一、Elasticsearch 簡介
你可以這么形容 Elasticsearch :
- 一個分布式的實時檔案存盤,每個欄位都可以被索引與搜索
- 一個分布式實時分析搜索引擎
- 能勝任上百個服務節點的擴展,并支持 PB 級別的結構化或者非結構化資料
Elasticsearch 是一個實時分布式搜索和分析引擎,建立在一個全文搜索引擎庫 Apache Lucene 基礎之上,而 Lucene 是當下最先進、高性能、全功能的搜索引擎庫,
但是 Lucene 僅僅只是一個庫,為了充分發揮其功能,你需要使用 Java 并將 Lucene 直接集成到應用程式中, 更糟糕的是,您可能需要獲得資訊檢索學位才能了解其作業原理,因為 Lucene 非常復雜,
Elasticsearch 也是使用 Java 撰寫的,它的內部使用 Lucene 做索引與搜索,但是它的目的是使全文檢索變得簡單,通過隱藏 Lucene 的復雜性,取而代之的提供一套簡單一致的 RESTful API,
- 維基百科使用 Elasticsearch 提供全文搜索并高亮關鍵字,以及輸入實時搜索(search-asyou-type)和搜索糾錯(did-you-mean)等搜索建議功能,
- 英國衛報使用 Elasticsearch 結合用戶日志和社交網路資料提供給他們的編輯以實時的反饋,以便及時了解公眾對新發表的文章的回應,
- StackOverflow 結合全文搜索與地理位置查詢,以及 more-like-this 功能來找到相關的問題和答案,
- Github 使用 Elasticsearch 檢索 1300 億行的代碼,
- ...
Elasticsearch 不僅用于大型企業,它還讓像 DataDog 以及 Klout 這樣的創業公司將最初的想法變成可擴展的解決方案,Elasticsearch 可以在你的筆記本上運行,也可以在數以百計的服務器上處理 PB 級別的資料,
二、Elasticsearch 安裝
- Installing Elasticsearch
- Docker 下安裝 ElasticSearch 和 Kibana
- kibana 7.* 設定中文漢化
- Docker-compose 部署 ELK
五、Elasticsearch 基本概念
檔案(Document)
JSON 格式,Elasticsearch 存盤的最小單位,可以理解為是關系型資料庫中的一條記錄,每個檔案都有自己的一個 unique id,

檔案元資料,用于標注檔案的相關資訊
- _index:檔案所屬的索引名
- _type:檔案所屬的型別名
- _source:檔案的原始Json資料
- _id:檔案唯一id
- _version:檔案版本資訊
- _score:檔案相關度打分
索引(Index)
索引是檔案的一個容器,類比于關系型資料庫的資料庫概念,索引中的 setting 里定義有多少個 shards 來存盤索引資料,資料是如何分布,
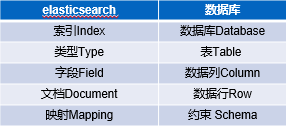
因此 每個索引(Index)包含多個型別(Type),不同的型別存盤著多個檔案(Document),每個檔案又有多個屬性(Field)
集群、節點、分片、副本
一個節點是一個 Elasticsearch 實體,Master節點,主要負責索引創建洗掉,維護集群中節點,分片分配;Data節點,存盤資料節點;協調節點,負責接收客戶端請求,分發請求到其他節點最后將資料匯集回應給客戶端;
四、Elasticsearch 資料和檢索
Elasticsearch 是面向檔案的,使用 JSON 作為檔案的序列化格式,而且 Elasticsearch 不僅存盤檔案,還索引每個檔案的內容,使之可以被檢索、排序和過濾,而這也是 Elasticsearch 能支持復雜全文檢索的原因,
我們可以使用 RESTful API 通過埠 9200(默認)和 Elasticsearch 進行通信,可以使用 kibana 訪問 Elasticsearch ,甚至可以直接使用 curl 命令來和 Elasticsearch 互動,
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
VERB:適當的 HTTP 方法或謂詞 : GET、POST、PUT、HEAD 或者 DELETE,
PROTOCOL:http 或者 https,
HOST:Elasticsearch 集群中任意節點的主機名,或者用 localhost 代表本地機器上的節點,
PORT:Elasticsearch HTTP 服務的埠號,默認是 9200.
PATH:API 的終端路徑(例如 _count 將回傳集群中檔案數量),Path 可能包含多個組件,例如:_cluster/stats 和 _nodes/stats/jvm ,
QUERY_STRING:可選,查詢字串引數 (例如 ?pretty 將格式化地輸出 JSON 回傳值,使其更容易閱讀)
BODY:可選,一個 JSON 格式的請求體
更多 DSL 語法可以參考:https://www.elastic.co/guide/en/elasticsearch/reference/7.9/search-search.html
如果你正在使用 Java,在代碼中你可以使用 Elasticsearch 內置的兩個客戶端:
節點客戶端(Node client)
節點客戶端作為一個非資料節點加入到本地集群中,換句話說,它本身不保存任何資料,但是它知道資料在集群中的哪個節點中,并且可以把請求轉發到正確的節點,
傳輸客戶端(Transport client)
輕量級的傳輸客戶端可以將請求發送到遠程集群,它本身不加入集群,但是它可以將請求轉發到集群中的一個節點上,
兩個 Java 客戶端都是通過 9300 埠并使用 Elasticsearch 的原生傳輸協議和集群互動,集群中的節點通過埠 9300 彼此通信,如果這個埠沒有打開,節點將無法形成一個集群,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/206955.html
標籤:NoSQL
下一篇:SQL 速查