HDFS架構
官網地址
HDFS采用主/從架構,HDFS群集由單個NameNode和多個DataNode組成,
簡單一致性模型
HDFS應用程式需要檔案的一寫多讀訪問模式,檔案一旦創建、寫入和關閉,除了追加和截斷外,不需要更改,支持將內容追加到檔案末尾,但不能在任意位置更新,此假設簡化了資料一致性問題,并實作了高吞吐量資料訪問,MapReduce應用程式或Web爬蟲應用程式非常適合此模型,
“移動計算比移動資料更劃算”(“Moving Computation is Cheaper than Moving Data”)
NameNode and DataNodes
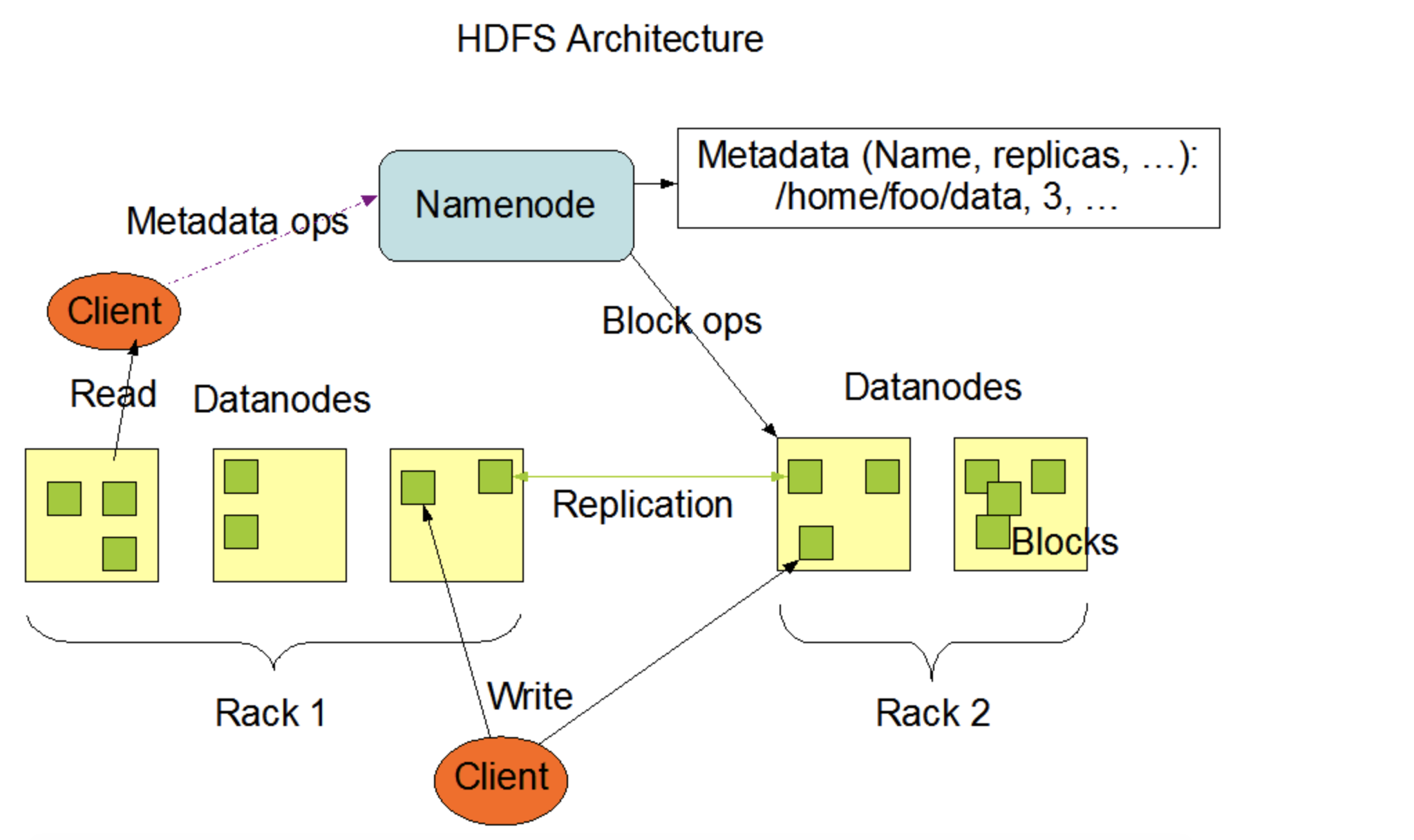
NameNode的職責:
- 控制客戶端對檔案的訪問(客戶端對檔案的訪問必須經過NN)
- NameNode執行檔案系統命名空間 (namespace) 操作,如打開、關閉和重命名檔案和目錄
- 決定了塊 (Data Block) 到DataNode的映射
DataNode的職責:
- 真正存盤資料(Block)
- DataNode負責為客戶端的讀寫請求提供服務
- DataNode還根據NameNode的指示執行塊 (Data Block) 的創建、洗掉和復制
典型的部署有一臺只運行NameNode軟體的專用機器,集群中的每臺其他機器都運行DataNode軟體的一個實體,NameNode是所有HDFS元資料的仲裁器和存盤庫,系統的設計方式是用戶資料永遠不會流經NameNode,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/212755.html
標籤:其他
上一篇:Mysql資料庫的事務特性、隔離級別及MVCC多版本并發控制簡介
下一篇:pe移除密碼后無法設定新密碼