位置
find / -name redis.conf
units單位
# Redis configuration file example.
#
# Note that in order to read the configuration file, Redis must be
# started with the file path as first argument:
#
# ./redis-server /path/to/redis.conf
# Note on units: when memory size is needed, it is possible to specify
# it in the usual form of 1k 5GB 4M and so forth:
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# units are case insensitive so 1GB 1Gb 1gB are all the same.
配置大小單位,開頭定義了一些基本的度量單位,不支持bit
對大小寫不敏感
includes包含
# Include one or more other config files here. This is useful if you
# have a standard template that goes to all Redis servers but also need
# to customize a few per-server settings. Include files can include
# other files, so use this wisely.
#
# Notice option "include" won't be rewritten by command "CONFIG REWRITE"
# from admin or Redis Sentinel. Since Redis always uses the last processed
# line as value of a configuration directive, you'd better put includes
# at the beginning of this file to avoid overwriting config change at runtime.
#
# If instead you are interested in using includes to override configuration
# options, it is better to use include as the last line.
#
# include /path/to/local.conf
# include /path/to/other.conf
network
################################## NETWORK #####################################
# TCP listen() backlog.
#
# In high requests-per-second environments you need an high backlog in order
# to avoid slow clients connections issues. Note that the Linux kernel
# will silently truncate it to the value of /proc/sys/net/core/somaxconn so
# make sure to raise both the value of somaxconn and tcp_max_syn_backlog
# in order to get the desired effect.
tcp-backlog 511
設定tcp的backlog,backlog其實是一個連接佇列,backlog佇列總和=未完成三次握手佇列+已完成三次握手佇列.
在高并發環境下你需要一個高的backlog值來避免慢客戶端連接問題.
注意linux內核會將這個值減小到/proc/sys/net/core/somaxconn的值,所以需要確認增大somaxconn和tcp_max_syn_backlog兩個值來達到想要的效果
# Close the connection after a client is idle for N seconds (0 to disable)
timeout 0
超時時間設定,0為關閉
# TCP keepalive.
#
# If non-zero, use SO_KEEPALIVE to send TCP ACKs to clients in absence
# of communication. This is useful for two reasons:
#
# 1) Detect dead peers.
# 2) Take the connection alive from the point of view of network
# equipment in the middle.
#
# On Linux, the specified value (in seconds) is the period used to send ACKs.
# Note that to close the connection the double of the time is needed.
# On other kernels the period depends on the kernel configuration.
#
# A reasonable value for this option is 300 seconds, which is the new
# Redis default starting with Redis 3.2.1.
tcp-keepalive 300
單位為秒,如果設定為0,則不會進行keepalive檢測,建議設定成60
general通用
# 是否以守護進行
daemonize no
# 行程管道id檔案,如果沒有指定,則在這個路徑下
pidfile /var/run/redis_6379.pid
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
# 日志級別
loglevel notice
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
# 日志名字
loglevel notice
# To enable logging to the system logger, just set 'syslog-enabled' to yes,
# and optionally update the other syslog parameters to suit your needs.
# 是否把日志輸出到syslog中
# syslog-enabled no
# Specify the syslog identity.
# 指定syslog里的日志表示
# syslog-ident redis
# Specify the syslog facility. Must be USER or between LOCAL0-LOCAL7.
# syslog-facility local0
# Specify the syslog identity.
# syslog-ident redis
# Specify the syslog facility. Must be USER or between LOCAL0-LOCAL7.
# 指定syslog設備,值可以是user或者local0-local7
# syslog-facility local0
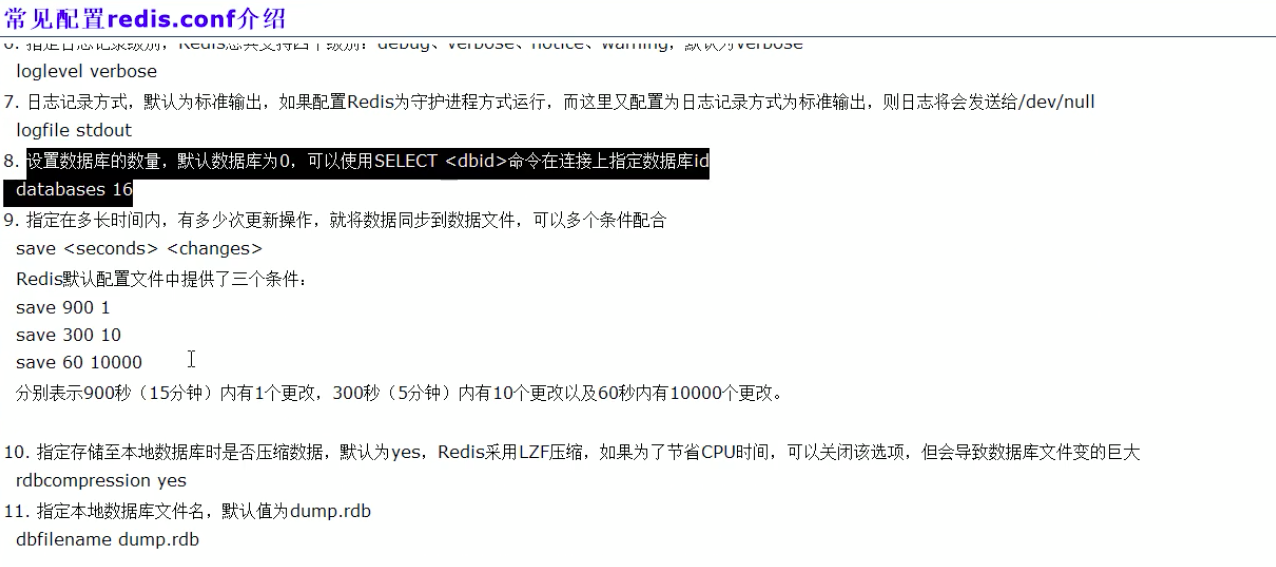
# Set the number of databases. The default database is DB 0, you can select
# a different one on a per-connection basis using SELECT <dbid> where
# dbid is a number between 0 and 'databases'-1
# 默認有16個資料庫
databases 16
snapshotting快照
################################ SNAPSHOTTING ################################
#
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
# flushall和shutdown會立即出發save命令,進行備份
# 禁用RDB持久化策略,只要不設定任何save指令(在redis的命令視窗中使用save命令)或者使用下面的save ""也可以(save傳入一個空字串引數也可以)
# save ""
# 下面三個條件符合其一就觸發備份
# 900秒內有一個key改變過就備份
save 900 1
# 300秒內有10個key改變過就備份
save 300 10
# 60秒內有10000個key改變就觸發備份
save 60 10000
# By default Redis will stop accepting writes if RDB snapshots are enabled
# (at least one save point) and the latest background save failed.
# This will make the user aware (in a hard way) that data is not persisting
# on disk properly, otherwise chances are that no one will notice and some
# disaster will happen.
#
# If the background saving process will start working again Redis will
# automatically allow writes again.
#
# However if you have setup your proper monitoring of the Redis server
# and persistence, you may want to disable this feature so that Redis will
# continue to work as usual even if there are problems with disk,
# permissions, and so forth.
# 如何配置成no,表示不在乎資料不一致或者其他的手段發現和控制
stop-writes-on-bgsave-error yes
# Compress string objects using LZF when dump .rdb databases?
# For default that's set to 'yes' as it's almost always a win.
# If you want to save some CPU in the saving child set it to 'no' but
# the dataset will likely be bigger if you have compressible values or keys.
# 對于存盤到磁盤中的快照,可以設定是否進行壓縮存盤.
# 如果是的話,redis會采用LZF演算法進行壓縮.
# 如果不想消耗CPU進行要鎖,可以設定為關閉此功能
rdbcompression yes
# Since version 5 of RDB a CRC64 checksum is placed at the end of the file.
# This makes the format more resistant to corruption but there is a performance
# hit to pay (around 10%) when saving and loading RDB files, so you can disable it
# for maximum performances.
#
# RDB files created with checksum disabled have a checksum of zero that will
# tell the loading code to skip the check.
# 在存盤快照后,還可以讓redis使用CRC64演算法來進行資料檢驗
# 這樣做會增加10%的性能消耗,
# 如果想獲得最大的性能提升,則可以關閉此功能
rdbchecksum yes
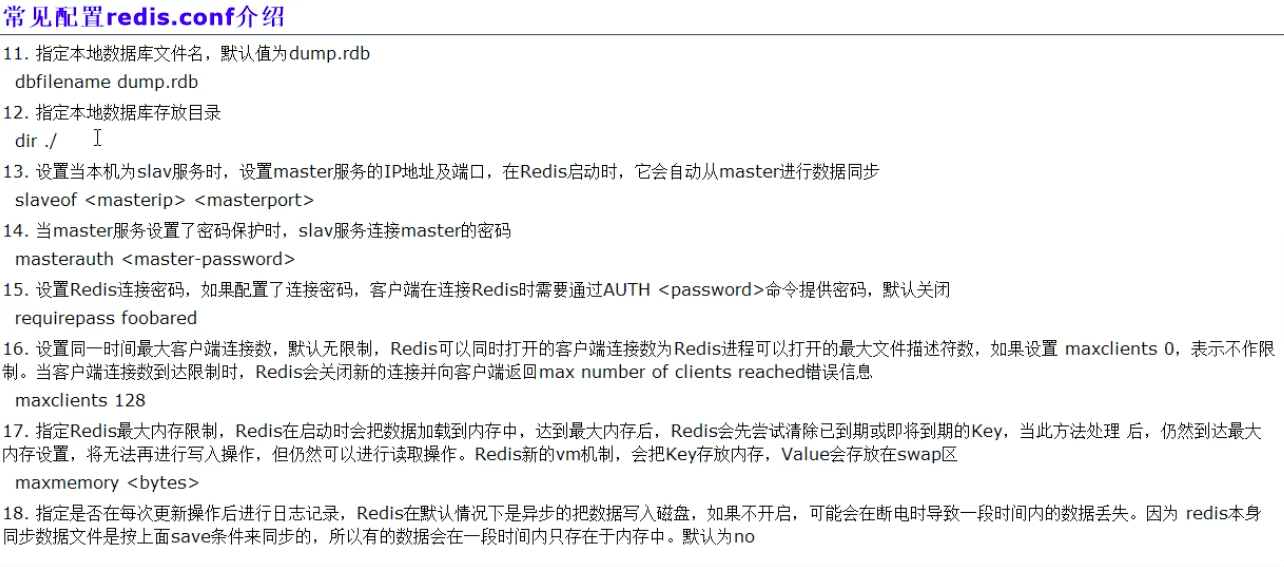
# The filename where to dump the DB
# 保存時的檔案名稱,斷電重啟時讀取的檔案名稱
dbfilename dump.rdb
# The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
# 作業目錄
dir ./
replication復制
security安全
# 獲取登錄密碼
config get requirepass
127.0.0.1:8686> config get requirepass
1) "requirepass"
2) "51310400"
# 查詢啟動時所在的目錄
config get dir
127.0.0.1:8686> config get dir
1) "dir"
2) "/alidata/redis-5.0.3/db"
# 設定redis密碼
config set requirepass 123456
# 登錄redis
[root@izm5e2q95pbpe1hh0kkwoiz /]# redis-cli -p 8686
127.0.0.1:8686> ping
(error) NOAUTH Authentication required.
127.0.0.1:8686> auth 51310400
OK
127.0.0.1:8686> ping
PONG
CLIENTS
# Set the max number of connected clients at the same time. By default
# this limit is set to 10000 clients, however if the Redis server is not
# able to configure the process file limit to allow for the specified limit
# the max number of allowed clients is set to the current file limit
# minus 32 (as Redis reserves a few file descriptors for internal uses).
#
# Once the limit is reached Redis will close all the new connections sending
# an error 'max number of clients reached'.
# 最大連接數10000
# maxclients 10000
limits限制
# 最大記憶體
# maxmemory <bytes>
## 達到最大記憶體時清除策略
# MAXMEMORY POLICY: how Redis will select what to remove when maxmemory
# is reached. You can select among five behaviors:
#
## 使用LUR演算法移除key,只對設定了過期時間的鍵.LRU最近最少使用演算法
# volatile-lru -> Evict using approximated LRU among the keys with an expire set.
## 使用LRU演算法移除key
# allkeys-lru -> Evict any key using approximated LRU.
# volatile-lfu -> Evict using approximated LFU among the keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
## 在過期集合中移除隨機的key,只對設定了過期時間的鍵
# volatile-random -> Remove a random key among the ones with an expire set.
## 移除隨機的key
# allkeys-random -> Remove a random key, any key.
## 移除那些ttl值最小的key,即那些最近要過期的key
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
## 不進行移除.針對寫操作,只是回傳錯誤資訊
# noeviction -> Don't evict anything, just return an error on write operations.
#
# LRU means Least Recently Used
# LFU means Least Frequently Used
#
# Both LRU, LFU and volatile-ttl are implemented using approximated
# randomized algorithms.
#
# Note: with any of the above policies, Redis will return an error on write
# operations, when there are no suitable keys for eviction.
#
# At the date of writing these commands are: set setnx setex append
# incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd
# sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby
# zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby
# getset mset msetnx exec sort
#
# The default is:
# 默認配置是不清除,但是配置沒有開啟
# maxmemory-policy noeviction
# LRU, LFU and minimal TTL algorithms are not precise algorithms but approximated
# algorithms (in order to save memory), so you can tune it for speed or
# accuracy. For default Redis will check five keys and pick the one that was
# used less recently, you can change the sample size using the following
# configuration directive.
#
# The default of 5 produces good enough results. 10 Approximates very closely
# true LRU but costs more CPU. 3 is faster but not very accurate.
# 設定樣本你數量,LRU演算法和最小TTL演算法都并非是精確的演算法,而是估算值,醉意可以設定樣本的大小.redis默認會檢查這么多個key并選擇其中LRU的那個
# maxmemory-samples 5
append only mode追加
############################## APPEND ONLY MODE ###############################
# By default Redis asynchronously dumps the dataset on disk. This mode is
# good enough in many applications, but an issue with the Redis process or
# a power outage may result into a few minutes of writes lost (depending on
# the configured save points).
#
# The Append Only File is an alternative persistence mode that provides
# much better durability. For instance using the default data fsync policy
# (see later in the config file) Redis can lose just one second of writes in a
# dramatic event like a server power outage, or a single write if something
# wrong with the Redis process itself happens, but the operating system is
# still running correctly.
#
# AOF and RDB persistence can be enabled at the same time without problems.
# If the AOF is enabled on startup Redis will load the AOF, that is the file
# with the better durability guarantees.
#
# Please check http://redis.io/topics/persistence for more information.
# 默認是關閉狀態
appendonly no
# The name of the append only file (default: "appendonly.aof")
# 備份檔案的名字
appendfilename "appendonly.aof"
# The fsync() call tells the Operating System to actually write data on disk
# instead of waiting for more data in the output buffer. Some OS will really flush
# data on disk, some other OS will just try to do it ASAP.
#
# Redis supports three different modes:
#
# no: don't fsync, just let the OS flush the data when it wants. Faster.
# always: fsync after every write to the append only log. Slow, Safest.
# everysec: fsync only one time every second. Compromise.
#
# The default is "everysec", as that's usually the right compromise between
# speed and data safety. It's up to you to understand if you can relax this to
# "no" that will let the operating system flush the output buffer when
# it wants, for better performances (but if you can live with the idea of
# some data loss consider the default persistence mode that's snapshotting),
# or on the contrary, use "always" that's very slow but a bit safer than
# everysec.
#
# More details please check the following article:
# http://antirez.com/post/redis-persistence-demystified.html
#
# If unsure, use "everysec".
# appendfsync always
# 備份時機
# always:同步持久化,每次發生資料變更會被立即就到磁盤,性能較差但資料記錄完整性比較好
# ererysec:出廠默認配置,異步操作,每秒記錄,如果一秒內宕機,有資料丟失
# no:不追加
appendfsync everysec
# When the AOF fsync policy is set to always or everysec, and a background
# saving process (a background save or AOF log background rewriting) is
# performing a lot of I/O against the disk, in some Linux configurations
# Redis may block too long on the fsync() call. Note that there is no fix for
# this currently, as even performing fsync in a different thread will block
# our synchronous write(2) call.
#
# In order to mitigate this problem it's possible to use the following option
# that will prevent fsync() from being called in the main process while a
# BGSAVE or BGREWRITEAOF is in progress.
#
# This means that while another child is saving, the durability of Redis is
# the same as "appendfsync none". In practical terms, this means that it is
# possible to lose up to 30 seconds of log in the worst scenario (with the
# default Linux settings).
#
# If you have latency problems turn this to "yes". Otherwise leave it as
# "no" that is the safest pick from the point of view of durability.
# 重寫時是否可以運用appendfsync,用默認no即可,保證資料安全性
no-appendfsync-on-rewrite no
# Automatic rewrite of the append only file.
# Redis is able to automatically rewrite the log file implicitly calling
# BGREWRITEAOF when the AOF log size grows by the specified percentage.
#
# This is how it works: Redis remembers the size of the AOF file after the
# latest rewrite (if no rewrite has happened since the restart, the size of
# the AOF at startup is used).
#
# This base size is compared to the current size. If the current size is
# bigger than the specified percentage, the rewrite is triggered. Also
# you need to specify a minimal size for the AOF file to be rewritten, this
# is useful to avoid rewriting the AOF file even if the percentage increase
# is reached but it is still pretty small.
#
# Specify a percentage of zero in order to disable the automatic AOF
# rewrite feature.
# 設定重寫的基準值,此時是上次重寫體積的100%,也就是體積翻一倍
auto-aof-rewrite-percentage 100
# 設定重寫的基準值,此時是重寫時日志要大于64MB
auto-aof-rewrite-min-size 64mb
常見配置redis.conf介紹




轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/19758.html
標籤:NoSQL
上一篇:redis中hash資料型別
下一篇:redis事務