一. Flink的下載
安裝包下載地址:http://flink.apache.org/downloads.html ,選擇對應Hadoop的Flink版本下載
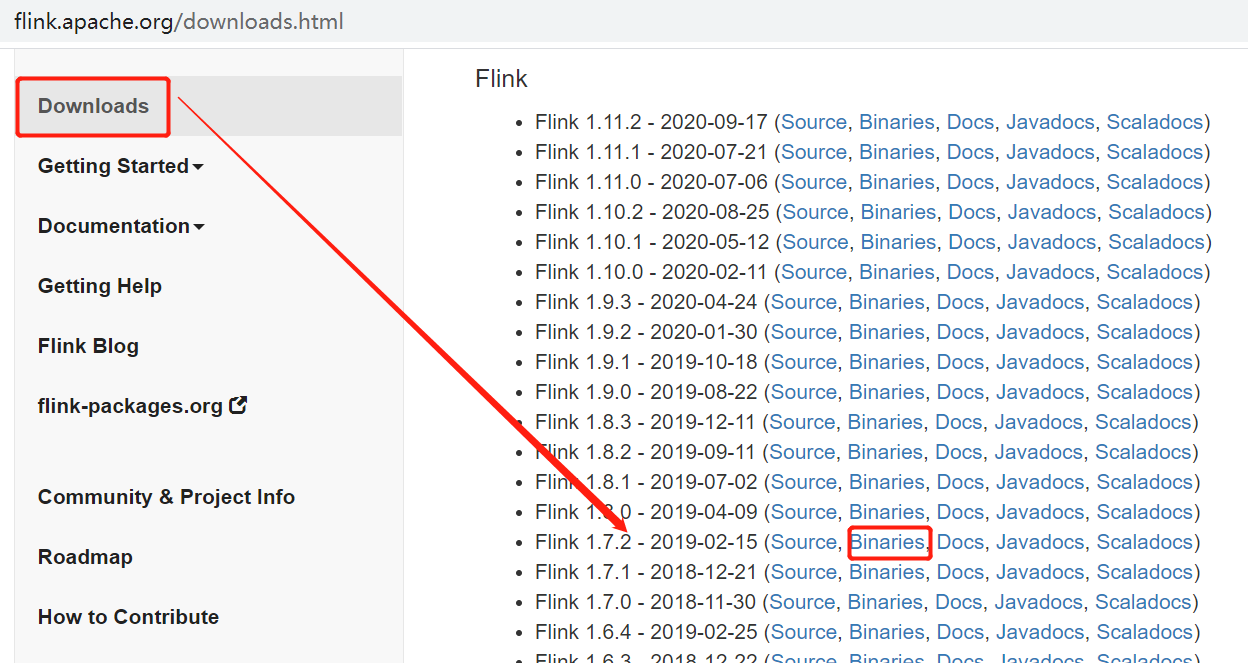
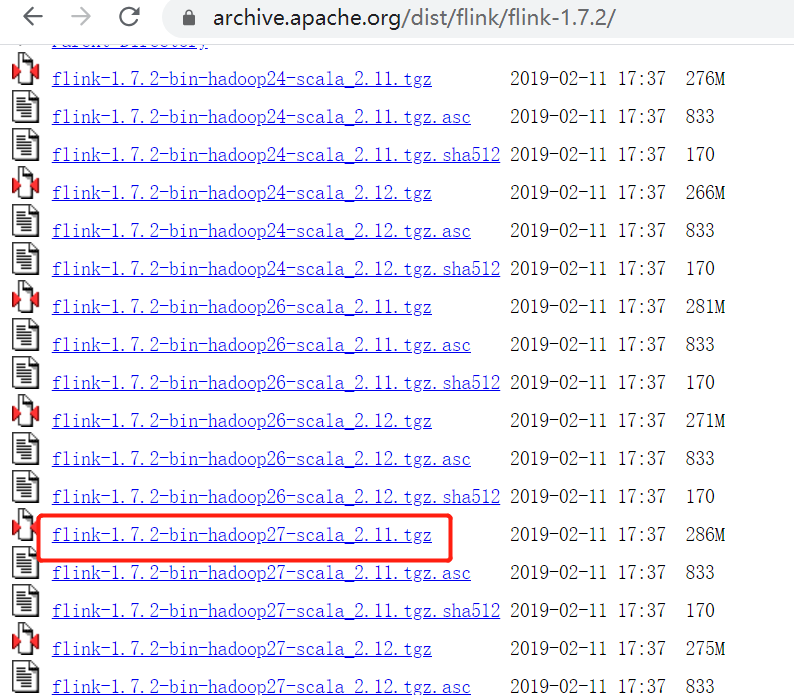
Flink 有三種部署模式,分別是 Local、Standalone Cluster 和 Yarn Cluster,
二. Local模式
對于 Local 模式來說,JobManager 和 TaskManager 會公用一個 JVM 來完成 Workload,如果要驗證一個簡單的應用,Local 模式是最方便的,實際應用中大多使用 Standalone 或者 Yarn Cluster,而local模式只是將安裝包解壓啟動(./bin/start-local.sh)即可,在這里不在演示,
三. Standalone 模式
1. 集群部署規劃
| 節點名稱 | master | worker | zookeeper |
| hadoop01 | master | zookeeper | |
| hadoop02 | master | worker | zookeeper |
| hadoop03 | woker | zookeeper |
2. 解壓
[hadoop@hadoop01 apps]$ tar -zxvf flink-1.7.2-bin-scala_2.11.tgz -C ./
[hadoop@hadoop01 apps]$ ls
azkaban flink-1.7.2 flink-1.7.2-bin-scala_2.11.tgz flume-1.8.0 hadoop-2.7.4 jq kafka_2.11-0.11 zkdata zookeeper-3.4.10 zookeeper.out
3. 修改組態檔
[hadoop@hadoop01 apps]$ cd flink-1.7.2/
[hadoop@hadoop01 flink-1.7.2]$ ls
bin conf examples lib LICENSE licenses log NOTICE opt README.txt
[hadoop@hadoop01 flink-1.7.2]$ cd conf/
[hadoop@hadoop01 conf]$ ls
flink-conf.yaml log4j-console.properties log4j-yarn-session.properties logback.xml masters sql-client-defaults.yaml
log4j-cli.properties log4j.properties logback-console.xml logback-yarn.xml slaves zoo.cfg
修改flink/conf/masters,slaves,flink-conf.yaml
[hadoop@hadoop01 conf]$ vim masters
hadoop01:8081
[hadoop@hadoop01 conf]$ vim slaves
hadoop02
hadoop03
[hadoop@hadoop01 conf]$ vim flink-conf.yaml
jobmanager.rpc.address: hadoop01
4. 拷貝安裝包到各節點
[hadoop@hadoop01 apps]$ scp -r flink-1.7.2/ hadoop@hadoop02:`pwd`
[hadoop@hadoop01 apps]$ scp -r flink-1.7.2/ hadoop@hadoop03:`pwd`
5. 配置環境變數
配置所有節點Flink的環境變數
[hadoop@hadoop01 ~]$ vim .bashrc
export FLINK_HOME=/home/hadoop/apps/flink-1.7.2
export PATH=$PATH:$FLINK_HOME/bin
[hadoop@hadoop01 ~]$ source .bashrc
6. 啟動flink
[hadoop@hadoop01 bin]$ pwd
/home/hadoop/apps/flink-1.7.2/bin
[hadoop@hadoop01 bin]$ ls
config.sh flink-daemon.sh mesos-appmaster.sh pyflink-stream.sh start-cluster.sh stop-zookeeper-quorum.sh
flink historyserver.sh mesos-taskmanager.sh sql-client.sh start-scala-shell.sh taskmanager.sh
flink.bat jobmanager.sh pyflink.bat standalone-job.sh start-zookeeper-quorum.sh yarn-session.sh
flink-console.sh mesos-appmaster-job.sh pyflink.sh start-cluster.bat stop-cluster.sh zookeeper.sh
[hadoop@hadoop01 bin]$ ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop01.
Starting taskexecutor daemon on host hadoop02.
Starting taskexecutor daemon on host hadoop03.
jps查看行程
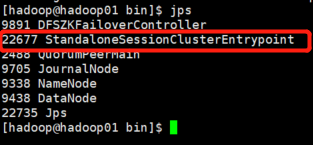
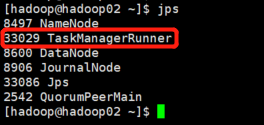
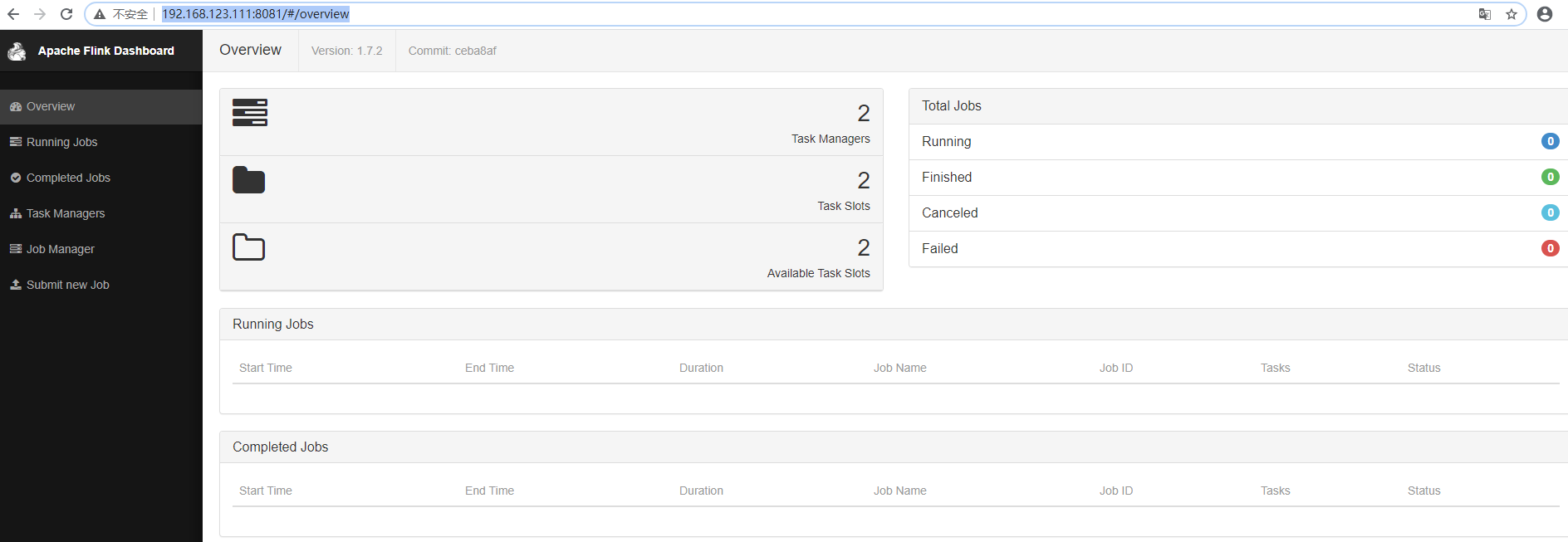
7. WebUI查看
http://192.168.123.111:8081
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/207989.html
標籤:其他
上一篇:MySQL 之 資料的匯出與匯入
下一篇:JavaScript基礎知識學習總結篇(每個知識點都附帶上機的例子,而不是純理論) 上,當前字數統計:12435