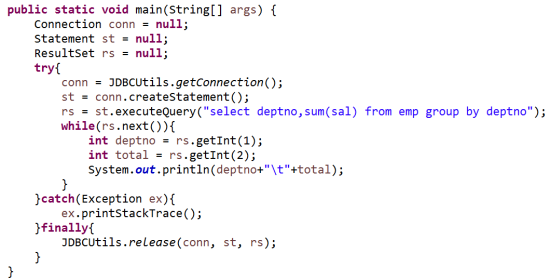
- 使用JDBC操作Presto
1、需要包含的Maven依賴
<dependency> <groupId>com.facebook.presto</groupId> <artifactId>presto-jdbc</artifactId> <version>0.217</version> </dependency>
2、JDBC代碼
*******************************************************************************************
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/19692.html
標籤:大數據
下一篇:hadoop-ha+zookeeper+hbase+hive+sqoop+flume+kafka+spark集群安裝