大資料技術開篇之Hadoop入門【hdfs】
學習都是從了解到熟悉的程序,而學習一項新的技術的時候都是從這個技術是什么?可以干什么?怎么用?如何優化?這幾點開始,今天這篇文章分為兩個部分,一、hadoop概述 二、hadoop核心技術之一的hdfs的講解,
【hadoop概述】
一、hadoop是什么?
Hadoop是一個由Apache基金會所開發的分布式系統基礎架構,用戶可以在不了解分布式底層細節的情況下,開發分布式程式,充分利用集群的威力進行高速運算和存盤,Hadoop實作了一個分布式檔案系統(Hadoop Distributed File System),簡稱HDFS,HDFS有高容錯性的特點,并且設計用來部署在低廉的(low-cost)硬體上;而且它提供高吞吐量(high throughput)來訪問應用程式的資料,適合那些有著超大資料集(large data set)的應用程式,HDFS放寬了(relax)POSIX的要求,可以以流的形式訪問(streaming access)檔案系統中的資料,Hadoop的框架最核心的設計就是:HDFS和MapReduce,HDFS為海量的資料提供了存盤,而MapReduce則為海量的資料提供了計算,
簡單概況就是hadoop是一個分布式系統的基礎架構,通過分布式來進行高速運算和存盤,
二、用來干什么?
主要用來解決海量資料存盤和海量資料運算的問題
三、當前版本
Apach 版本:主要用于自己學習研究方面,免費開源版本
Cloudera:收費版本,企業版本,目前公司商用化最多的版本,
Hortonworks:商業版本,這個版本的優勢在于參考檔案相對詳盡,學習起來比較方便
四、hadoop組成
commons:輔助工具
hdfs:一個分布式高吞吐量,高可靠的分布式檔案系統
mapreduce 一個分布式離線計算框架
yarn:作業調度和資源管理的框架,
五、集群模式
單節點模式,偽集群,完整集群,三個模式
HDFS 學習
一、hdfs是什么?
hdfs一個分布式高吞吐量,高可靠的分布式檔案系統,
二、hdfs優缺點:
優點:
【1】高容錯性,資料自動保存多個副本,一個副本丟失后可以自動恢復
【2】適合大資料的處理
資料可以達到gb,Tb,pb級別,檔案處理可以達到百萬以上的規模
【3】可以構建在廉價的機器上面,通過多副本來實作可靠性
缺點:
【1】不適合低延時資料訪問,比如毫秒級別做不到
【2】無法高效對大量小檔案進行存盤
【3】不支持檔案的隨機修改,僅支持檔案的追加
三、hdfs的組成:
Client:客戶端
【1】檔案切分,檔案上傳時將檔案切成一個個block塊
【2】與NameNode互動,獲取檔案的位置資訊
【3】與DataNode互動,讀取或寫入資料
【4】client提供一些命令來管理Hdfs,比如啟動或者關閉
【5】client可以通過命令來訪問Hdfs
NameNode就是Master,它是一個主管、管理者
【1】管理資料塊的原資訊
【2】配置副本策略
【3】處理客戶端請求
DateNode
【1】存盤實際的資料塊
【2】執行資料塊的讀寫操作
econdaryNameNode:并非NameNode的熱備,當NameNode掛掉的時候,它并不能馬上替換NameNode并提供服務
【1】輔助NameNode,分擔其作業量
【2】定期合并Fsimage和Edits,并推送給NameNode;
【3】在緊急情況下,可輔助恢復NameNode,
四、hdfs檔案寫入流程
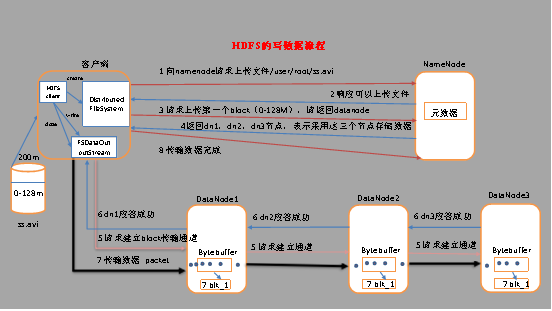
(1) 客戶端通過Distributed FileSystem模塊向NameNode請求上傳檔案,NameNode檢查目標檔案是否已存在,父目錄是否存在,
(2) NameNode回傳是否可以上傳,
(3) 客戶端請求第一個 block上傳到哪幾個datanode服務器上,
(4) NameNode回傳3個datanode節點,分別為dn1、dn2、dn3,
(5) 客戶端通過FSDataOutputStream模塊請求dn1上傳資料,dn1收到請求會繼續呼叫dn2,然后dn2呼叫dn3,將這個通信管道建立完成,
(6) dn1、dn2、dn3逐級應答客戶端,
(7) 客戶端開始往dn1上傳第一個block(先從磁盤讀取資料放到一個本地記憶體快取),以packet為單位,dn1收到一個packet就會傳給dn2,dn2傳給dn3;
(8) 當一個block傳輸完成之后,客戶端再次請求NameNode上傳第二個block的服務器,(重復執行3-7步),
五、hdfs 讀檔案流程
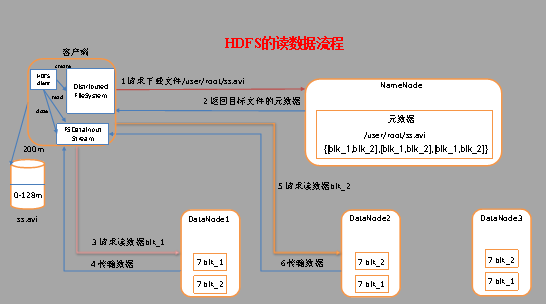
(1) 客戶端通過Distributed FileSystem向NameNode請求下載檔案,NameNode通過查詢元資料,找到檔案塊所在的DataNode地址,
(2) 挑選一臺DataNode(就近原則,然后隨機)服務器,請求讀取資料,
(3) DataNode開始傳輸資料給客戶端(從磁盤里面讀取資料輸入流,以packet為單位來做校驗),
(4) 客戶端以packet為單位接收,先在本地快取,然后寫入目標檔案,
六、NN與2NN的作業機制
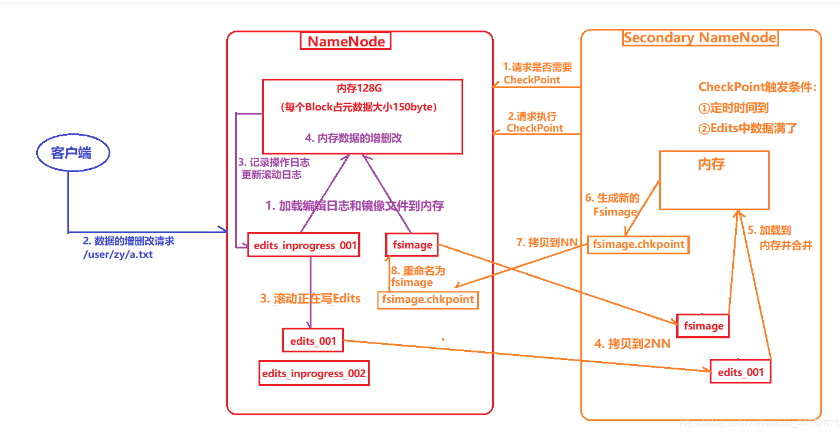
(1) 第一階段:NameNode啟動
a) 第一次啟動NameNode格式化后,創建fsimage和edits檔案,如果不是第一次啟動,直接加載編輯日志和鏡像檔案到記憶體,
b) 客戶端對元資料進行增刪改的請求,
c) NameNode記錄操作日志,更新滾動日志,
d) NameNode在記憶體中對資料進行增刪改查,
(2) 第二階段:Secondary NameNode作業
a) Secondary NameNode詢問NameNode是否需要checkpoint,直接帶回NameNode是否檢查結果,
b) Secondary NameNode請求執行checkpoint,
c) NameNode滾動正在寫的edits日志,
d) 將滾動前的編輯日志和鏡像檔案拷貝到Secondary NameNode,
e) Secondary NameNode加載編輯日志和鏡像檔案到記憶體,并合并,
f) 生成新的鏡像檔案fsimage.chkpoint,
g) 拷貝fsimage.chkpoint到NameNode,
h) NameNode將fsimage.chkpoint重新命名成fsimage,
NN和2NN作業機制詳解:
fsimage:namenode記憶體中元資料序列化后形成的檔案,
edits:記錄客戶端更新元資料資訊的每一步操作(可通過Edits運算出元資料),
namenode啟動時,先滾動edits并生成一個空的edits.inprogress,然后加載edits(歸檔后的)和fsimage(最新的)到記憶體中,此時namenode記憶體就持有最新的元資料資訊,client開始對namenode發送元資料的增刪改查的請求,這些請求的操作首先會被記錄在edits.inprogress中(查詢元資料的操作不會被記錄在edits中,因為查詢操作不會更改元資料資訊),如果此時namenode掛掉,重啟后會從edits中讀取元資料的資訊,然后,namenode會在記憶體中執行元資料的增刪改查的操作,
由于edits中記錄的操作會越來越多,edits檔案會越來越大,導致namenode在啟動加載edits時會很慢,所以需要對edits和fsimage進行合并(所謂合并,就是將edits和fsimage加載到記憶體中,照著edits中的操作一步步執行,最終形成新的fsimage),Secondarynamenode:幫助namenode進行edits和fsimage的合并作業,
secondarynamenode首先會詢問namenode是否需要checkpoint(觸發checkpoint需要滿足兩個條件中的任意一個,定時時間到和edits中資料寫滿了),直接帶回namenode是否檢查結果,secondarynamenode執行checkpoint操作,首先會讓namenode滾動edits并生成一個空的edits.inprogress,滾動edits的目的是給edits打個標記,以后所有新的操作都寫入edits.inprogress,其他未合并的edits和fsimage會拷貝到secondarynamenode的本地,然后將拷貝的edits和fsimage加載到記憶體中進行合并,生成fsimage.chkpoint,然后將fsimage.chkpoint拷貝給namenode,重命名為fsimage后替換掉原來的fsimage,namenode在啟動時就只需要加載之前未合并的edits和fsimage即可,因為合并過的edits中的元資料資訊已經被記錄在fsimage中,
六、DataName作業機制
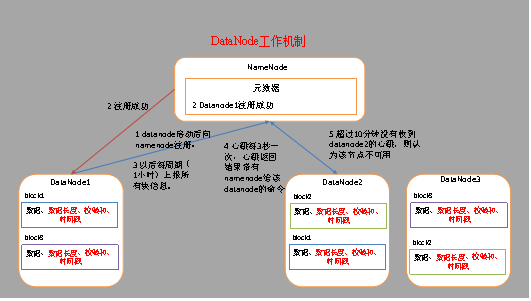
(1) 一個資料塊在DataNode上以檔案形式存盤在磁盤上,包括兩個檔案,一個是資料本身,一個是元資料包括資料塊的長度,塊資料的校驗和,以及時間戳,
(2) DataNode啟動后向NameNode注冊,通過后,周期性(1小時)的向NameNode上報所有的塊資訊,
(3) 心跳是每3秒一次,心跳回傳結果帶有NameNode給該DataNode的命令如復制塊資料到另一臺機器,或洗掉某個資料塊,如果超過10分鐘沒有收到某個DataNode的心跳,則認為該節點不可用,
今天的hdfs的分享就到這里了,下次會分享MapReduce和Yarn的知識,每天進步一點點,大家一起加油,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/19715.html
標籤:大數據
上一篇:全球疫情實時監控——約翰斯·霍普金斯大學資料大屏實作方案
下一篇:50道SQL面試題