1、正確使用索引
(1)、一 索引未命中
? 并不是說創建了索引就一定會加快查詢速度,若想利用索引達到預想的提高查詢速度的效果,在添加索引時,必須注意以下問題:
<1>、范圍問題
? 或者說條件不明確,條件中出現這些符號或關鍵字:>、>=、<、<=、!= 、between...and...、like
大于號、小于號
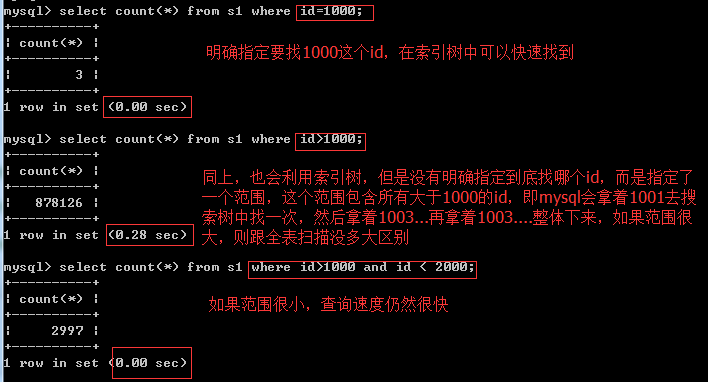
不等于 號
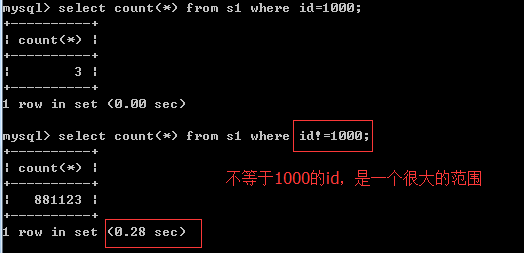
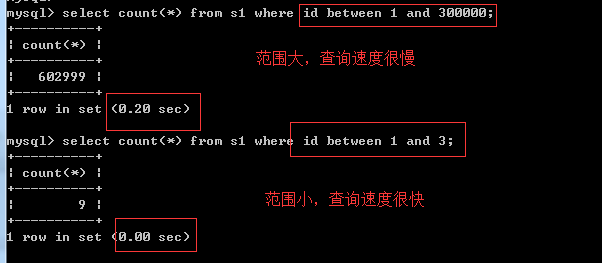
between ...and...
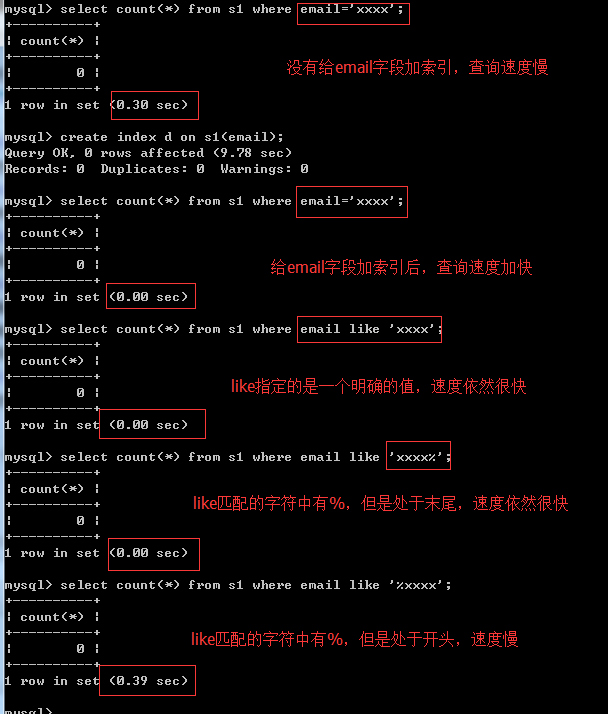
like
<2>、 盡量選擇區分度高的列作為索引
? 區分度的公式是 count( distinct col ) / count(*),表示欄位不重復的比例,比例越大我們掃描的記錄數越少,唯一鍵的區分度是1,而一些狀態、性別欄位可能在大資料面前區分度就是0,這個比例有使用場景不同,這個值也很難確定,一般需要join的欄位我們都要求是0.1以上,即平均1條掃描10條記錄
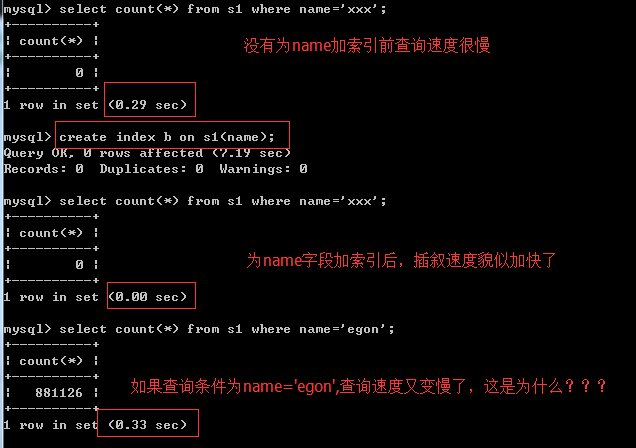
# 分析原因
我們撰寫存盤程序為表s1批量添加記錄,name欄位的值均為egon,也就是說name這個欄位的區分度很低(gender欄位也是一樣的,我們稍后再搭理它)
回憶b+樹的結構,查詢的速度與樹的高度成反比,要想將樹的高低控制的很低,需要保證:在某一層內資料項均是按照從左到右,從小到大的順序依次排開,即左1<左2<左3<...
而對于區分度低的欄位,無法找到大小關系,因為值都是相等的,毫無疑問,還想要用b+樹存放這些等值的資料,只能增加樹的高度,欄位的區分度越低,則樹的高度越高,極端的情況,索引欄位的值都一樣,那么b+樹幾乎成了一根棍,本例中就是這種極端的情況,name欄位所有的值均為'egon'
# 現在我們得出一個結論:為區分度低的欄位建立索引,索引樹的高度會很高,然而這具體會帶來什么影響呢???
# 1:如果條件是name='xxxx',那么肯定是可以第一時間判斷出'xxxx'是不在索引樹中的(因為樹中所有的值均為'egon’),所以查詢速度很快
# 2:如果條件正好是name='egon',查詢時,我們永遠無法從樹的某個位置得到一個明確的范圍,只能往下找,往下找,往下找,,,這與全表掃描的IO次數沒有多大區別,所以速度很慢
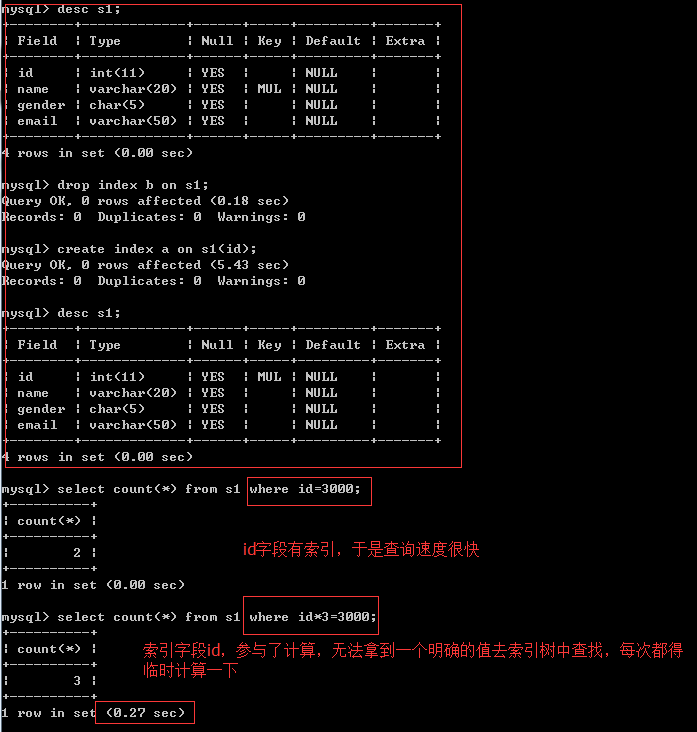
<3>、索引列不能在條件中參與計算
? 保持列“干凈”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很簡單,b+樹中存的都是資料表中的欄位值,但進行檢索時,需要把所有元素都應用函式才能比較,顯然成本太大,所以陳述句應該寫成create_time = unix_timestamp(’2014-05-29’)
<4>、and / or
# 1、and與or的邏輯
條件1 and 條件2:所有條件都成立才算成立,但凡要有一個條件不成立則最終結果不成立
條件1 or 條件2:只要有一個條件成立則最終結果就成立
# 2、and的作業原理
條件:
a = 10 and b = 'xxx' and c > 3 and d =4
索引:
制作聯合索引(d,a,b,c)
作業原理:
對于連續多個and:mysql會按照聯合索引,從左到右的順序找一個區分度高的索引欄位(這樣便可以快速鎖定很小的范圍),加速查詢,即按照d—>a->b->c的順序
# 3、or的作業原理
條件:
a = 10 or b = 'xxx' or c > 3 or d =4
索引:
制作聯合索引(d,a,b,c)
作業原理:
對于連續多個or:mysql會按照條件的順序,從左到右依次判斷,即a->b->c->d
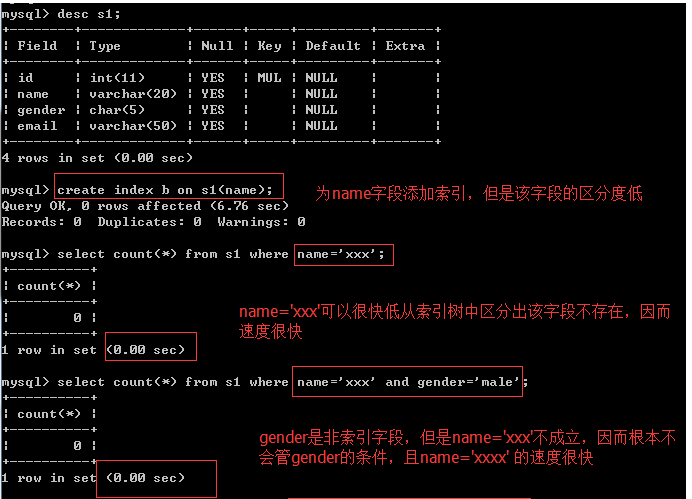
在左邊條件成立但是索引欄位的區分度低的情況下(name與gender均屬于這種情況),會依次往右找到一個區分度高的索引欄位,加速查詢
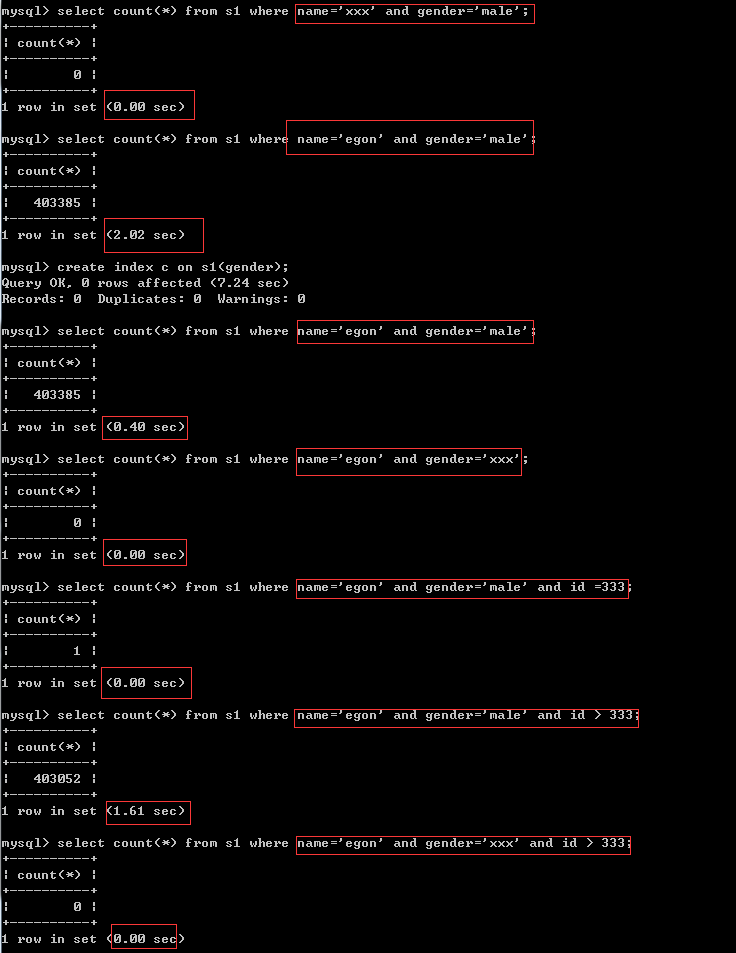
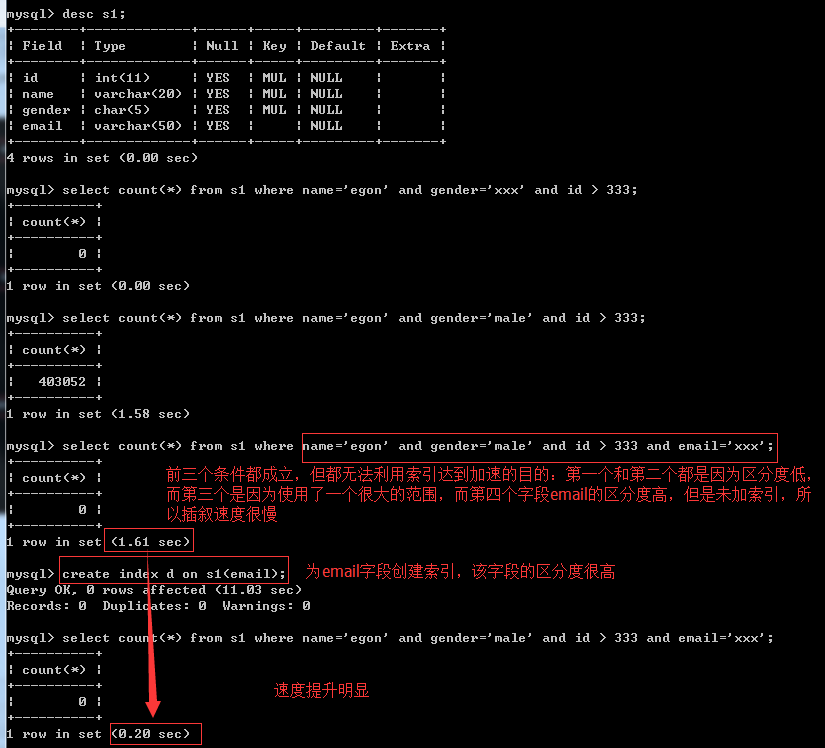
經過分析,在條件為name='egon' and gender='male' and id>333 and email='xxx'的情況下,我們完全沒必要為前三個條件的欄位加索引,因為只能用上email欄位的索引,前三個欄位的索引反而會降低我們的查詢效率
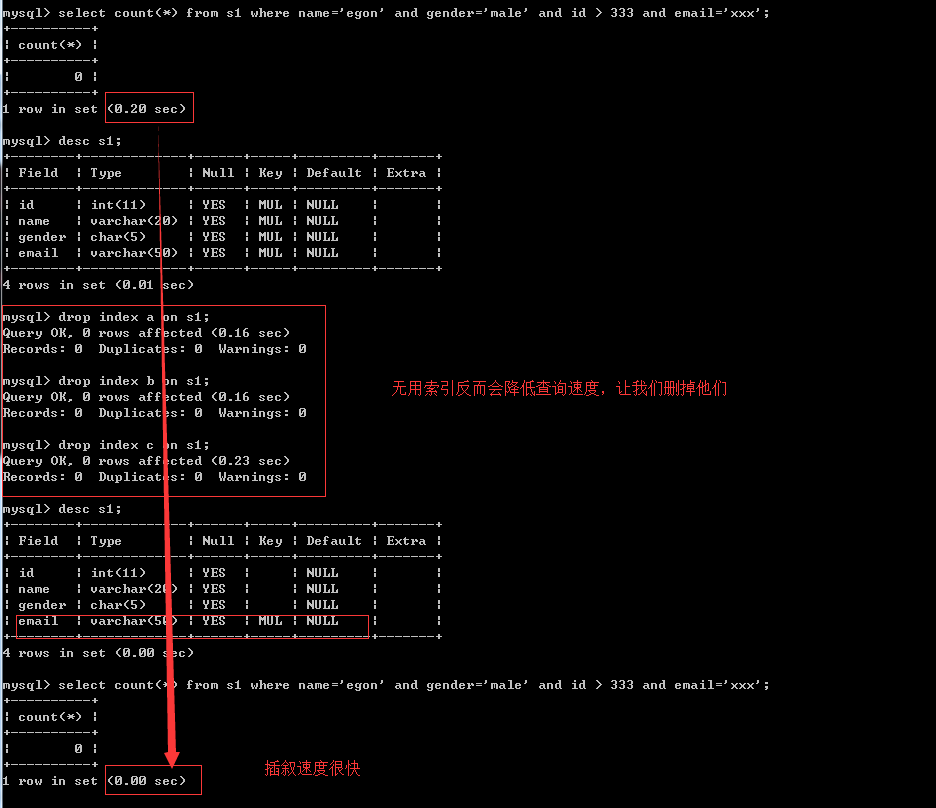
<5>、最左前綴匹配原則
? 非常重要的原則,對于組合索引mysql會一直向右匹配直到遇到范圍查詢(>、<、between、like)就停止匹配(指的是范圍大了,有索引速度也慢),比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)順序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引則都可以用到,a,b,d的順序可以任意調整,
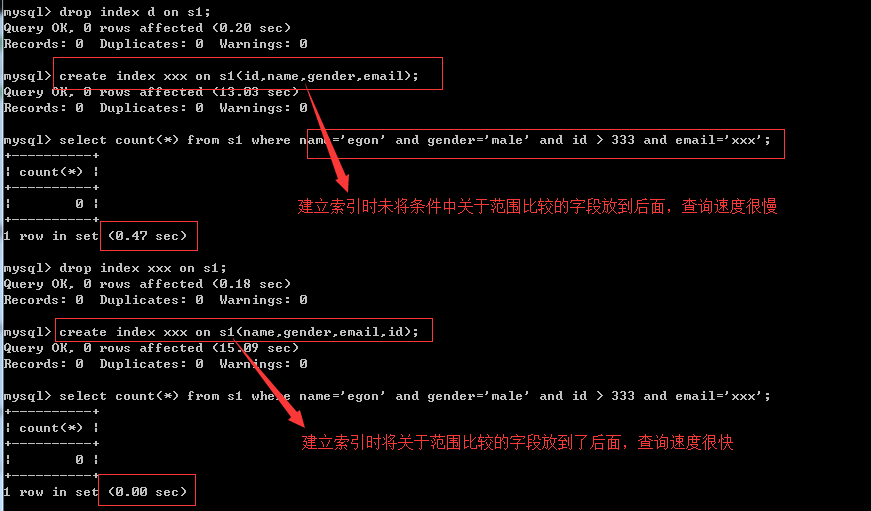
<6>、其他情況
- 使用函式
select * from tb1 where reverse(email) = 'egon';
- 型別不一致
如果列是字串型別,傳入條件是必須用引號引起來
select * from tb1 where email = 999;
# 排序條件為索引,則select欄位必須也是索引欄位,否則無法命中
- order by
select name from s1 order by email desc;
當根據索引排序時候,select查詢的欄位如果不是索引,則速度仍然很慢
select email from s1 order by email desc;
特別的:如果對主鍵排序,則還是速度很快:
select * from tb1 order by nid desc;
- 組合索引最左前綴
如果組合索引為:(name,email)
name and email -- 命中索引
name -- 命中索引
email -- 未命中索引
- count(1)或count(列)代替count(*)在mysql中沒有差別了
- create index xxxx on tb(title(19)) # text型別,必須制定長度
(2)、其他注意事項
- 避免使用 select *
- 使用 count(*)
- 創建表時盡量使用 char 代替 varchar
- 表的欄位順序固定長度的欄位優先
- 組合索引代替多個單列索引(由于mysql中每次只能使用一個索引,所以經常使用多個條件查詢時更適合使用組合索引)
- 盡量使用短索引
- 使用連接(JOIN)來代替子查詢(Sub-Queries)
- 連表時注意條件型別需一致
- 索引散列值(重復少)不適合建索引,例:性別不適合
2、 聯合索引與覆寫索引
(1)、聯合索引
? 聯合索引是指對表上的多個列合起來做一個索引,聯合索引的創建方法與單個索引的創建方法一樣,不同之處僅在于有多個索引列,如下
mysql> create table t(
-> a int,
-> b int,
-> primary key(a),
-> key idx_a_b(a,b)
-> );
Query OK, 0 rows affected (0.11 sec)
? 從本質上來說,聯合索引就是一棵B+樹,不同的是聯合索引的鍵值的數量不是1,而是>=2,接著來討論兩個整型列組成的聯合索引,假定兩個鍵值得名稱分別為a、b如圖
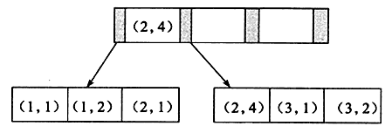
? 可以看到這與之前看到的單個鍵的B+樹并沒有什么不同,鍵值都是排序的,通過葉子結點可以邏輯上順序地讀出所有資料,就上面的例子來說,即(1,1),(1,2),(2,1),(2,4),(3,1),(3,2),資料按(a,b)的順序進行了存放,
? 因此,對于查詢 select * from table where a=xxx and b=xxx, 顯然是可以使用(a,b) 這個聯合索引的,對于單個列a的查詢 select * from table where a=xxx,也是可以使用(a,b)這個索引的,
? 但對于b列的查詢 select * from table where b=xxx,則不可以使用(a,b) 索引,其實不難發現原因,葉子節點上b的值為1、2、1、4、1、2顯然不是排序的,因此對于b列的查詢使用不到(a,b) 索引,
? 聯合索引的第二個好處是在第一個鍵相同的情況下,已經對第二個鍵進行了排序處理,
(2)、覆寫索引
? InnoDB存盤引擎支持覆寫索引(covering index,或稱索引覆寫),即從輔助索引中就可以得到查詢記錄,而不需要查詢聚集索引中的記錄,
? 使用覆寫索引的一個好處是:輔助索引不包含整行記錄的所有資訊,故其大小要遠小于聚集索引,因此可以減少大量的IO操作,
注意:覆寫索引技術最早是在InnoDB Plugin中完成并實作,這意味著對于InnoDB版本小于1.0的,或者MySQL資料庫版本為5.0以下的,InnoDB存盤引擎不支持覆寫索引特性,
? 對于InnoDB存盤引擎的輔助索引而言,由于其包含了主鍵資訊,因此其葉子節點存放的資料為(primary key1,priamey key2,...,key1,key2,...),
? 覆寫索引的另外一個好處是對某些統計問題而言的,基于上一小結創建的表buy_log,查詢計劃如下
mysql> explain select count(*) from buy_log;
+--+-----------+-------+-----+-------------+------+-------+----+----+-----------+
|id|select_type|table | type|possible_keys|key |key_len|ref |rows|Extra |
+--+-----------+-------+-----+-------------+------+-------+----+----+-----------+
| 1| SIMPLE |buy_log|index| NULL |userid| 4 |NULL| 7 |Using index|
+--+-----------+-------+-----+-------------+------+-------+----+----+-----------+
1 row in set (0.00 sec)
# Using index代表覆寫索引
? innodb存盤引擎并不會選擇通過查詢聚集索引來進行統計,由于buy_log表有輔助索引,而輔助索引遠小于聚集索引,選擇輔助索引可以減少IO操作,故優化器的選擇如上key為userid輔助索引
? 對于(a,b)形式的聯合索引,一般是不可以選擇b中所謂的查詢條件,但如果是統計操作,并且是覆寫索引,則優化器還是會選擇使用該索引,如下
# 聯合索引userid_2(userid,buy_date),一般情況,按照buy_date是無法使用該索引的,但特殊情況下:查詢陳述句是統計操作,且是覆寫索引,則按照buy_date當做查詢條件時,也可以使用該聯合索引
mysql> explain select count(*) from buy_log where buy_date >= '2011-01-01' and buy_date < '2011-02-01';
+--+-----------+-------+-----+-------------+--------+-------+----+----+------------------------+
|id|select_type| table |type |possible_keys| key |key_len|ref |rows|Extra |
+--+-----------+-------+-----+-------------+--------+-------+----+----+------------------------+
| 1| SIMPLE |buy_log|index| NULL |userid_2| 8 |NULL| 7 |Using where; Using index|
+--+-----------+-------+-----+-------------+--------+-------+----+----+------------------------+
1 row in set (0.00 sec)
# 合并索引
mysql> explain select count(email) from index_t where id = 1000000 or email='eva100000@oldboy';
+--+-----------+------+--------------+--------------------------------+---------------+--------+-----+----+-----------------------------------------+
| id | select_type| table | type | possible_keys | key | key_len | ref |rows | Extra |
+--+-----------+------+--------------+--------------------------------+---------------+--------+-----+----+-----------------------------------------+
| 1 | SIMPLE | index_t| index_merge | PRIMARY,email,ind_id,ind_email | PRIMARY,email | 4,51 |NULL| 2 |Using union(PRIMARY,email); Using where |
+--+-----------+------+--------------+--------------------------------+---------------+--------+-----+----+-----------------------------------------+
1 row in set (0.01 sec)
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/203334.html
標籤:其他
上一篇:MYSQL高并發與鎖機制
下一篇:MYSQL高并發與鎖機制