資料治理意義重大,傳統的資料治理采用檔案的形式進行管理,已經無法滿足大資料下的資料治理需要,而適合于Hadoop大資料生態體系的資料治理就非常的重要了,
? 大資料下的資料治理作為很多企業的一個巨大的難題,能找到的資料的解決方案并不多,但是好在近幾年,很多公司已經進行了嘗試并開源了出來,本文將詳細分析這些資料發現平臺,在國外已經有了十幾種的實作方案,
資料發現平臺可以解決的問題
為什么需要一個資料發現平臺?
在資料治理程序中,經常會遇到這些問題: 資料都存在哪? 該如何使用這些資料? 資料是做什么的? 資料是如何創建的? 資料是如何更新的?
,,,,,
資料發現平臺的目的就是為了解決上面的問題,幫助更好的查找,理解和使用資料,
比如Facebook的Nemo就使用了全文檢索技術,這樣可以快速的搜索到目標資料,
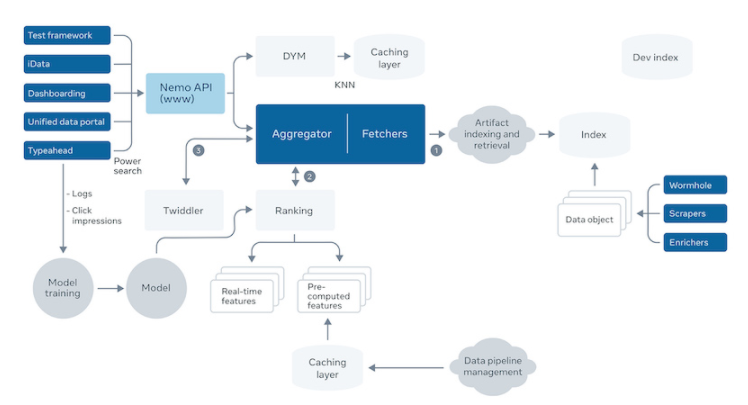
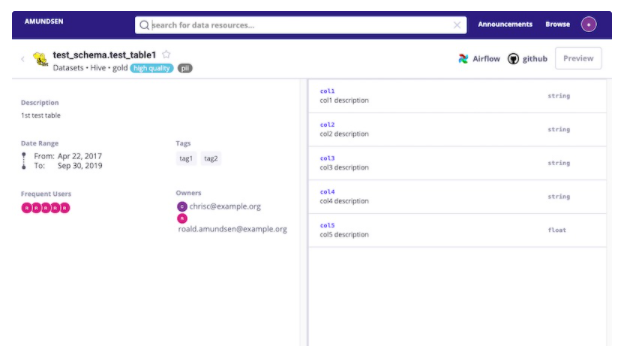
用戶瀏覽資料表時,如何快速的理解資料? 一般的方式是把列名,資料型別,描述顯示出來,如果用戶有權限,還可以預覽資料,
下面是Amundsen的資料列展示功能,
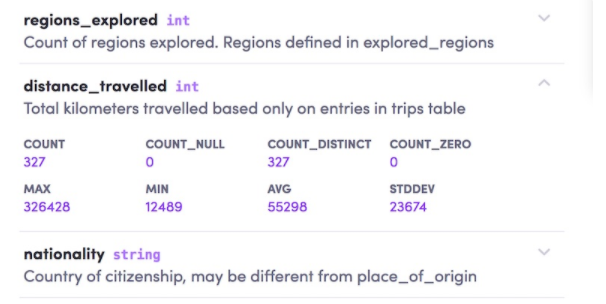
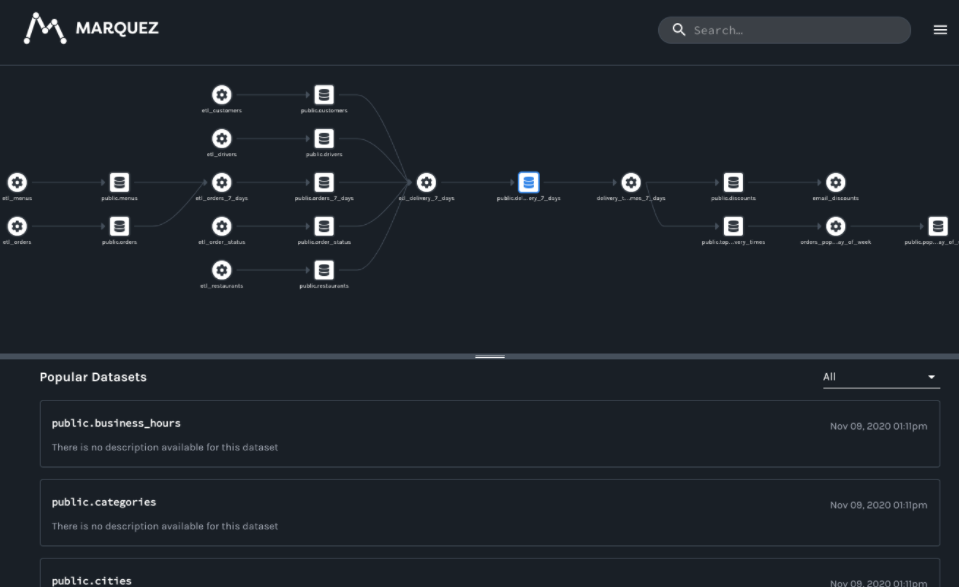
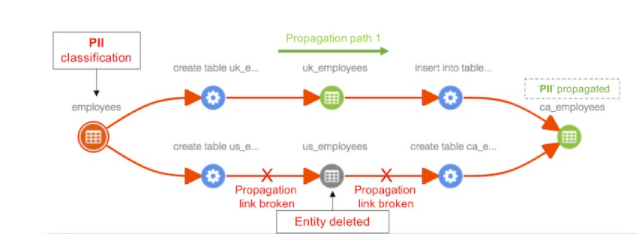
資料ETL是一個大問題,特別是如何把這些展示出來更是非常難,其實資料的ETL是可以用資料的流向圖表示的,很多平臺都支持這種功能,比如 Databook,還有Metcat,
Amundsen就和資料調度平臺Airflow有著非常好的結合,
資料發現平臺對比
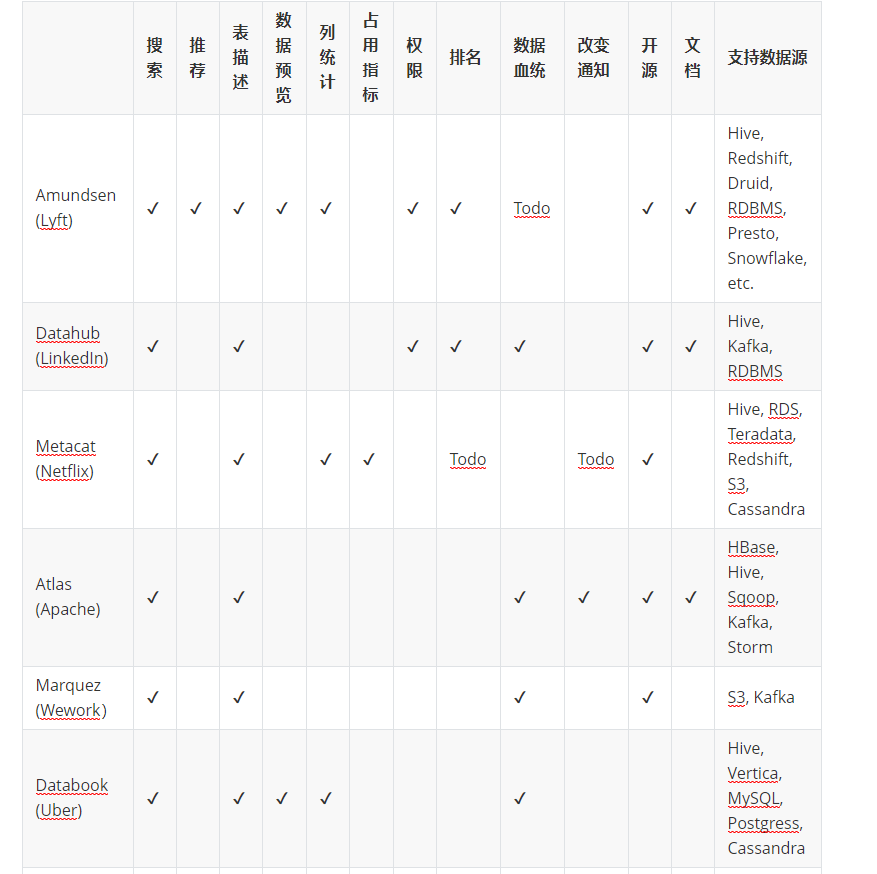
下面一張表 對比一下各大平臺對于上述功能的支持情況
| 搜索 | 推薦 | 表描述 | 資料預覽 | 列統計 | 占用指標 | 權限 | 排名 | 資料血統 | 改變通知 | 開源 | 檔案 | 支持資料源 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Amundsen (Lyft) | ? | ? | ? | ? | ? | ? | ? | Todo | ? | ? | Hive, Redshift, Druid, RDBMS, Presto, Snowflake, etc. | ||
| Datahub (LinkedIn) | ? | ? | ? | ? | ? | ? | ? | Hive, Kafka, RDBMS | |||||
| Metacat (Netflix) | ? | ? | ? | ? | Todo | Todo | ? | Hive, RDS, Teradata, Redshift, S3, Cassandra | |||||
| Atlas (Apache) | ? | ? | ? | ? | ? | ? | HBase, Hive, Sqoop, Kafka, Storm | ||||||
| Marquez (Wework) | ? | ? | ? | ? | S3, Kafka | ||||||||
| Databook (Uber) | ? | ? | ? | ? | ? | Hive, Vertica, MySQL, Postgress, Cassandra | |||||||
| Dataportal (Airbnb) | ? | ? | ? | ? | ? | Unknown | |||||||
| Data Access Layer (Twitter) | ? | ? | ? | HDFS, Vertica, MySQL | |||||||||
| Lexikon (Spotify) | ? | ? | ? | ? | ? | Unknown |
這里介紹一下五個開源的解決方案
DataHub (LinkedIn)
LinkedIn開源出來的,原來叫做WhereHows ,經過一段時間的發展datahub于2020年2月在Github開源
https://github.com/linkedin/datahub
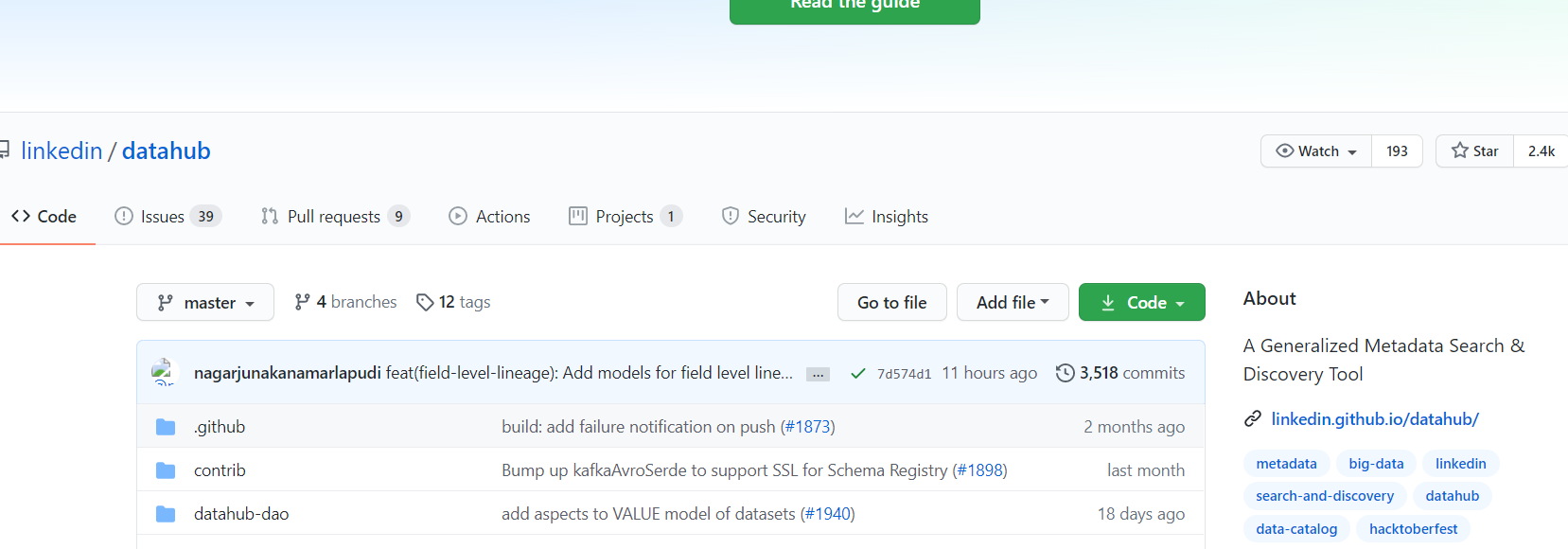
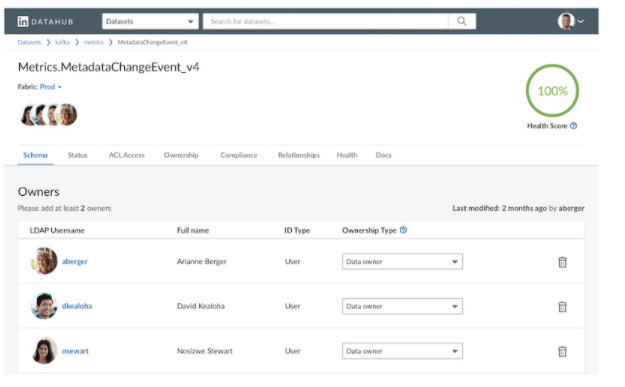
可以說是一個非常充滿活力的專案,有著表結構,搜索,資料血統等功能,還有用戶和組等功能,
官方也提供了檔案,開源版本支持Hive,Kafka和關系資料庫中的元資料,
所以Datahub的使用率還是非常高的,
Amundsen (Lyft)
Lyft 于2019年4月開發了Amundsen,并與10月開源,
https://github.com/amundsen-io/amundsen
Amundsen提供了搜索與排名的功能,幫助更好的查找資料表,
支持的資料源非常豐富,支持hive ,druid等超過15個資料源,而且還提供與任務調度airflow的融合,并提供了與superset等BI工具的集成方式,
而資料血統的功能也正在開發之中,
Metacat(Netflix)
Netflix在2018年6月開源了Metacat,
Metacat支持Hive,Teradata,Redshift,S3,Cassandra和RDS的集成,
不過雖然Metacat開源,但是官方沒有提供檔案,資料也很少,
Marquez (WeWork)
Wework于2018年10月開源了Marquez
Marquez也對Airflow有著很好的支持,
可以看到Marquez還在持續的更新中,保持關注,
Apache Atlas(Hortonworks)
作為資料治理計劃的一部分,Atlas于2015年7月開始在Hortonworks進行范訓,
Atlas 1.0于2018年6月發布,當前版本是2.1,
Atlas的主要目標是資料治理,支持與HBase,Hive和Kafka的集成,
github地址
https://github.com/apache/atlas
豐富的檔案

如何選擇
首先說一下筆者的選擇,雖然對datahub和amundsen非常的感興趣,最后還是選擇了Atlas,
開源,檔案的豐富程度,功能,這些在上文表格中都做了詳細的對比,如何選擇還是要考慮實際情況,
開源的有五家: Amundsen Datahub Metacat Marquez Atlas
有檔案的有三家: Amundsen Datahub Atlas
搜索功能較強 : Amundsen
有資料血統功能: Datahub Atlas
考慮到專案的周期,實施性等情況,還是建議大家從Atlas入門,打開資料治理的探索之路,
當然也有公司同時采用了Atlas和Amundsen,Atlas處理元資料管理,利用Amundsen強大的資料搜索能力來做資料搜索,這也是一種不錯的選擇,
歡迎大家關注 “實時流式計算”
未來, “實時流式計算” 將推出Atlas 2.1 部署與實踐 系列文章,推開資料治理之門,
更多Flink,Kafka等實時大資料分析相關技術博文,科技資訊,歡迎關注實時流式計算 公眾號后臺回復 “電子書” 下載300頁Flink實戰電子書

?
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/210538.html
標籤:其他