一. Flink的下載
安裝包下載地址:http://flink.apache.org/downloads.html ,選擇對應Hadoop的Flink版本下載
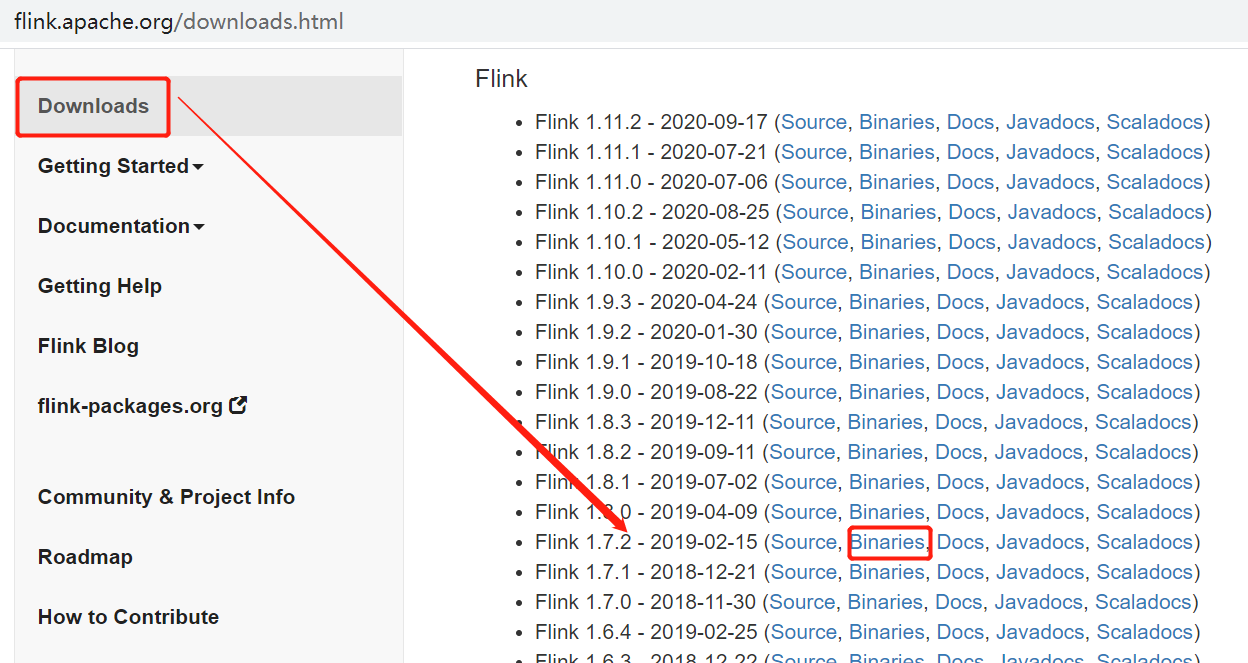
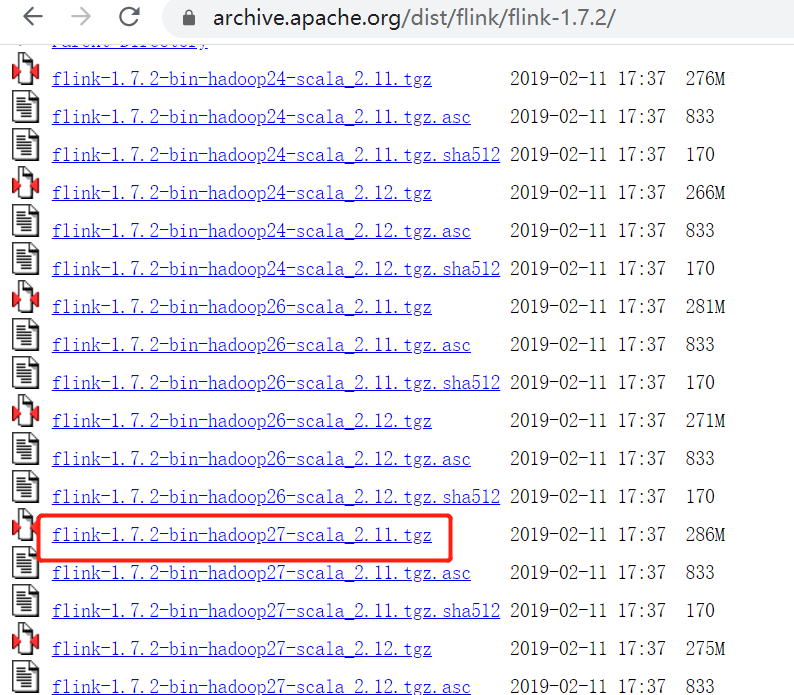
Flink 有三種部署模式,分別是 Local、Standalone Cluster 和 Yarn Cluster,
二. Local模式
對于 Local 模式來說,JobManager 和 TaskManager 會公用一個 JVM 來完成 Workload,如果要驗證一個簡單的應用,Local 模式是最方便的,實際應用中大多使用 Standalone 或者 Yarn Cluster,而local模式只是將安裝包解壓啟動(./bin/start-local.sh)即可,在這里不在演示,
三. Standalone HA模式
Standalone模式顧名思義,是在本地集群上調度執行,不依賴于外部調度機制例如YARN, 一般需要配置為HA,防止Jobmanager突然掛掉,導致整個集群或者任務執行失敗的情況發生,下面介紹一下Standalone HA模式的搭建安裝
當Flink程式運行時,如果jobmanager崩潰,那么整個程式都會失敗,為了防止jobmanager的單點故障,借助于zookeeper的協調機制,可以實作jobmanager的HA配置—-1主(leader)多從(standby),這里的HA配置只涉及standalone模式,yarn模式暫不考慮,
本例中規劃Jobmanager:hadoop01,hadoop02(一個active,一個standby);Taskmanager:hadoop02,hadoop03;zookeeper集群
1. 集群部署規劃
| 節點名稱 | master | worker | zookeeper |
| hadoop01 | master | worker | zookeeper |
| hadoop02 | master | worker | zookeeper |
| hadoop03 | woker | zookeeper |
2. 解壓
[hadoop@hadoop01 apps]$ tar -zxvf flink-1.7.2-bin-scala_2.11.tgz -C ./
[hadoop@hadoop01 apps]$ ls
azkaban flink-1.7.2 flink-1.7.2-bin-scala_2.11.tgz flume-1.8.0 hadoop-2.7.4 jq kafka_2.11-0.11 zkdata zookeeper-3.4.10 zookeeper.out
3. 修改組態檔
配置masters檔案
該檔案用于指定主節點及其web訪問埠,表示集群的Jobmanager,vi masters,添加master:8081
[hadoop@hadoop01 conf]$ vim masters
hadoop01:8081
hadoop02:8081
配置slaves檔案,該檔案用于指定從節點,表示集群的taskManager,添加以下內容
[hadoop@hadoop01 conf]$ vim slaves
hadoop01
hadoop02
hadoop03
組態檔flink-conf.yaml
#jobmanager.rpc.address: hadoop01 high-availability:zookeeper #指定高可用模式(必須) high-availability.zookeeper.quorum: hadoop01:2181,hadoop02:2181,hadoop03:2181 #ZooKeeper仲裁是ZooKeeper服務器的復制組,它提供分布式協調服務(必須) high-availability.storageDir:hdfs://192.168.123.111:9000/flink-metadata/recovery/ #JobManager元資料保存在檔案系統storageDir中,只有指向此狀態的指標存盤在ZooKeeper中(必須) high-availability.zookeeper.path.root:/flink #根ZooKeeper節點,在該節點下放置所有集群節點(推薦) high-availability.cluster-id:/flinkCluster #自定義集群(推薦)
#檢查點生成的分布式快照的保存地點,默認是jobmanager的memory,但是HA模式必須配置在hdfs上,且保存路徑需要在hdfs上創建并指定路徑
state.backend: filesystem state.checkpoints.dir: hdfs://192.168.123.111:9000/flink-metadata/checkpoints state.savepoints.dir: hdfs:///flink/checkpoints
4. 拷貝安裝包到各節點
[hadoop@hadoop01 apps]$ scp -r flink-1.7.2/ hadoop@hadoop02:`pwd`
[hadoop@hadoop01 apps]$ scp -r flink-1.7.2/ hadoop@hadoop03:`pwd`
5. 配置環境變數
配置所有節點Flink的環境變數
[hadoop@hadoop01 ~]$ vim .bashrc
export FLINK_HOME=/home/hadoop/apps/flink-1.7.2
export PATH=$PATH:$FLINK_HOME/bin
[hadoop@hadoop01 ~]$ source .bashrc
6. 啟動flink
[hadoop@hadoop01 bin]$ pwd
/home/hadoop/apps/flink-1.7.2/bin
[hadoop@hadoop01 bin]$ ls
config.sh flink-daemon.sh mesos-appmaster.sh pyflink-stream.sh start-cluster.sh stop-zookeeper-quorum.sh
flink historyserver.sh mesos-taskmanager.sh sql-client.sh start-scala-shell.sh taskmanager.sh
flink.bat jobmanager.sh pyflink.bat standalone-job.sh start-zookeeper-quorum.sh yarn-session.sh
flink-console.sh mesos-appmaster-job.sh pyflink.sh start-cluster.bat stop-cluster.sh zookeeper.sh
[hadoop@hadoop01 bin]$ ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop01.
Starting taskexecutor daemon on host hadoop02.
Starting taskexecutor daemon on host hadoop03.
jps查看行程
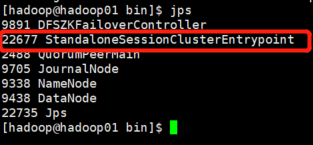
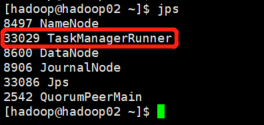
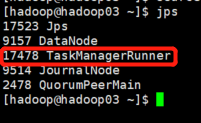
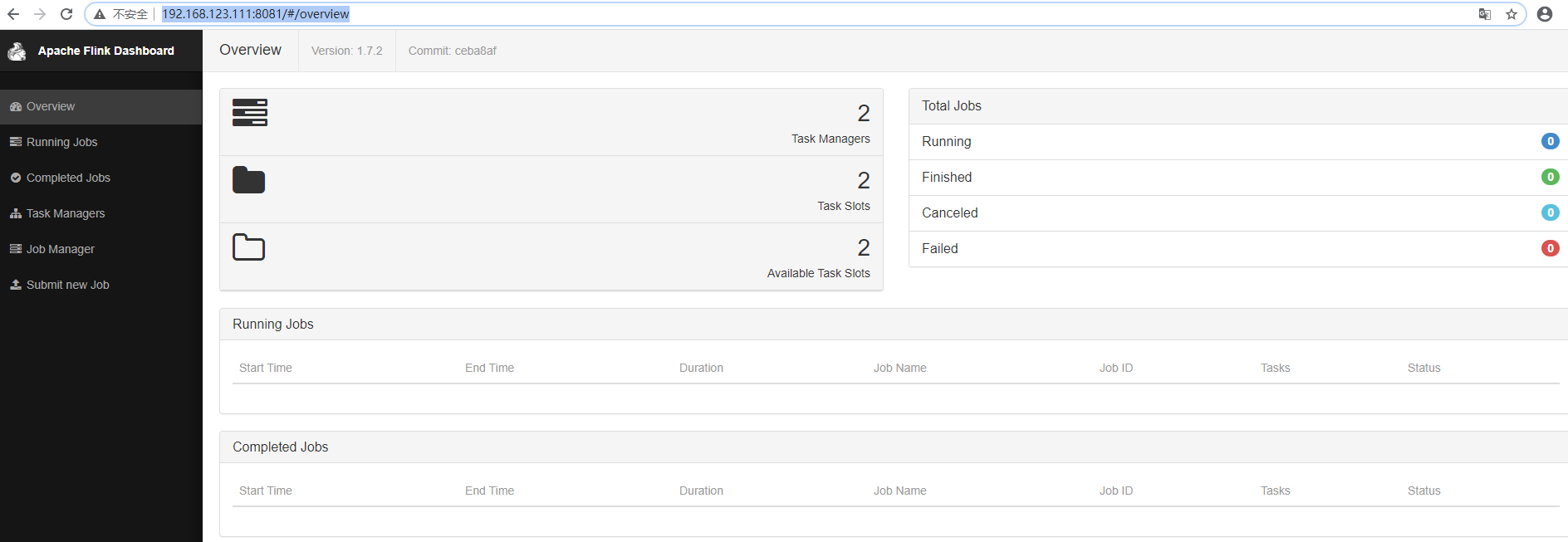
7. WebUI查看
http://192.168.123.111:8081
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/208665.html
標籤:大數據