導語 TBase 是騰訊TEG資料平臺團隊在開源 PostgreSQL 的基礎上研發的企業級分布式 HTAP 資料庫系統,可在同一資料庫集群中同時為客戶提供強一致高并發的分布式在線事務能力以及高性能的資料在線分析能力,本文是對騰訊 TBase 專家工程師伍鑫在云+社區沙龍 online 的分享整理,將為大家帶來騰訊云 TBase 在分布式 HTAP 領域的探索與實踐,
點擊視頻查看完整直播回放
Part1 TBase分布式資料庫介紹
1. TBase 發展歷程

騰訊云從 2009 年便開始在內部的業務上進行嘗試,在企業分布式資料庫領域的自研程序是比較有經驗的,當時主要是為了滿足一些較小的需求,比如引入PostgreSQL 作為 TDW 的補充,彌補 TDW 小資料分析性能低的不足,處理的需求量也較小,
但業務慢慢的大了后,需要有一個更高效的在線交易事務的處理能力,對資料庫要進行一個擴展,所以后面我們就持續的投入到資料庫的開發程序中,
2014 年 TBase 發布的第一個版本開始在騰訊大資料平臺內部使用;2015 年 TBase 微信支付商戶集群上線,支持著每天超過 6 億筆的交易;2018 年的時候 V2 版本對事務、查詢優化以及企業級功能做了較大增強,慢慢的開始面向一些外部客戶;2019 年 TBase 中標了 PICC 集團的核心業務,協助了他們在國內保險行業比較領先的核心系統,并穩定服務了很長的時間,
考慮到 TBase 整體能力的持續發展,我們是希望把 TBase 的能力貢獻給開源社區,這樣能更多的支持資料庫國產化專案,于是在 2019 年 11 月,我們把資料庫進行了開源,希望能助力數字化產業升級,
2. PostgreSQL 資料庫簡介
TBase 是基于單機 PostgreSQL 自研的一個分布式資料庫,除了具備完善的關系型資料庫能力外,還具備很多企業級的能力,同時增強了分布式事務能力,以及比較好的支持在線分析業務,提供一站式的解決方案,
在資料安全上,我們有著獨特之處,包括三權分立的安全體系,資料脫敏、加密的能力,其次在資料多活、多地多中心的靈活配制上面,也提供了比較完善的能力,保障了金融行業在線交易中一些高可用的場景,為金融保險等核心業務國產化打下堅實基礎,
PostgreSQL 是一個開源的 RDBMS,開源協議基于 BSB 風格,所以源代碼可以更加靈活的供大家修改,也可以在修改的基礎上進行商業化,
PostgreSQL 是由圖靈獎得主 MichaelStonebraker 主導的一個開源專案,如上圖所示,它已經迭代得比較久了,到現在已經發布到 12 版本,并且一直在持續的迭代,整體處于一個比較活躍的水平,
3. PostgreSQL 發展趨勢
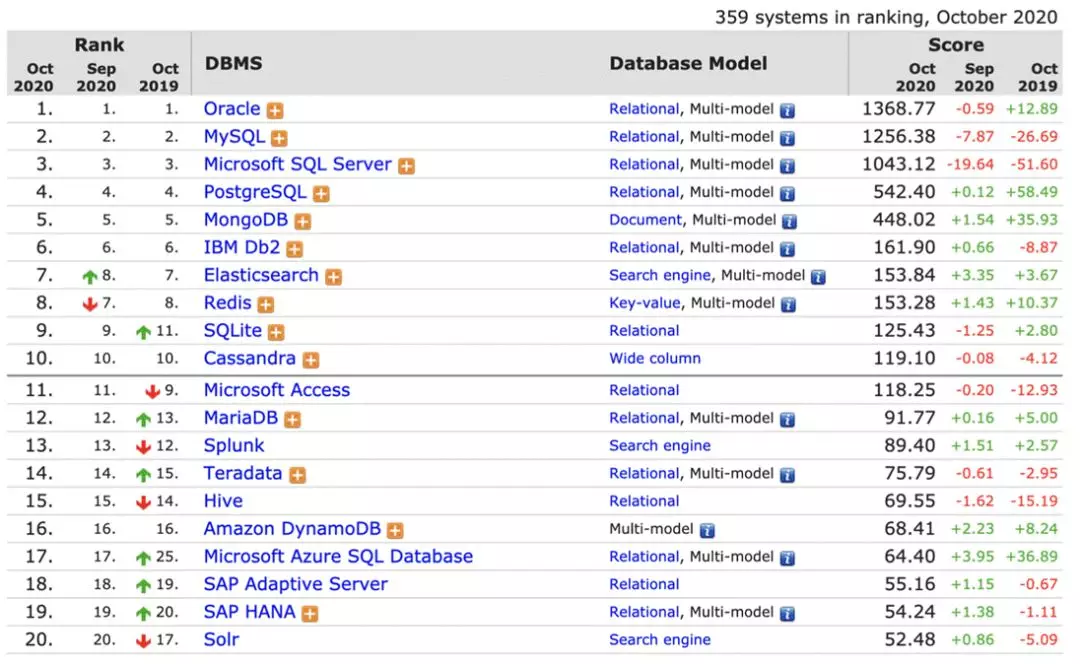
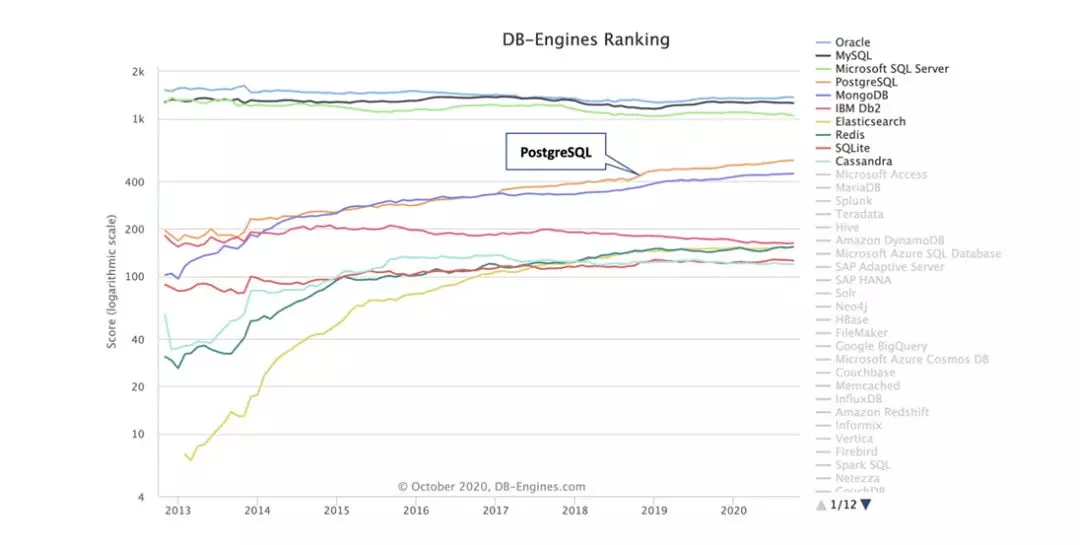
PostgreSQL 在近十年開始受到的大家的關注,首先是因為它的內核功能,包括社區的持續活躍,在過去幾年獲得了持續的進步,上圖是來自 DB-Engines 的統計,根據資料我們可以看到在去年整體大家都有一些退步和增長不太高的情況下 PostgreSQL 的進步是比較明顯的,
下圖中黃色的曲線是 PostgreSQL,我們可以很直觀的看到它發展趨勢是比較良好的,
目前開源的 TBase 版本是基于 PostgreSQL10,我們也在持續的匹配 PostgreSQL 更多的功能,后續也會回饋到開源社區,希望和整體的 PostgreSQL生態有一個良好的結合和互動,
Part2 開源TBase定位及整體架構
1. 開源 TBase 的定位

資料庫按照業務場景主要分為:OLAP、OLTP 和 HTAP,
OLAP 的業務特點是資料量較大,一般是 10PB+,對存盤成本比較敏感,它的并發相對于 OLTP 不會太高,但對復雜查詢可以提供比較好的支持,
OLTP 的資料量相對較小,很多中小型的系統都不會達到 TB 級的資料量,但對事務的要求和查詢請求的要求會比較高,吞吐達到百萬級 TPS 以上,并且 OLTP 對于容災能力要求較高,
國內的國產化資料庫很多會從 OLAP 領域進行切入,從OLTP 角度切入會相對比較難,目前這一塊還是被 IBM 或者Oracle 壟斷的比較嚴重,我們希望盡快在這一塊實作國產化,而 TBase 因為在保險行業有比較長時間的耕耘,在 OLTP 核心業務能力上有比較強的,
另外一個是 HTAP,在之前大部分的業務部署中,大家會把 TP 和 AP 分開,在中間可能有 ETL 或者流復式的技術將兩套系統進行互動,但更理想的情況是可以在一套系統中同時完成兩種業務型別的支持,
當然這個會比較復雜,首先大家可以看到他們的業務特點差別比較大,內核領域的優化方向也是完全不一樣的,或者說技術上差異比較大,
TBase 推出 HTAP 也是從具體的需求出發,實際上 TBase 是更偏向于 TP,同時兼顧了比較好的 AP 的處理能力,在一套系統里盡量做到比較好的兼容,但如果要做更極致性能的話,還是要對HTAP 進行隔離,對用戶提供一種完整的服務能力,

TBase 的角度也是根據需求衍生出來的,騰訊云最早是做交易系統,后面慢慢的補充了 AP 的分析能力,
這塊面臨的主要的業務場景需求,首先是交易資料可能會大于 1T,分析能力大于 5T,并發能力要求達到 2000 以上,每秒的交易峰值可能會達到 1000 萬,在需要擴展能力的情況下,需要對原有的事務能力、分析能力,或者資料重分布的影響降到最低,同時在事務層面做到一個完備的分布式一致性的資料庫,
同時 TBase 也進行了很多企業級能力的增強,三權分立的安全保障能力、資料治理能力、冷熱資料資料及大小商戶資料的分離等,

前面我們介紹了 TBase 的發展程序,在這程序中我們也希望可以為開源社區進行一些貢獻,
實際上在國內環境中替換核心業務還是比較難,更多的是從分析系統切入,最近幾年才開始有系統切入到核心的交易事務能力上,TBase 也希望通過開源回饋社區,保證大家可以通過 TBase 的 HTAP 能力來填補一些空白,擴充生態的發展,
開源后我們也受到了比較多的關注和使用,其中還包括歐洲航天局的 Gaia Mission 在用我們的系統進行銀河系恒星系統的資料分析,希望有更多的同學或者朋友加入到 TBase 的開發程序中,也希望通過本次介紹,方便大家更好的切入到 TBase 開源社區的互動中,
2. TBase 總體構架
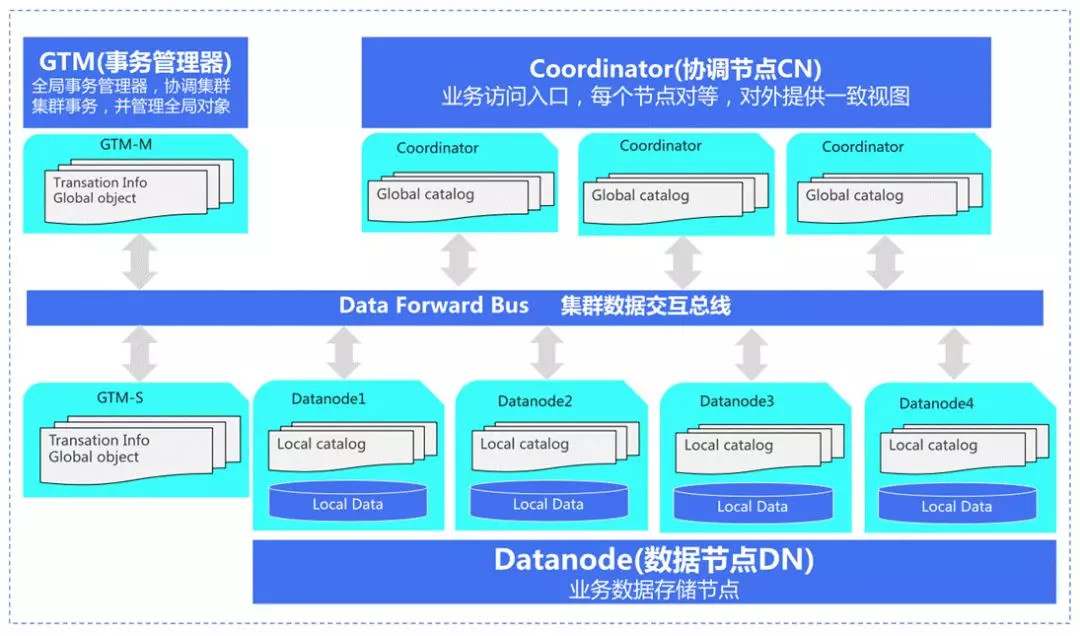
一個集群是由這幾個部分組成:GTM、Coordinator和 Datanode,其中 GTM 主要負責全域事務的管控,是提供分布式一致性協議的基石;Coordinator 是用戶業務的訪問入口,對用戶的請求進行分析和下發,具體的計算和資料存盤則是放到了 Datanode 當中,
Part3 HTAP方面能力介紹
剛才我們講的是 HTAP,下面我們先講一下 OLTP,TBase 在這部分的能力是比較突出的,
如果用戶需要在事務或者并發交易量上有要求的話,就需要一套比較好的分布式事務的系統,具體的需求包括高性能和低成本,在這部分,TBase 相較于傳統的 IBM 或者國外更貴的一體機有較大的優勢,
另外一個需求就是可擴展,在節點擴展的情況下去近似線性的擴展事務處理能力,那要如何達成這個目標?
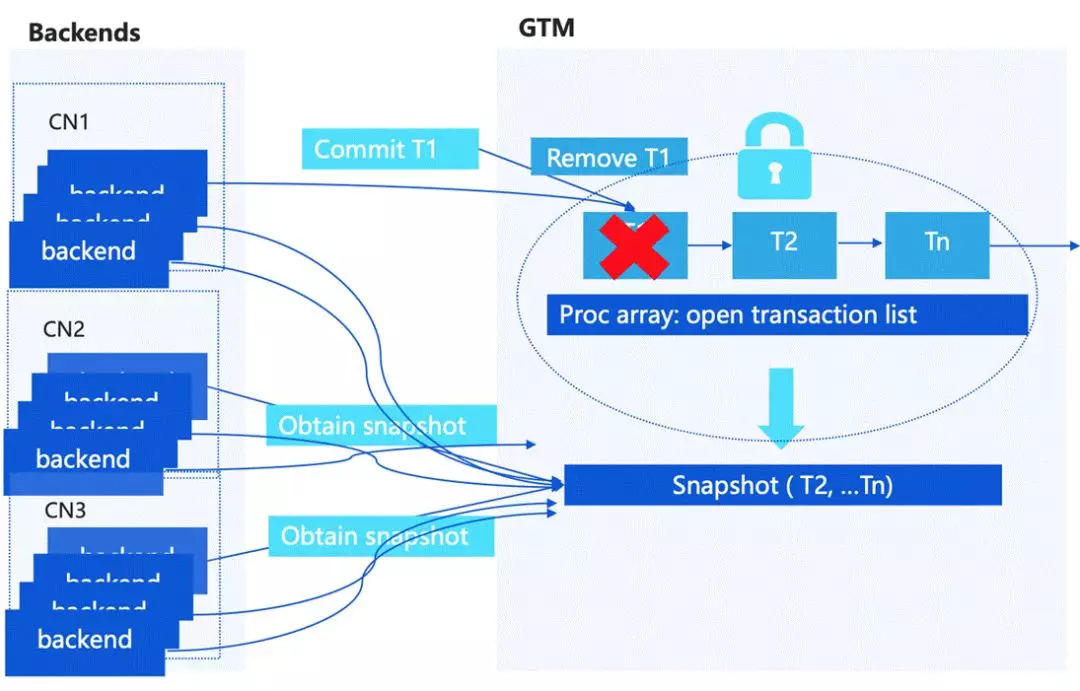
簡單介紹一下事務的 MVCC 的處理,單機 PostgreSQL 主要是維護一個當前的活躍事務串列,它有一個結構叫 Proc array,相當于每一個用戶的 session 有新的事務請求的話,會在事物串列里去記錄當前活躍的事務,當需要判斷 tuple 的可見性的話,會在活躍事務串列里拿一個 Snapshot 去跟存盤上面的 tuple header 中記錄的 XID 資訊進行一個對比,去做 MVCC 的訪問控制,
如果是擴展到分布式的情況,一個比較簡單的方式是需要有一個中心節點,按之前的構架,在 GTM 上面會有一個中心化的活躍事物串列,來統一的為每一個訪問的請求去分配 Snapshot,
但這個時候就有一個比較大的問題,中心節點會成為瓶頸,GTM 也會有一些問題,比如說快照的尺寸過大或者占用網路較高,
GTM 如果做一個中心化的節點的話,實際上存在一個單點瓶頸,每一個請求都要保證它拿到 snapshot 的正確性,這就需要對活躍事務串列進行上鎖,這個在高并發情況下鎖沖突會很大,我們是怎么解決這個問題的呢?
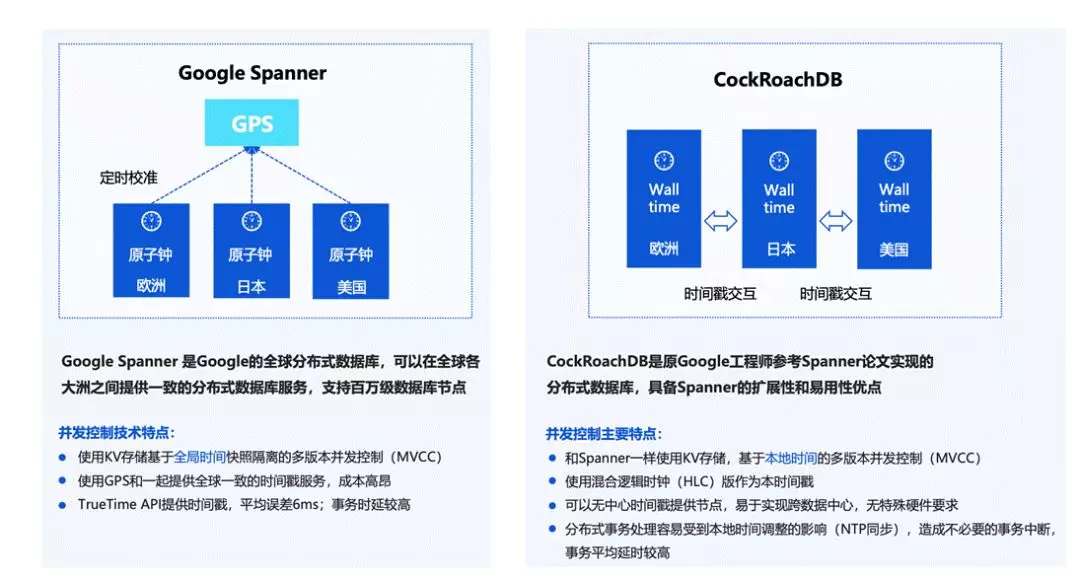
這實際上也是業界一個通用的問題,目前我們看到互聯網行業的方案,是從 Google Spanner 的方向衍生出來的,
Google Spanner 是一個全球分布式資料庫,可以在各大洲之間提供一致性的資料庫服務能力,它的控制并發技術特點,一是通過 KV 存盤基于全域時間的多版本并發控制,另外一個是它通過使用成本比較高的 GPS 和全球一致的服務時間戳機制來提供一個 TrueTime API,基于真實時間制作一套提交協議,因為它的整體全球分布式,導致平均誤差會大概在 6 毫秒左右,整體的事務時延是比較高的,
另外,有較多的系統會借鑒 Google Spanner 做事務模型,CockRoachDB 也是其中之一,
另外,Percolator 也是 Google 為搜索引擎提供的一個比較有效率的資料庫,使用 KV 存盤,基于全域邏輯時間戳的 MVCC 進行并發控制,它的時間戳由專門的時間戳服務提供,分布式事務第一階段需要對修改記錄加鎖,提交階段結束鎖定;事務提交時間復雜度為 O(N),N 是記錄數,導致提交的性能會有影響,當然這樣的設計也和系統需求相關,
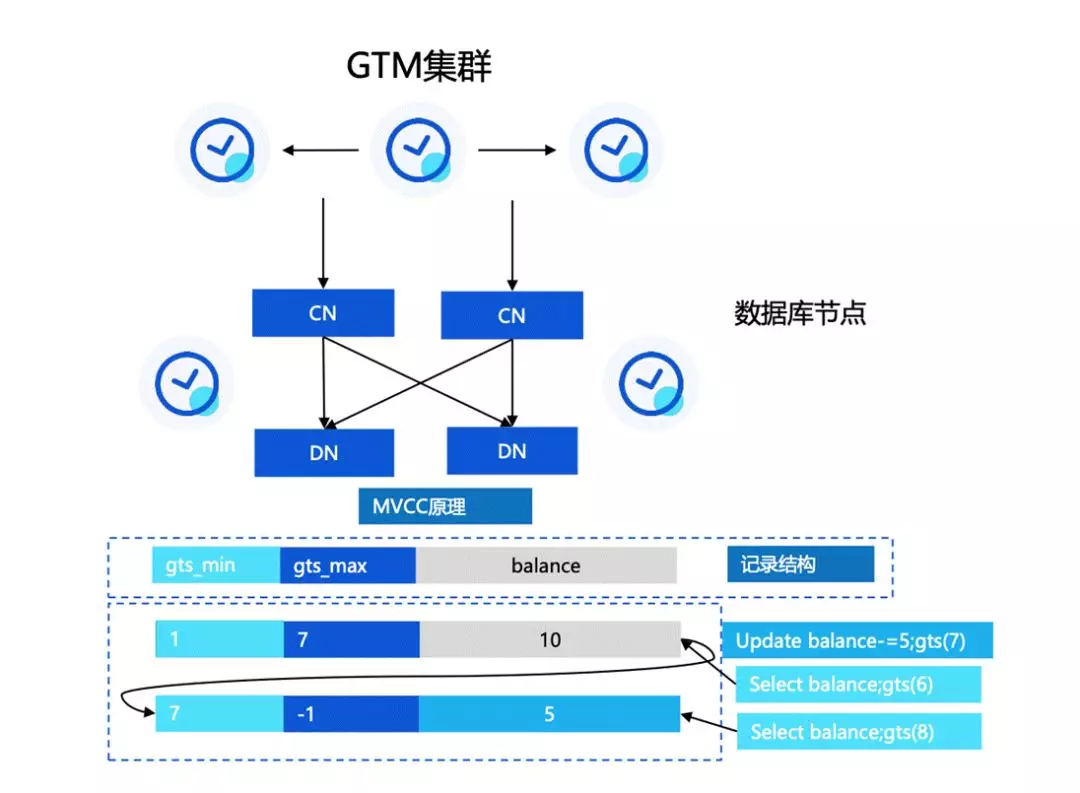
下面看一下 TBase 在分布式事務上的能力,這部分我們也是在前面的基礎上做了較大改進,
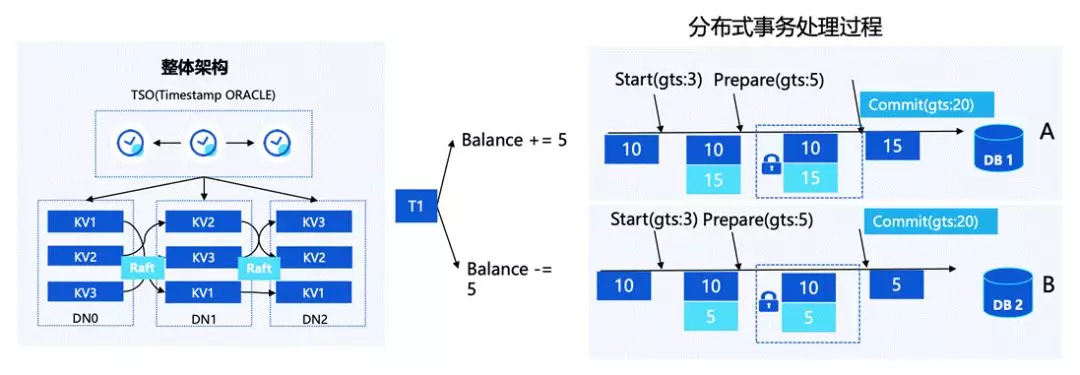
首先我們對 GTM 集群做了優化,從原始的全域 XID 改成了分配全域時間戳GlobalTimeStamp(GTS),GTS 是單調遞增的,我們基于 GTS 設計了一套全新的 MVCC 可見性判斷協議,包括 vacuum 等機制,這樣的設計可以把提交協議從 GTM 的單點瓶頸下放到每一個節點上,減輕壓力,同時通過時間戳日志復制的方式實作 GTM 節點主備高可用,
這種協議下 GTM 只需要去分配全域的 GTS,這樣的話單點壓力就會被解決得比較明顯,根據我們的推算, 滕敘 TS85 服務器每秒大概能處理 1200 萬 TPS,基本能滿足所有分布式的壓力和用戶場景,
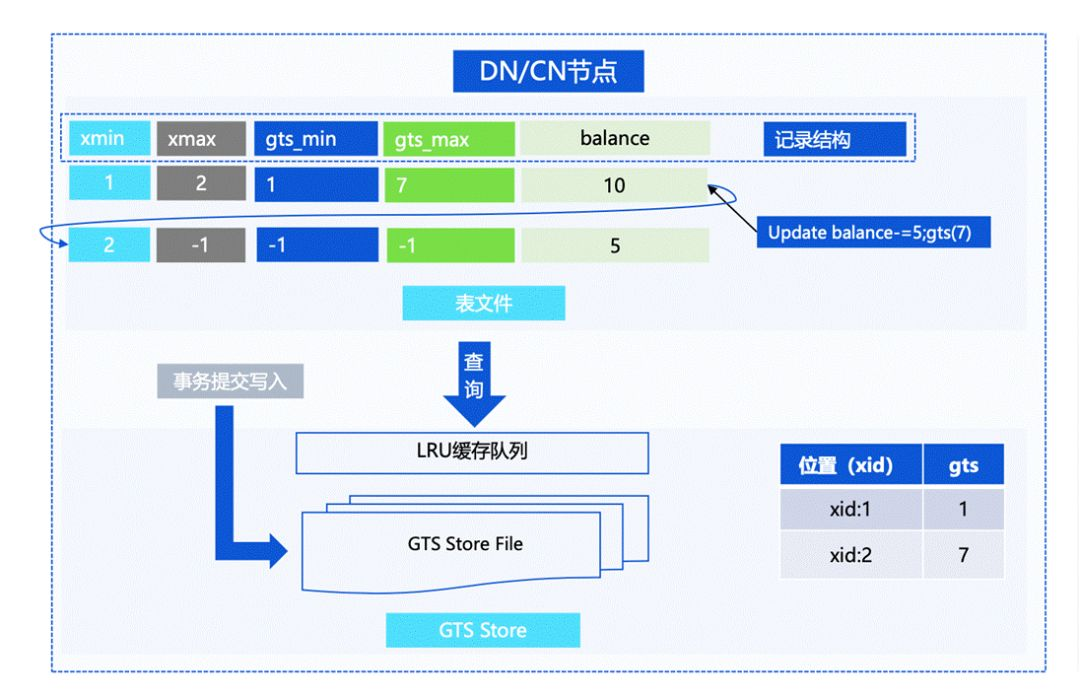
我們剛才也提到,在 Percolator 的實作下,需要對 Tuple 上鎖并修改記錄,這樣的話性能是比較差的,而實際上我們對提交協議做了一個優化,在對 Tuple Header 的 GTS 寫入做了延遲處理,事務提交的時候不需要為每一個 Tuple 修改 GTS 資訊,而是把 GTS 的資訊存盤在相應的 GTS Store File 當中,作為事務恢復的保障,
當用戶第一次掃描資料的時候,會從 GTS Store File 中取到狀態,再寫入到 Tuple Header 中,之后的掃描就不需要再去遍歷狀態檔案,從而實作加速訪問,做到事務處理的加速,這樣在整體上,讓資料庫在事務層面保證了比較高效的設計,
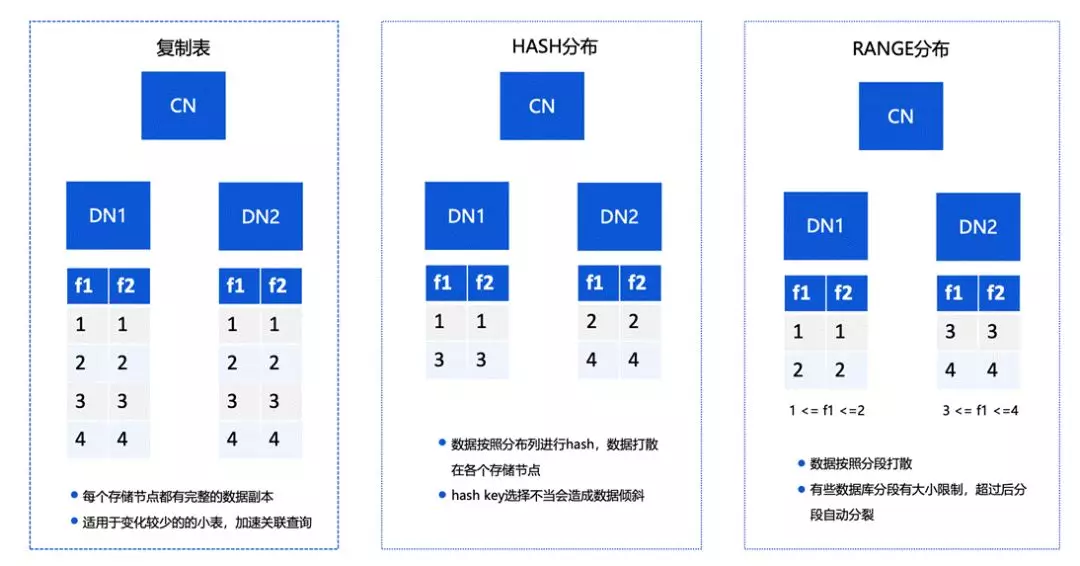
關于集中資料分布的分類情況,有以下三種,
第一種情況是復制表,復制表中的每個存盤節點都有完整的資料副本,適用于變化較少的小表,可以加速關聯查詢,
第二種是 HASH 分布,這是比較經典的一種方式,簡單來講就是將資料按照分布列進行 hash,把資料打散在各個存盤節點中,如果 hash key 選擇不當,則可能造成資料傾斜的情況,
第三種是基于 RANGE 的分布,RANGE 分布會將資料按照分段打散成小的分片,和 hash 相比分布上不會特別嚴格,對上層的節點彈性有比較好的支持,但它在計算的時候,相對 hash 的效果不會特別好,
在整體上,TBase 選擇的是復制表和增強的 hash分布,
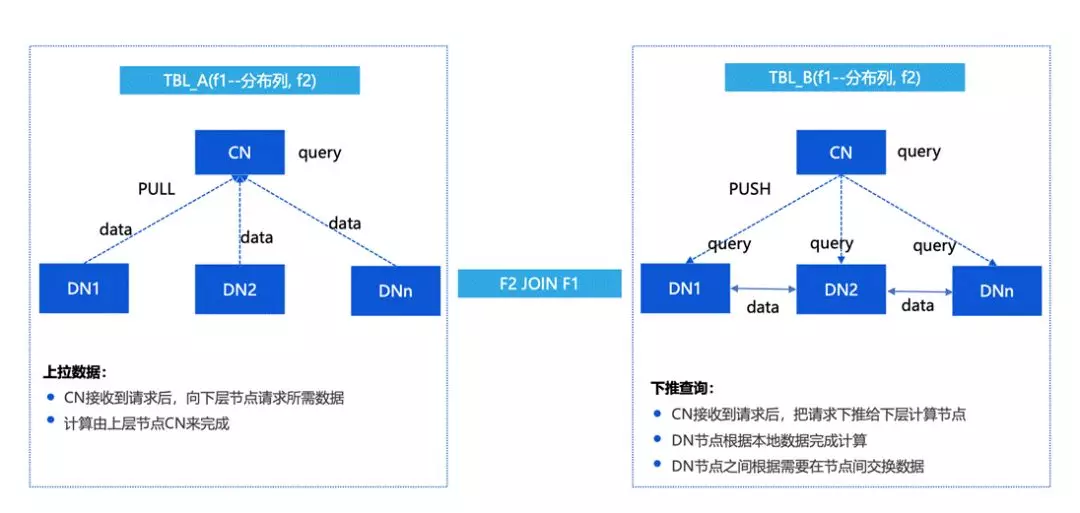
下面介紹一下如何看分布式查詢,PushQuery 和 PullData,
最開始早期的一些系統可能會選擇更快速的實作,比如說存盤上是分成多個 DN,然后把資料拉取到 CN 進行計算,
這種情況下優缺點都比較明顯,優點是更高效更快速,缺點是 CN 是一個瓶頸,在網路上壓力比較大,所以我們更傾向于上圖中右邊的方式,把有的資料和計算下放到 DN 結點上,
最基本的情況下,希望所有的計算可以放到 DN 上來進行,DN 在做重分布的時候,需要跟 DN 間有互動的能力,這個在 TBase V2 之后做了比較多的增強,目前 TBase 可以將計算盡量的分散到 DN 結點上來進行,
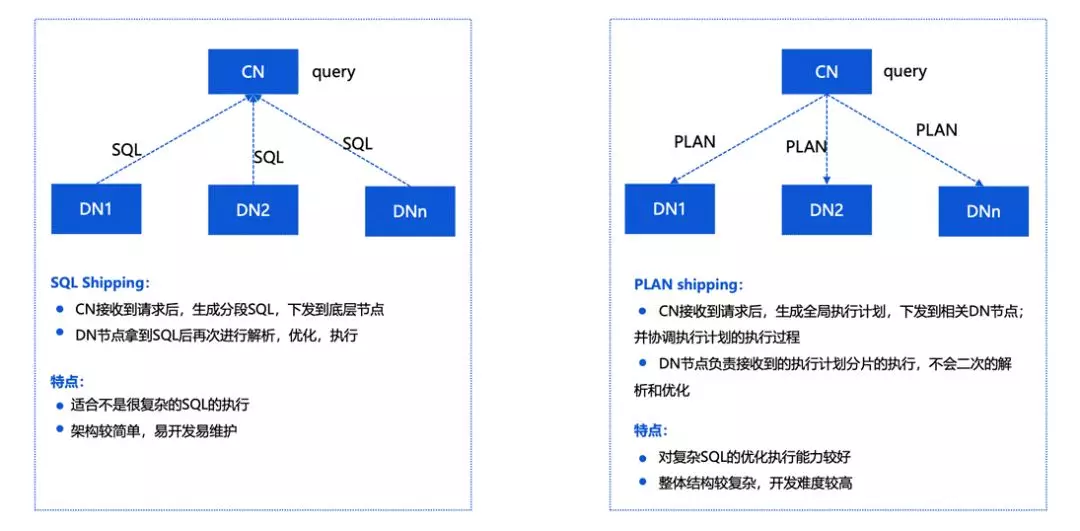
上圖介紹的是 SQL Shipping 和 PlanShipping 的區別,
實際上當處理一個 query 或者一個查詢計劃的時候,會有兩種情況,一種是說我直接把 SQL 通過分析發到 DN 上執行,CN只負責結果的收集,這樣的優化效果會比較好,因為不需要在多個節點建立分布式一致性的提交協議,另外在計算資源上效率會更高,我們在 OLTP 領域的一些優化會采用這樣的方式,
另一種情況是在 OLAP 領域,更正規的 PLAN 的分布式,在 CN 上對 query 做一個整體的plan,按照重分布的情況把計劃分解成不同的計算分片,分散到 DN上進行處理
剛才講到,就是如果能把對 OLTP 推到某單個 DN 上來做的話,效果會比較好,我們舉個簡單的例子,
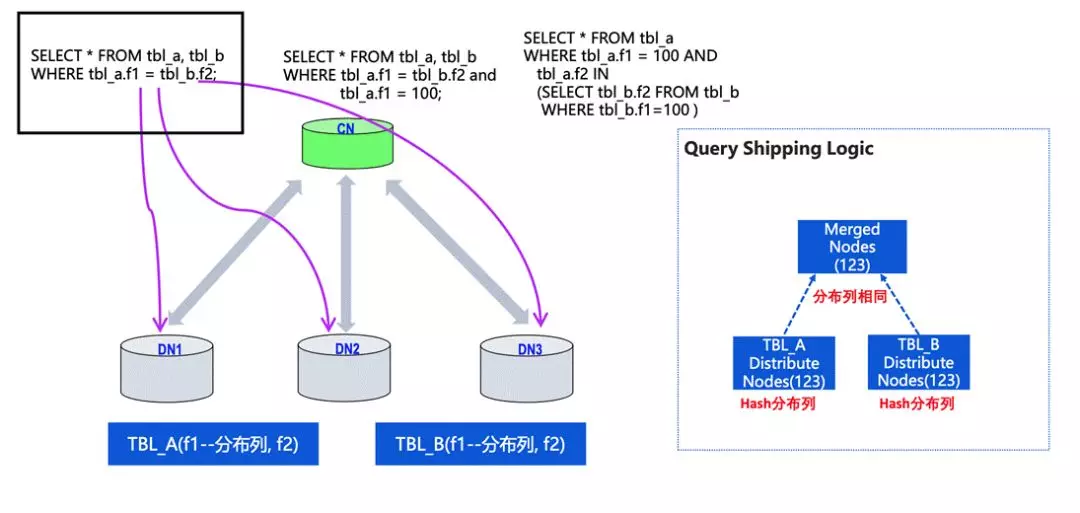
兩張表的分布列是 f1,資料列是 f2,若 query 可以寫成分布鍵的關聯情況,并且采用的是 hash 分布,就可以把 query 推到不同的 DN 上來做,因為不同 DN 間的資料受到分布件的約束,不需要做交叉計算或者資料的重分布,
第二類是有分布鍵的等值鏈接,同時還有某一個分布鍵的具體固定值,
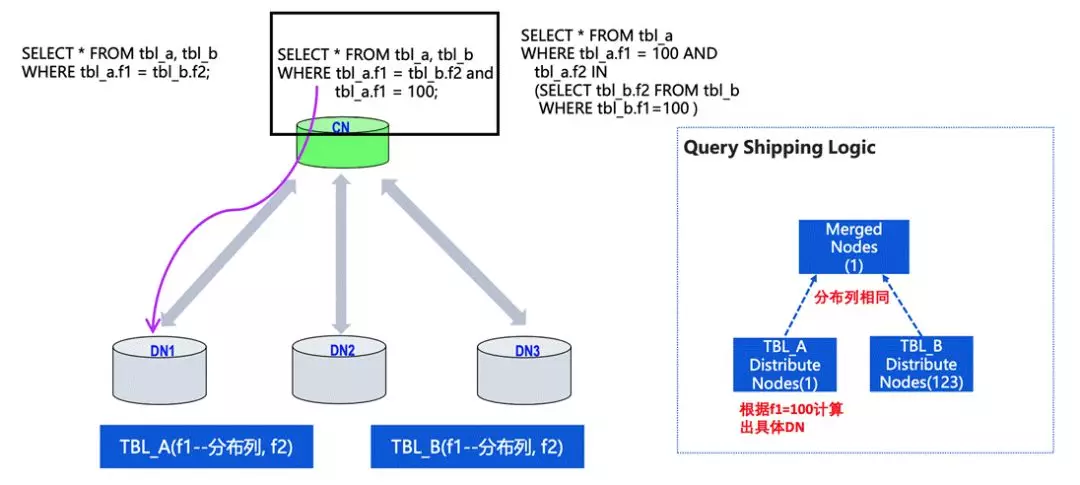
在這種情況下,CN 可以通過 f1 的值判斷具體推到哪個 DN 中去做,
還有一些更復雜的查詢,比如存在子查詢的情況,但方式也是類似的分析方法,
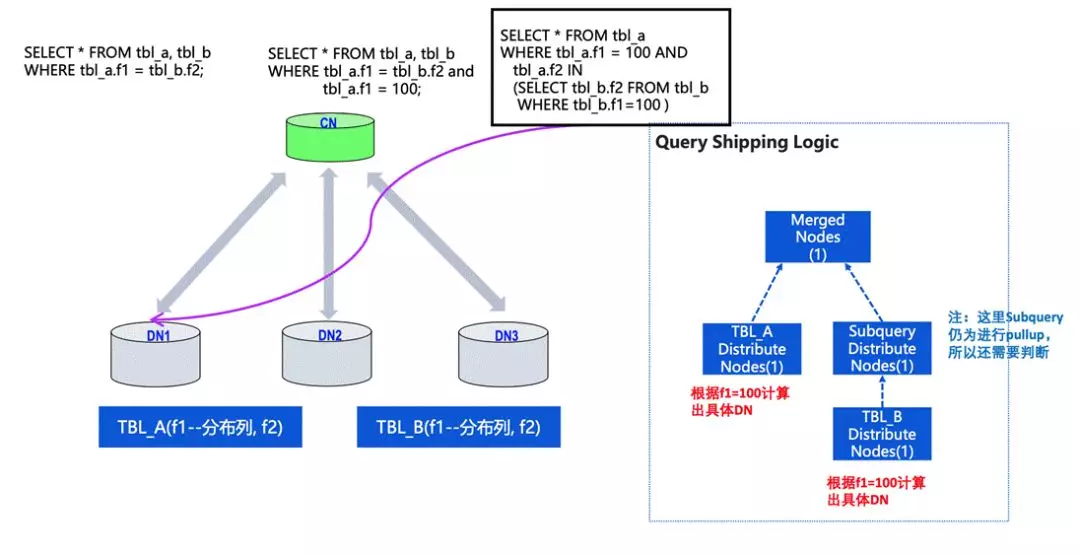
子查詢可能會有一個復雜情況,如果在多層的子查詢中都可以判斷出來跟上層有相同的單一節點分布情況,query 也可以下發到 DN 中,這種情況下對 OLTP 性能會有比較好的影響,集群的能力會得到比較好的優化,
針對比較復雜的 query,可能就需要涉及到優化配置的調整,

方式主要分為兩種:規則優化(RBO)和代價優化(CBO),RBO 主要是通過規則來判斷查詢計劃到底符不符合進行優化,這個是比較早期的一些實作方法,因為計算量相對較小,所以對某些場景比較高效,但明顯的缺點是彈性不足,同時不能用于比較復雜的場景,
實際上更多的這種資料庫使用的是 CBO 的方式,簡單講,CBO 會對所有路徑的進行動態規劃,選擇成本最小的一條作為執行計劃,這種方式的優點是有較好的適用性,能夠適合復雜場景的優化,性能表現較穩定,缺點是實作復雜,需要一定的前置條件,包括統計資訊、代價計算模型構建等,
但這也是不絕對的,兩者沒有誰可以“贏”過對方的說法,更多是需要對二者進行一個結合,TBase 主要是在 CBO 上進行優化,比如在計算一些小表的場景中,不需要進行 redistribution,直接 replication 就可以了,
關于分布式中文 distribution 的一些調整的情況,我們還是打個簡單的比方,兩張表,TBL_A 和 TBL_B,
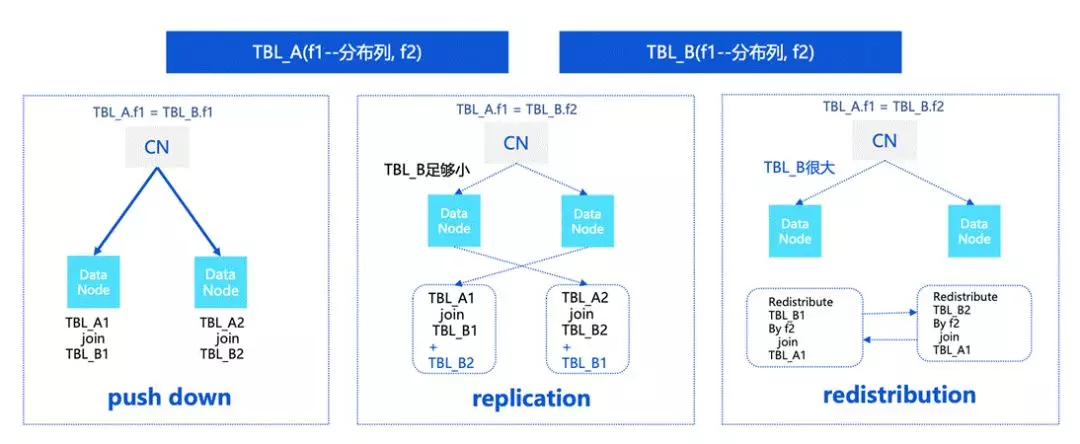
如果 f1 是分布列,分布類等值的情況下會變成 push down,這種情況下可以在 DN 上直接進行計算,
上圖中間的情況中,TBL_A 是分布鍵,TBL_B 是非分布鍵,在這種情況下,如果 TBL_B 足夠小,必須要對 TBL_B 進行重分布,也就是對 TBL_B 進行 replication,這時就會涉及到一些代價的估算,而如果 TBL_B 比較大的話,可能需要對 TBL_B 進行 redistribution,
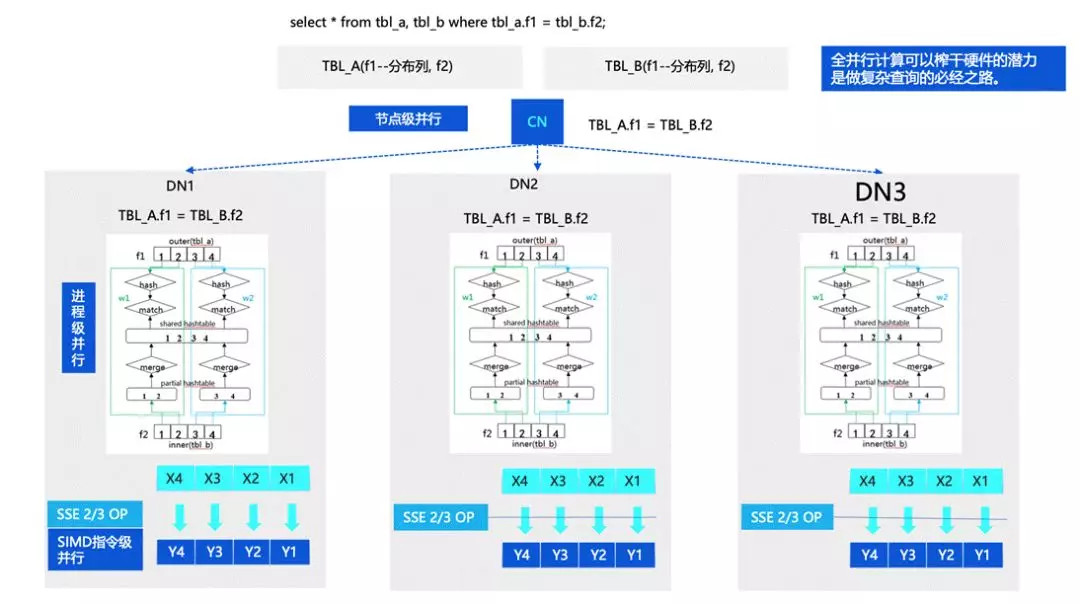
剛才我們也講到,TBase 在 OLAP 方面也有比較強的能力,這部分的優化思路主要是借助了計算的并行,計算的全并行能力主要體現在幾個方面,
首先是節點級的并行,因為我們是分布式的資料庫,所以可以有多個節點或者行程進行計算;另外一層是行程級的并行,目前 TBase 沒有改成執行緒模型,所以并行主要體現在行程級模型中,基于 PostgreSQL 行程并行的能力做了一些增強,還有一層是指令集的并行,對指令進行優化,后面也會對這部分進行持續的增強,
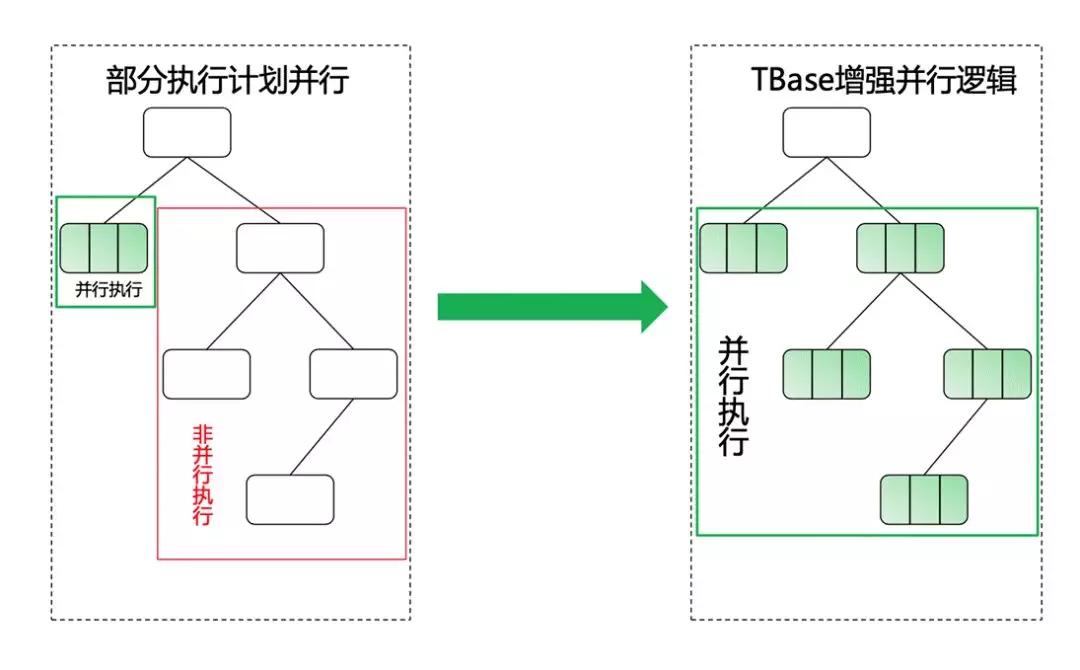
那么 Postgres 的查詢計劃,或者是行程并行的能力是如何實作的呢?最早期我們 follow 的是 PG10,并行能力并不是非常強,只提供了基礎的框架和部分算子的優化,這是 TBase 當時進行優化的一個點,
在分布式的情況下,很多單機可以進行并行,但在分布式中就不可以進行并行,所以我們希望對這些能力進行一些增強,從而保證更大范圍的一個并行能力,
并行計算其實是一種自底向上推演的方式,比如說底層的一個節點可以并行,那么如果遞推向上到了某一層不能并行,就可以把下面所有可以并行的地方加一個 Gather Node,把結果從多個行程中進行收集,繼續向上進行規劃,這也是我們希望增強的一個點,
下面我們介紹一些具體的優化,
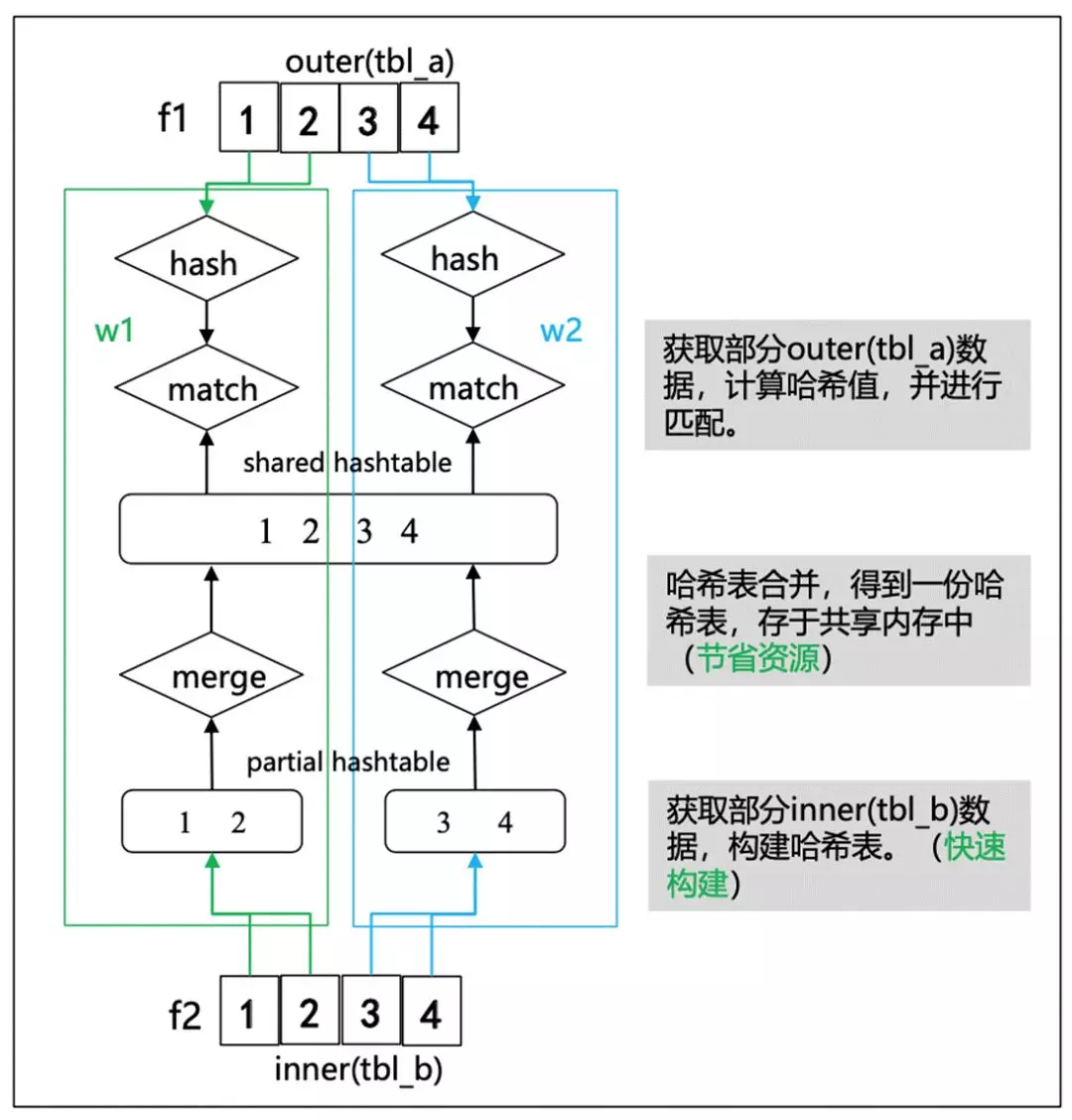
早期 PG 的 HashJoin 在 outer plan 是可以做并行的,但在 inner 構建 hash table 的情況則不能做并行的,
簡單來說,hashjoin 可以分為幾步,首先是 build hash table,第二步是獲取部分 outer plan 資料,計算哈希值,并進行匹配,這里我們將 inner hash table 構建程序也做了并行化處理,保證 Hashjoin 的左右子樹都可以進行并行,并繼續向上層節點推到并行化,
另外一種情況是 AGG(Aggregation),
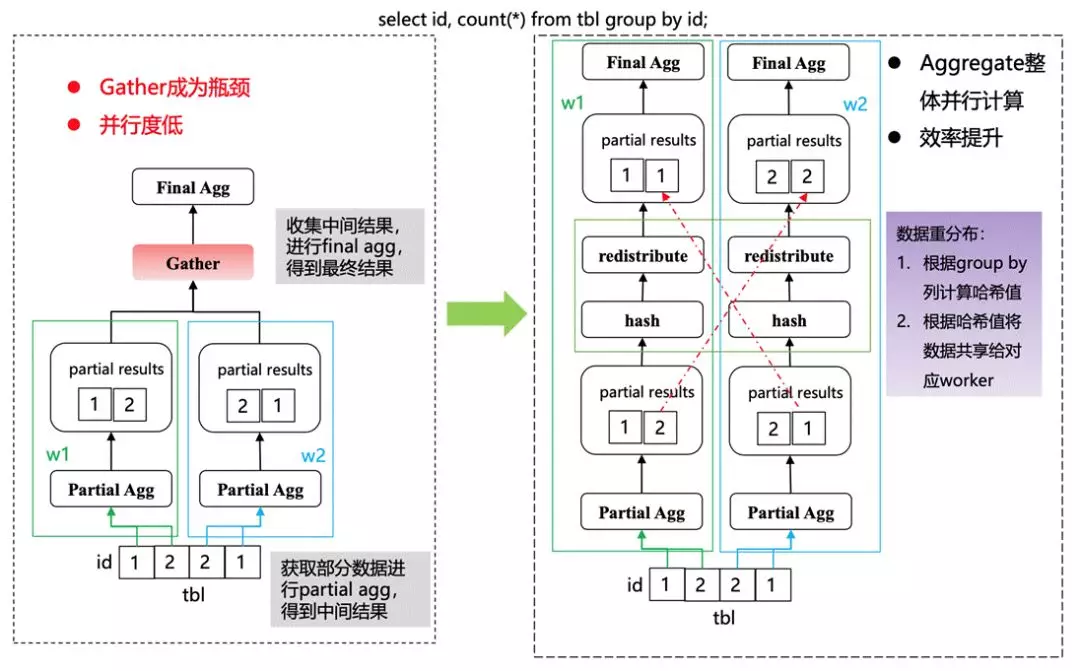
很多情況下都是一個兩階段的 Agg,需要在 DN 上做一些 partial agg,然后到上層計劃分片進一步做 final agg,實際上在這種情況下,中間碰到 redistribute 需要先在 DN 進行資料的整合,然后再去做 final 的 Agg,
在有多層子查詢的情況下,每一層都進行計算會導致最后整體的并行計算不會很高,所以我們在 redistribution 也做了一些并行,也就是在 Partial Agg 的情況下可以按照 hash 分布去發到對應的上層 DN 節點上進行并行,
還有一些資料傳輸方面的優化,
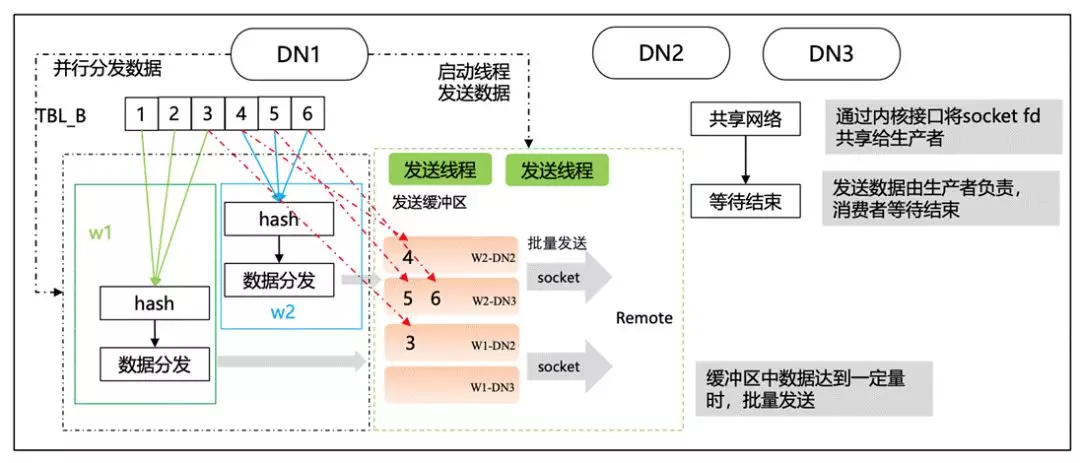
我們提到 redistributio 節點可以進行并行能力的增強,而在資料的接受和發送上也需要進行優化提升,早期的版本是單條的處理模式,網路的延遲會比較高,性能會不太好,所以我們在這部分進行了一些優化,從而實作比較好的并行執行的能力,
Part4 開源TBase企業級能力介紹
實際上 TBase 還做了一些企業級能力的增強,后面也持續的會去做一些開源貢獻和優化,

目前開源 Tbase 企業級已經可以實作多地多中心,或者是多活能力的構建,包括安全、管理、審計的能力,TBase 在安全上面有比較高的要求,后面也會持續的貢獻出來,
還有就是在水平擴展能力上,TBase 可以做到在用戶感知比較小的情況下進行擴容,擴容在大資料量的情況下是一個普遍的痛點,我們在這方面的能力上也會有一個持續的增強,
此外,TBase 還有自研的分析表以及冷熱資料的分離,也都是有比較好的效果,對于用戶成本的降低,還有資料分布的靈活性都會有比較好的提升,
TBase 在今年 7 月 13 號開源發布了 v2.1.0 版本,我們也持續的在開源能力上做著建設,包括多活能力的持續增強、維護性的增強,性能安全持續的升級,包括通過一些企業客戶發現的問題也都會持續的貢獻出來,還包括統計資訊增強以及增強對小表重分布的優化,也是希望大家可以持續關注 TBase,和我們進行更多的討論和切磋,
Part5 Q&A
Q:TBase的配置有哪些要求?
A:大家可以訪問 TBase 的開源版本,上面有具體的使用方法和基于原始碼的構建,還有搭建的流程,都有比較明確的檔案,如果大家想嘗試的話,可以使用正常的 X86 服務器或者本機的 Linux 服務器就可以做一些簡單的搭建,企業級專案上大家也可以做一些嘗試,保持溝通,
Q:為什么選擇基于 PostgreSQL 開發呢?
A:實際上大家會面臨 MySQL 和 PostgreSQL 兩個方向上的選擇,我主要介紹我們選擇 PostgreSQL 的原因,
一是 PostgreSQL 的協議會更加友好,在協議的靈活性上會比較好一些,大家可以隨意的對它的代碼做改動和完整發布,
另外它的內核實作上也比較嚴謹,有自己的獨到之處,持續的也在增強,包括它的迭代速度也是比較快,我們早期一直在跟進,持續的 merge PostgreSQL 的一些 feature,也是伴隨著 PostgreSQL 的成長,我們的內核也做了一個比較快速的迭代,同時我們也在了解內核的情況下,做了一些更深入的調優,
Q:DN節點的存盤集群是基于Raft嗎?多Leader還是單Leader呢?
A:目前我們的 DN 結點沒有用到 Raft 協議,是做的主備復制,我知道有很多新的業務會基于 Raft 的提交協議,或者是用這種復制的協議去做一致性和高可用,但實際上 Raft 的多副本對提交協議還是有一些性能影響的,整體的流程相對于傳統的會有更長的時延,相當于 CAP 原理,C提高了,A會有部分影響,
而我們更傾向于 OLTP 系統,所以在事務上的要求和時延回應的要求是比較高的,于是做了這樣的選擇,
Q:能詳細講講分布式事務的實作流程嗎?怎么樣保證多機之間的分布式事務,兩階段提交嗎?
A:現在我們基本是 follw 兩階段提交,一個是兩階段提交的控制流程、控制協議,另一個是事務隔離的協議,剛才主要講了 MVCC,在提交協議上基本上兩階段提交的增強版,
由于使用了 GTM,導致它和傳統的單機模式不太一樣,做了一些統一的協調,剛才也著重介紹了,這樣的一個優勢是減輕了 GTM 上的壓力,另外在 prepare 階段會有部分的阻塞情況,但在優化之后影響是非常小的,卻能極大的減輕 GTM 的壓力,
Q:底層的存盤是怎么同時滿足行存和列存的需求呢?還是按照塊(Tile)連續存盤?
A:我們開源版本的底層存盤主要是行存,后面會在列存和 HTAP 進行持續的增強,進一步提升 HTAP 的能力,等逐步穩定之后,會再考慮迭代開源版本,
Q:最少需要多少服務器搭建?
A:其實單點搭建也是可以的,一個 DN、一個 CN、一個 GTM 也可以,實際上最好布成兩 DN,可以體驗更多的分布式搭建,實際上我們在企業服務的集群上已經超過了上千個節點,包括解決 GTM 的單點壓力上,對集群整體的擴展性有比較好的提升,所以從兩個節點到多節點都可以去嘗試一下,
Q:GTM的授時,有采用batch或者pipeline嗎?還有現在Tbase支持的從庫的讀一致性嗎?
A:有的,GTM 的授時我們也做了更多的優化,簡單說可以做一些并行的 GTS 的單調授時,根據現行的規模或者是我們對客戶場景的預估,在 x86服務器中大概可以達到1200萬QPS的授時的能力,在增強服務器的情況下,整體的能力是比較強的,基本上不會在這部分產生瓶頸,
Q:tbase有什么安全保障機制?
A:從業務角度,我們講到了安全隔離,以及有很強的行級安全規則、列級訪問控制以及資料加密、脫敏增強,這些都可以傾向于向一個企業級的資料庫去應用,現在很多企業級服務的能力也在 TBase 里面,后面我們會根據情況進行進一步的迭代,

伍鑫,騰訊TBase資料庫專家工程師,在資料庫、資料復制、大資料計算等領域有豐富經驗,曾發表多篇相關論文、專利,加入騰訊前曾在IBM大資料分析團隊作業多年,后加入Hashdata資料庫創業公司,加入騰訊后,負責TBase資料庫優化器、執行器、分布式事務等多項核心功能研發,
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/209600.html
標籤:其他
上一篇:我在MySQL的那些年(一)
下一篇:JAVA體系書籍大全