MongoDB相關概念
業務應用場景
傳統的關系型資料庫(如MySQL),在資料操作的“三高”需求以及應對Web2.0的網站需求面前,顯得力不從心,
解釋:“三高”需求:
- High performance - 對資料庫高并發讀寫的需求,
- Huge Storage - 對海量資料的高效率存盤和訪問的需求,
- High Scalability && High Availability- 對資料庫的高可擴展性和高可用性的需求,
而MongoDB可應對“三高”需求,
具體的應用場景如:
1)社交場景,使用
MongoDB存盤存盤用戶資訊,以及用戶發表的朋友圈資訊,通過地理位置索引實作附近的人、地點等功能,2)游戲場景,使用
MongoDB存盤游戲用戶資訊,用戶的裝備、積分等直接以內嵌檔案的形式存盤,方便查詢、高效率存盤和訪問,3)物流場景,使用
MongoDB存盤訂單資訊,訂單狀態在運送程序中會不斷更新,以MongoDB內嵌陣列的形式來存盤,一次查詢就能將訂單所有的變更讀取出來,
4)物聯網場景,使用
MongoDB存盤所有接入的智能設備資訊,以及設備匯報的日志資訊,并對這些資訊進行多維度的分析,5)視頻直播,使用
MongoDB存盤用戶資訊、點贊互動資訊等,
這些應用場景中,資料操作方面的共同特點是:
(1)資料量大
(2)寫入操作頻繁(讀寫都很頻繁)
(3)價值較低的資料,對事務性要求不高
對于這樣的資料,我們更適合使用MongoDB來實作資料的存盤,
?? 什么時候選擇MongoDB
在架構選型上,除了上述的三個特點外,如果你還猶豫是否要選擇它?可以考慮以下的一些問題:
應用不需要事務及復雜
join支持新應用,需求會變,資料模型無法確定,想快速迭代開發
應用需要
2000-3000以上的讀寫QPS(更高也可以)應用需要TB甚至 PB 級別資料存盤
應用發展迅速,需要能快速水平擴展
應用要求存盤的資料不丟失
應用需要99.999%高可用
應用需要大量的地理位置查詢、文本查詢
如果上述有1個符合,可以考慮
MongoDB,2個及以上的符合,選擇MongoDB絕不會后悔,
MongoDB簡介
MongoDB是一個開源、高性能、無模式的檔案型資料庫,當初的設計就是用于簡化開發和方便擴展,是NoSQL資料庫產品中的一種,是最像關系型資料庫(MySQL)的非關系型資料庫,它支持的資料結構非常松散,是一種類似于
JSON的 格式叫BSON,所以它既可以存盤比較復雜的資料型別,又相當的靈活,
MongoDB中的記錄是一個檔案,它是一個由欄位和值對(fifield:value)組成的資料結構,MongoDB檔案類似于JSON物件,即一個檔案認為就是一個物件,欄位的資料型別是字符型,它的值除了使用基本的一些型別外,還可以包括其他檔案、普通陣列和檔案陣列,
體系結構
?? MySQL和MongoDB的對比:
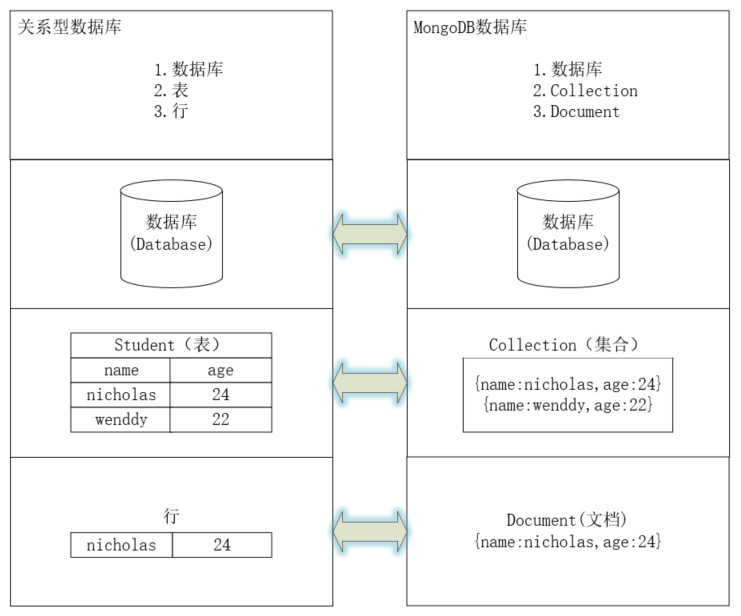
| SQL術語概念 | MongoDB術語/概念 | 解釋/說明 |
|---|---|---|
| database | database | 資料庫 |
| table | collection | 資料庫表/集合 |
| row | document | 資料記錄行/檔案 |
| column | field | 資料欄位/域 |
| index | index | 索引 |
| table joins | 表連接,MongoDB不支持 | |
| 嵌入檔案 | MongoDB通過嵌入式檔案來替代多表連接 | |
| primary key | primary key | 主鍵,MongoDB自動將_id欄位設定為主鍵 |
資料模型
MongoDB的最小存盤單位就是檔案(document)物件,檔案(document)物件對應于關系型資料庫的行,資料在MongoDB中已BSON(Binary-JSON)檔案的格式存盤在磁盤上,
BSON(Binary Serialized Document Format)是一種類json的一種二進制形式的存盤格式,簡稱Binary JSON,BSON和JSON一樣,支持內嵌的檔案物件和陣列物件,但是BSON有JSON沒有的一些資料型別,如Date和BinData型別,
Bson中,除了基本的JSON型別:string,integer,boolean,double,null,array和object,mongo還使用了特殊的資料型別,這些型別包括date,object id,binary data,regular expression 和code,每一個驅動都以特定語言的方式實作了這些型別,查看你的驅動的檔案來獲取詳細資訊,
BSON資料型別參考串列:
| 資料型別 | 描述 | 舉例 |
|---|---|---|
| 字串 | UTF-8字串都可表示為字串型別的資料 | {"X":"foobar"} |
| 物件id | 物件id是檔案的12位元組的唯一ID | {"X" :ObjectId() } |
| 布林值 | 真或者假:true或者false | {"x":true}+ |
| 陣列 | 值的集合或者串列可以表示成陣列 | {"x" : ["a", "b", "c"]} |
| 32位整數 | 型別不可用,JavaScript僅支持64位浮點數,所以32位整數會被自動轉換 | shell是不支持該型別的,shell中默認會轉換成64位浮點數 |
| 64位整數 | 不支持這個型別,shell會使用一個特殊的內嵌檔案來顯示64位整數 | shell是不支持該型別的,shell中默認會轉換成64位浮點數 |
| 64位浮點數 | shell中的數字就是這一種型別 | {"x":3.14159,"y":3} |
| null | 表示空值或者未定義的物件 | {"x":null} |
| undefifined | 檔案中也可以使用未定義型別 | {"x":undefifined} |
| 符號 | shell不支持,shell會將資料庫中的符號型別的資料自動轉換成字串 | |
| 正則運算式 | 檔案中可以包含正則運算式,采用JavaScript的正則運算式語法 | {"x" : /foobar/i} |
| 代碼 | 檔案中還可以包含JavaScript代碼 | {"x" : function() { /* …… */ }} |
| 二進制資料 | 二進制資料可以由任意位元組的串組成,不過shell中無法使用 | |
| 最大值/最小值 | BSON包括一個特殊型別,表示可能的最大值,shell中沒有這個型別 |
提示:
shell默認使用64位浮點型數值,{“x”:3.14}或{“x”:3},對于整型值,可以使用NumberInt(4位元組符號整數)或NumberLong(8位元組符號整數),{“x”:NumberInt(“3”)}{“x”:NumberLong(“3”)}
MongoDB的特點
-
高性能:
MongoDB提供高性能的資料持久性,特別是,
對嵌入式資料模型的支持減少了資料庫系統上的I/O活動,
索引支持更快的查詢,并且可以包含來自嵌入式檔案和陣列的鍵,(文本索引解決搜索的需求、TTL索引解決歷史資料自動過期的需求、地理位置索引可用于構建各種 O2O 應用)
mmapv1、wiredtiger、mongorocks(rocksdb)、in-memory 等多引擎支持滿足各種場景需求,
Gridfs解決檔案存盤的需求,
-
高可用性:
MongoDB的復制工具稱為副本集(replica set),它可提供自動故障轉移和資料冗余,
-
高擴展性:
MongoDB提供了水平可擴展性作為其核心功能的一部分,
分片將資料分布在一組集群的機器上,(海量資料存盤,服務能力水平擴展)
從3.4開始,MongoDB支持基于片鍵創建資料區域,在一個平衡的集群中,MongoDB將一個區域所覆寫的讀寫只定向到該區域內的那些片,
-
豐富的查詢支持:
MongoDB支持豐富的查詢語言,支持讀和寫操作(CRUD),比如資料聚合、文本搜索和地理空間查詢等,
-
其他特點:
如無模式(動態模式)、靈活的檔案模型、
MongoDB中的基本概念
?? 資料庫
- 一個
mongodb中可以建立多個資料庫,MongoDB的默認資料庫為"db",該資料庫存盤在data目錄中MongoDB的單個實體可以容納多個獨立的資料庫,每一個都有自己的集合和權限,不同的資料庫也放置在不同的檔案中,
?? 集合
- 集合就是
MongoDB檔案組,類似于RDBMS(關系資料庫管理系統:Relational Database Management System)中的表格,- 集合存在于資料庫中,集合沒有固定的結構,對集合可以插入不同格式和型別的資料,但通常情況下我們插入集合的資料都會有一定的關聯性,
集合命名的時候應該注意:
- 集合名不能是空字串"",
- 集合名不能含有\0字符(空字符),這個字符表示集合名的結尾,
- 集合名不能以"system."開頭,這是為系統集合保留的前綴,
- 用戶創建的集合名字不能含有保留字符,
?? 檔案(document)
是一組鍵值(key-value)對(即
BSON),MongoDB的檔案不需要設定相同的欄位,并且相同的欄位不需要相同的資料型別,這與關系型資料庫有很大的區別,也是MongoDB非常突出的特點,需要注意的是:
- 檔案中的鍵/值對是有序的,
- 檔案中的值不僅可以是在雙引號里面的字串,還可以是其他幾種資料型別,
- MongoDB區分型別和大小寫,
- MongoDB的檔案不能有重復的鍵,
- 檔案的鍵是字串,
MongoDB部署
1.下載軟體包
# wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.4.1.tgz
2.解壓縮
# tar -xvzf mongodb-linux-x86_64-rhel70-4.4.1.tgz
# mv mongodb-linux-x86_64-rhel70-4.4.1 /usr/local/mongodb
3.創建資料目錄、日志目錄、組態檔存放目錄
# mkdir /usr/local/mongodb/{data,conf,log}
4.編輯組態檔
# cat >>/usr/local/mongodb/conf/mongodb.conf<<EOF
dbpath=/usr/local/mongodb/data
logpath=/usr/local/mongodb/log/mongodb.log
bind_ip=0.0.0.0
port=27017
logappend=1
fork=1
EOF
5.添加環境變數
# vim /etc/profile
export MONGODB_HOME=/usr/local/mongodb
export PATH=$PATH:$MONGODB_HOME/bin
# source /etc/profile
6.啟動
# mongod --config /usr/local/mongodb/conf/mongodb.conf
# ps -ef |grep mongo
root 3969694 1 0 10:19 ? 00:01:06 mongod --config /usr/local/mongodb/conf/mongodb.conf
?? 停止mongodb
停止服務的方式有兩種:快速關閉和標準關閉
1.快速關閉方法(快速,簡單,資料可能會出錯)
目標:通過系統的kill命令直接殺死行程,殺完要檢查一下,避免有的沒有殺掉,
通過行程編號關閉節點
# kill -2 3969694
2.標準的關閉方法(資料不容易出錯,但麻煩)
目標:通過mongo客戶端中的shutdownServer命令來關閉服務
//客戶端登錄服務,注意,這里通過localhost登錄,如果需要遠程登錄,必須先登錄認證才行,
> mongo --port 27017
//#切換到admin庫
> use admin
//關閉服務
> db.shutdownServer()
補充
如果一旦是因為資料損壞,則需要進行如下操作(了解):
1.洗掉lock檔案
# rm -f /usr/local/mongodb/data/mongod.lock
2.修復資料
# mongod --repair --dbpath=/usr/local/mongodb/data/
常用命令
MongoDB庫操作
?? MongoDB系統保留庫說明:
系統保留資料庫:可以直接訪問這些有特殊作用的資料庫,
- admin:從權限的角度來看,這是"root"資料庫
- local:這個資料永遠不會被復制,可以用來存盤限于本地單臺服務器的任意集合;
- config:當Mongo用于分片設定時,config資料庫在內部使用,用于保存分片的相關資訊,
?? 選擇和創建資料庫
> use 資料庫名
如果資料庫不存在,則創建資料庫,否則切換到指定的資料庫,
> use articledb
?? 查看當前服務器的所有資料庫
> show databases
或
> show dbs
?? 查看當前正在使用的資料庫
> db
?? 洗掉資料庫
> db.dropDatabase()
備注:主要用來洗掉已經持久化的資料庫
注意: 要洗掉哪個資料庫,一定要先切換到要洗掉的資料庫中,然后再進行db.dropDatabase()
MongoDB集合操作
?? 集合的顯示創建
基本語法:
> db.createCollection(name, options)
其中
- name:要創建的集合名稱
- options:可選引數,指定有關記憶體大小及索引的選項(一下為可選引數串列)
options引數如下:
| 欄位 | 型別 | 描述 |
|---|---|---|
| capped | 布爾 | (可選)如果為true,則創建固定集合,固定集合是指有著固定大小的集合,當達到最大值時,它會自動覆寫最早的檔案,當改值為true時,必須指定size引數, |
| autoIndexld | 布爾 | (可選)如果為true,自動在_id欄位創建索引,默認為true, |
| size | 數值 | (可選)為固定集合指定一個最大值,以千位元組計(KB),如果capped為true,也需要指定該欄位, |
| max | 數值 | (可選)指定固定集合中包含檔案的最大值, |
?? 示例
創建一個集合testcol
> db.createCollection("testcol");
{ "ok" : 1 }
//創建集合student
> db.createCollection("student");
{ "ok" : 1 }
//創建固定大小的集合,創建固定集合mycol,整個集合空間大小6142800KB,檔案最大個數為10000個,
> db.createCollection("mycol",{capped:true,size:6142800,max:10000});
{ "ok" : 1 }
> show tables;
mycol
student
testcol
//創建固定大小的集合,創建固定集合mycol02,整個集合空間大小6142800KB,檔案最大個數為10000個,
> db.createCollection("mycol02",{capped:true,size:6142800,max:10000, autoIndexId:true});
{
"note" : "The autoIndexId option is deprecated and will be removed in a future release",
"ok" : 1
}
注意 在MongoDB中,集合只有在內容插入后才會創建! 就是說,創建集合(資料表)后要再插入一個檔案(記錄),集合才會真正創建,
?? 集合的隱式創建
當向一個集合中插入一個檔案的時候,如果集合不存在,則會自動創建集合,
?? 集合的查看
> show collections
或者
> show tables
?? 集合的洗掉
集合洗掉語法格式如下:
> db.collection.drop()
或
> db.集合.drop()
如果成功洗掉選定集合,則drop()方法回傳true,否則回傳false.
例如:要洗掉testcol集合
> db.testcol.drop()
true
檔案基本CRUD
檔案(document)的資料結構和
JSON基本一樣,所有存盤在集合中的資料都是BSON格式,
檔案的插入
?? 單個檔案插入
語法如下:
db.COLLECTION_NAME.insert(document)
示例:
> use testcoll
switched to db testcoll
> db.student.insert({name:"小白",age:18,sdept:"計算機系",sex:"男",createdatetime:new Date()})
WriteResult({ "nInserted" : 1 })
> db.student.find()
{ "_id" : ObjectId("5fa125ec481bd6c96002a80b"), "name" : "小白", "age" : 18, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-03T09:42:04.517Z") }
?? 批量檔案插入
語法如下:
db.COLLECTION_NAME.insertMany([document1, document2,...])
示例:
> db.student.insertMany(
[
{name:"張大仙",age:19,sdept:"計算機系",sex:"男",createdatetime:new Date()},
{name:"李太白",age:17,sdept:"計算機系",sex:"男",createdatetime:new Date()}
]
)
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("5fa255ab45dc2c9556990f3f"),
ObjectId("5fa255ab45dc2c9556990f40")
]
}
> db.student.find()
{ "_id" : ObjectId("5fa125ec481bd6c96002a80b"), "name" : "小白", "age" : 18, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-03T09:42:04.517Z") }
{ "_id" : ObjectId("5fa255ab45dc2c9556990f3f"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T07:18:03.528Z") }
{ "_id" : ObjectId("5fa255ab45dc2c9556990f40"), "name" : "李太白", "age" : 17, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T07:18:03.528Z") }
檔案的更新
語法如下:
db.COLLECTION_NAME.update(
<query>{鍵名:值},
<update>{$set:{鍵名:值}},
{
upsert:<boolean>,
multi:<boolean>
}
)
引數說明:
query:update的查詢條件
update:update的物件和更新的運算子$set,可以理解為sql update查詢內set后面的
upsert:可選,意思是,如果不存在update的記錄,是否插入,true為插入,默認是false,不插入,
multi:可選,mongodb默認是false,只更新找到的第一條記錄,如果為true,就把按條件查出來多條記錄全部更新,
示例:
?? 修改匹配的第一條記錄
> db.student.update(
{sex:"男"},
{$set:{sdept:"前端"}},
)
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.student.find()
{ "_id" : ObjectId("5fa125ec481bd6c96002a80b"), "name" : "小白", "age" : 18, "sdept" : "前端", "sex" : "男", "createdatetime" : ISODate("2020-11-03T09:42:04.517Z") }
{ "_id" : ObjectId("5fa255ab45dc2c9556990f3f"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T07:18:03.528Z") }
{ "_id" : ObjectId("5fa255ab45dc2c9556990f40"), "name" : "李太白", "age" : 17, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T07:18:03.528Z") }
?? 修改匹配的所有記錄
> db.student.update(
{sex:"男"},
{$set:{sdept:"后端"}},
{multi:true}
)
WriteResult({ "nMatched" : 3, "nUpserted" : 0, "nModified" : 3 })
> db.student.find()
{ "_id" : ObjectId("5fa125ec481bd6c96002a80b"), "name" : "小白", "age" : 18, "sdept" : "后端", "sex" : "男", "createdatetime" : ISODate("2020-11-03T09:42:04.517Z") }
{ "_id" : ObjectId("5fa255ab45dc2c9556990f3f"), "name" : "張大仙", "age" : 19, "sdept" : "后端", "sex" : "男", "createdatetime" : ISODate("2020-11-04T07:18:03.528Z") }
{ "_id" : ObjectId("5fa255ab45dc2c9556990f40"), "name" : "李太白", "age" : 17, "sdept" : "后端", "sex" : "男", "createdatetime" : ISODate("2020-11-04T07:18:03.528Z") }
?? 匹配多個條件(同時滿足)
> db.student.update(
{sex:"男", name:"小白"},
{$set:{sdept:"計算機系"}},
)
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.student.find()
{ "_id" : ObjectId("5fa125ec481bd6c96002a80b"), "name" : "小白", "age" : 18, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-03T09:42:04.517Z") }
{ "_id" : ObjectId("5fa255ab45dc2c9556990f3f"), "name" : "張大仙", "age" : 19, "sdept" : "后端", "sex" : "男", "createdatetime" : ISODate("2020-11-04T07:18:03.528Z") }
{ "_id" : ObjectId("5fa255ab45dc2c9556990f40"), "name" : "李太白", "age" : 17, "sdept" : "后端", "sex" : "男", "createdatetime" : ISODate("2020-11-04T07:18:03.528Z") }
?? 更新多個值
> db.student.update(
{sex:"男", name:"小白"},
{$set:{sdept:"英語系", age:22}},
)
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.student.find()
{ "_id" : ObjectId("5fa125ec481bd6c96002a80b"), "name" : "小白", "age" : 22, "sdept" : "英語系", "sex" : "男", "createdatetime" : ISODate("2020-11-03T09:42:04.517Z") }
{ "_id" : ObjectId("5fa255ab45dc2c9556990f3f"), "name" : "張大仙", "age" : 19, "sdept" : "后端", "sex" : "男", "createdatetime" : ISODate("2020-11-04T07:18:03.528Z") }
{ "_id" : ObjectId("5fa255ab45dc2c9556990f40"), "name" : "李太白", "age" : 17, "sdept" : "后端", "sex" : "男", "createdatetime" : ISODate("2020-11-04T07:18:03.528Z") }
?? 多個條件滿足其中一個($or)
> db.student.update(
{$or:[{sex:19}, {name:"小白"}]},
{$set:{sdept:"數學系", age:22}},
)
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.student.find()
{ "_id" : ObjectId("5fa125ec481bd6c96002a80b"), "name" : "小白", "age" : 22, "sdept" : "數學系", "sex" : "男", "createdatetime" : ISODate("2020-11-03T09:42:04.517Z") }
{ "_id" : ObjectId("5fa255ab45dc2c9556990f3f"), "name" : "張大仙", "age" : 19, "sdept" : "后端", "sex" : "男", "createdatetime" : ISODate("2020-11-04T07:18:03.528Z") }
{ "_id" : ObjectId("5fa255ab45dc2c9556990f40"), "name" : "李太白", "age" : 17, "sdept" : "后端", "sex" : "男", "createdatetime" : ISODate("2020-11-04T07:18:03.528Z") }
檔案的洗掉
語法如下:
db.COLLECTION_NAME.remove(
<query>,
{
justOne:<boolean>
}
)
引數說明:
query:(可選)洗掉的檔案的條件,
justOne:(可選)如果設定為true或1,則只洗掉一個檔案,如果不設定該引數,或使用默認值false,則洗掉所有匹配條件的檔案,
示例:
?? 洗掉符合條件的第一條(justOne.true)
> db.student.remove(
{sex:"男"},
{justOne:true}
)
WriteResult({ "nRemoved" : 1 })
> db.student.find()
{ "_id" : ObjectId("5fa255ab45dc2c9556990f3f"), "name" : "張大仙", "age" : 19, "sdept" : "后端", "sex" : "男", "createdatetime" : ISODate("2020-11-04T07:18:03.528Z") }
{ "_id" : ObjectId("5fa255ab45dc2c9556990f40"), "name" : "李太白", "age" : 17, "sdept" : "后端", "sex" : "男", "createdatetime" : ISODate("2020-11-04T07:18:03.528Z") }
?? 洗掉符合條件的所有記錄
> db.student.remove(
{sex:"男"}
)
?? 洗掉所有記錄
> db.student.remove({})
檔案的查詢
MongoDB查詢檔案使用find()方法,使用findOne()查詢一條資料
find()方法以非結構化的方式來顯示所有的檔案語法格式:
db.COLLECTION_NAME.find(query,projection) 注意: query:可選,使用查詢運算子指定查詢條件 projection:可選,使用投影運算子指定回傳的值 需要以格式化的方式來讀取資料,可以使用pretty()方法,
查詢前先造幾條資料
db.student.insertMany(
[
{name:"張大仙",age:19,sdept:"計算機系",sex:"男",createdatetime:new Date()},
{name:"李太白",age:17,sdept:"計算機系",sex:"男",createdatetime:new Date()},
{name:"黃花",age:18,sdept:"英語系",sex:"女",createdatetime:new Date()},
{name:"菜花",age:20,sdept:"數學系",sex:"女",createdatetime:new Date()},
]
)
基本查詢
?? 查詢student集合中所有的檔案
> db.student.find()
{ "_id" : ObjectId("5fa27688b808fba58f5a3a41"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T09:38:16.820Z") }
{ "_id" : ObjectId("5fa27688b808fba58f5a3a42"), "name" : "李太白", "age" : 17, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T09:38:16.820Z") }
{ "_id" : ObjectId("5fa27688b808fba58f5a3a43"), "name" : "黃花", "age" : 18, "sdept" : "英語系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T09:38:16.820Z") }
{ "_id" : ObjectId("5fa27688b808fba58f5a3a44"), "name" : "菜花", "age" : 20, "sdept" : "數學系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T09:38:16.820Z") }
?? 格式化方法顯示查詢結果
> db.student.find().pretty()
{
"_id" : ObjectId("5fa27688b808fba58f5a3a41"),
"name" : "張大仙",
"age" : 19,
"sdept" : "計算機系",
"sex" : "男",
"createdatetime" : ISODate("2020-11-04T09:38:16.820Z")
}
{
"_id" : ObjectId("5fa27688b808fba58f5a3a42"),
"name" : "李太白",
"age" : 17,
"sdept" : "計算機系",
"sex" : "男",
"createdatetime" : ISODate("2020-11-04T09:38:16.820Z")
}
{
"_id" : ObjectId("5fa27688b808fba58f5a3a43"),
"name" : "黃花",
"age" : 18,
"sdept" : "英語系",
"sex" : "女",
"createdatetime" : ISODate("2020-11-04T09:38:16.820Z")
}
{
"_id" : ObjectId("5fa27688b808fba58f5a3a44"),
"name" : "菜花",
"age" : 20,
"sdept" : "數學系",
"sex" : "女",
"createdatetime" : ISODate("2020-11-04T09:38:16.820Z")
}
?? 條件過濾查詢
> db.student.find({sex:"男"})
{ "_id" : ObjectId("5fa27688b808fba58f5a3a41"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T09:38:16.820Z") }
{ "_id" : ObjectId("5fa27688b808fba58f5a3a42"), "name" : "李太白", "age" : 17, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T09:38:16.820Z") }
?? 查詢一條記錄
> db.student.findOne()
{
"_id" : ObjectId("5fa27688b808fba58f5a3a41"),
"name" : "張大仙",
"age" : 19,
"sdept" : "計算機系",
"sex" : "男",
"createdatetime" : ISODate("2020-11-04T09:38:16.820Z")
}
條件查詢
?? 多個條件同時滿足查詢 $and
db.COLLECTION_NAME.find({K1:V1,K2:V2,K3:V3...})
或者
db.COLLECTION_NAME.find({$and:[{K1:V1},{K2:V2},{K3:V3}...]})
示例:
# 查詢年齡為19,而且性別為男的學生
> db.student.find({age:19,sex:"男"})
{ "_id" : ObjectId("5fa27688b808fba58f5a3a41"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T09:38:16.820Z") }
> db.student.find({$and:[{age:19},{sex:"男"}]})
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4b"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
?? 多個條件只是滿足其中一個 $or
db.COLLECTION_NAME.find({$or:[{K1:V1},{K2:V2},{K3:V3}...]})
示例:
# 查詢年齡是19或者為英語系的學生
> db.student.find({$or:[{age:19},{sdept:"英語系"}]})
{ "_id" : ObjectId("5fa27688b808fba58f5a3a41"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T09:38:16.820Z") }
{ "_id" : ObjectId("5fa27688b808fba58f5a3a43"), "name" : "黃花", "age" : 18, "sdept" : "英語系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T09:38:16.820Z") }
?? 根據資料型別來匹配對應的結果$type
db.COLLECTION_NAME.find({KEY:{$type:數字或者資料型別}})
$tpye運算子,MongoDB中可以使用的型別如下表所示:
| 型別 | 數字 | 備注 |
|---|---|---|
| Double | 1 | |
| String | 2 | |
| Object | 3 | |
| Array | 4 | |
| Binary data | 5 | |
| Undefined | 6 | 已廢棄 |
| Object id | 7 | |
| Boolean | 8 | |
| Date | 9 | |
| Null | 10 | |
| Regular Expression | 11 | |
| JavaScript | 13 | |
| Symbol | 14 | |
| JavaScript (with scope) | 15 | |
| 32-bit integer | 16 | |
| Timestamp | 17 | |
| 64-bit integer | 18 | |
| Min key | 255 | Query with -1 |
| Max key | 127 |
示例:
# 這里先插入一條資料進行測驗
> db.student.insert({name:12,age:28,sdept:"體育系",createdatetime:new Date()})
WriteResult({ "nInserted" : 1 })
# 查詢名字型別為Double型別的學生
> db.student.find({name:{$type:1}})
{ "_id" : ObjectId("5fa36936bde0f17be2c81931"), "name" : 12, "age" : 28, "sdept" : "體育系", "createdatetime" : ISODate("2020-11-05T02:53:42.760Z") }
?? 讀取指定數量的資料記錄limit()
db.COLLECTION_NAME.find().limit(NUMBER)
NUMBER:表示記錄條數,默認值為20
示例:
# 查詢性別為男學生前2條記錄
> db.student.find({sex:"男"}).limit(1)
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4b"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
?? 查詢出來的記錄,跳過指定數量的前多少條記錄skip()
db.COLLECTION_NAME.find().skip(NUMBER)
或者
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
備注:skip(NUMBER)中的NUMBER默認值為0
示例:
# 查詢所有的性別為男的學生資訊并跳過第一條記錄
> db.student.find({sex:"男"}).skip(1)
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4c"), "name" : "李太白", "age" : 17, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
# 查詢前兩條性別為男的學生資訊,跳過第一條記錄
> db.student.find({sex:"男"}).limit(2).skip(1)
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4c"), "name" : "李太白", "age" : 17, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
?? 對查詢出來的記錄進行排序 sort()
db.COLLECTION_NAME.find().sort({key:1})
或者
db.COLLECTION_NAME.find().sort({key:-1})
備注:sort()方法可以通過引數指定排序的欄位,并使用1和-1來指定排序的方式,其中1為升序排列,而-1為降序排列,
示例:
# 查詢所有學生資訊,按照年齡升序排列
> db.student.find().sort({age:1})
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4c"), "name" : "李太白", "age" : 17, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4d"), "name" : "黃花", "age" : 18, "sdept" : "英語系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4b"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4e"), "name" : "菜花", "age" : 20, "sdept" : "數學系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa36936bde0f17be2c81931"), "name" : 12, "age" : 28, "sdept" : "體育系", "createdatetime" : ISODate("2020-11-05T02:53:42.760Z") }
# 查詢所有學生資訊,按照年齡降序排列
> db.student.find().sort({age:-1})
{ "_id" : ObjectId("5fa36936bde0f17be2c81931"), "name" : 12, "age" : 28, "sdept" : "體育系", "createdatetime" : ISODate("2020-11-05T02:53:42.760Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4e"), "name" : "菜花", "age" : 20, "sdept" : "數學系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4b"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4d"), "name" : "黃花", "age" : 18, "sdept" : "英語系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4c"), "name" : "李太白", "age" : 17, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
比較查詢
?? 大于查詢 $gt
db.COLLECTION_NAME.find({KEY:{$gt:value}})
示例:
# 查詢年齡大于17的學生
> db.student.find({age:{$gt:17}})
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4b"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4d"), "name" : "黃花", "age" : 18, "sdept" : "英語系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4e"), "name" : "菜花", "age" : 20, "sdept" : "數學系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
?? 小于查詢$lt
db.COLLECTION_NAME.find({KEY:{$lt:value}})
示例:
# 查詢年齡小于20的學生
> db.student.find({age:{$lt:20}})
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4b"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4c"), "name" : "李太白", "age" : 17, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4d"), "name" : "黃花", "age" : 18, "sdept" : "英語系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
?? 大于等于查詢 $gte
db.COLLECTION_NAME.find({KEY:{$gte:value}})
示例:
# 查詢年齡大于等于17的學生
> db.student.find({age:{$gte:17}})
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4b"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4c"), "name" : "李太白", "age" : 17, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4d"), "name" : "黃花", "age" : 18, "sdept" : "英語系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4e"), "name" : "菜花", "age" : 20, "sdept" : "數學系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
?? 小于等于查詢 $lte
db.COLLECTION_NAME.find({KEY:{$lte:value}})
示例:
# 查詢年齡小于等于20的學生
> db.student.find({age:{$lte:20}})
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4b"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4c"), "name" : "李太白", "age" : 17, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4d"), "name" : "黃花", "age" : 18, "sdept" : "英語系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4e"), "name" : "菜花", "age" : 20, "sdept" : "數學系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
?? 不等于查詢 $ne
db.COLLECTION_NAME.find({KEY:{$ne:value}})
示例:
# 查詢年齡不等于20的學生
> db.student.find({age:{$ne:20}})
db.student.find({age:{$ne:20}})
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4b"), "name" : "張大仙", "age" : 19, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4c"), "name" : "李太白", "age" : 17, "sdept" : "計算機系", "sex" : "男", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4d"), "name" : "黃花", "age" : 18, "sdept" : "英語系", "sex" : "女", "createdatetime" : ISODate("2020-11-04T12:25:49.893Z") }
綜合示例:
# 查詢年齡在17~19之間的學生
> db.student.find({age:{$gt:17,$lt:19}})
# 查詢年齡小于18,大于19的學生
> db.student.find({$or:[{age:{$lt:18}},{age:{$gt:19}}]})
聚合查詢
MongoDB中聚合(aggregate)主要用于處理資料(諸如統計平均值,求和等),并回傳計算后的資料結果,
格式如下:
db.COLLECTION_NAME.aggregate([
{
管道:{聚合操作運算式}
}
])
管道:就是把找到的資料進行過濾的操作,常用的管道符如下表
| 管道符 | 描述 |
|---|---|
$project |
修改輸入檔案的結構,可以用來重命名、增加或洗掉域 |
$match |
用于過濾資料,只輸出符合條件的檔案,$match使用MongoDB的標準查詢操作 |
$limit |
用來限制MongoDB聚合管道回傳的檔案數 |
$skip |
在聚合管道中跳過指定數量的檔案,并回傳余下的檔案 |
$group |
將集合中的檔案分組,可用于統計結果 |
$sort |
將輸入檔案排序后輸出 |
常用聚合運算式
| 運算式 | 描述 |
|---|---|
$sum |
計算總和 |
$avg |
計算平均值 |
$min |
獲取集合中所有檔案對應值的最小值 |
$max |
獲取集合中所有檔案對應值的最大值 |
?? 分組$group
db.集合名字.aggregate([
{
$group:{_id:"$欄位名",聚合函式的別名:{聚合運算式:"$欄位名"}}
}
])
示例:
# 統計學生資訊男生和女生的總年齡
> db.student.aggregate([
{
$group:{_id:"$sex",成績總和:{$sum:"$age"}}
}
])
{ "_id" : "女", "成績總和" : 38 }
{ "_id" : "男", "成績總和" : 36 }
# 統計學生資訊男生和女生各有多少人
> db.student.aggregate([
{
$group:{_id:"$sex",總人數:{$sum:1}}
}
])
{ "_id" : "女", "總人數" : 2 }
{ "_id" : "男", "總人數" : 2 }
//備注:$sum:1 等于MySQL的count(*) 統計總的記錄數
# 求學生的總數和平均年齡
> db.student.aggregate([
{
$group:{_id:null,人數:{$sum:1},平均年齡:{$avg:"$age"}}
}
])
{ "_id" : null, "人數" : 4, "平均年齡" : 18.5 }
# 求男生或者女生的總數和平均年齡
> db.student.aggregate([
{
$group:{_id:"$sex",人數:{$sum:1},平均年齡:{$avg:"$age"}}
}
])
{ "_id" : "女", "人數" : 2, "平均年齡" : 19 }
{ "_id" : "男", "人數" : 2, "平均年齡" : 18 }
# 查詢男生和女生的人數,按人數升序排列
> db.student.aggregate([
{
$group:{_id:"$sex",總人數:{$sum:1}}
},
{
$sort:{總人數:1}
}
])
# 查詢年齡小于等19,只看兩條記錄
> db.student.find({age:{$lte:19}}).limit(2) #普通方法
# 管道的方法
> db.student.aggregate([
{
$match:{age:{$lte:19}}
},
{$limit:2}
])
# 查看男生的最大年齡
> db.student.aggregate([
{
$match:{sex:"男"}
},
{
$group:{_id:"$sex", 最高分:{$max:"$age"}}
}
])
# 修改檔案結構,只含有_id,name,age
> db.student.aggregate([
{
$project:{name:1,age:1}
}
])
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4b"), "name" : "張大仙", "age" : 19 }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4c"), "name" : "李太白", "age" : 17 }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4d"), "name" : "黃花", "age" : 18 }
{ "_id" : ObjectId("5fa29dcd8b194ee77bc32b4e"), "name" : "菜花", "age" : 20 }
//備注:在$project,欄位名:1 ---->獲取該欄位的所有內容
//等于MySQL中的 select name,age from student;
常用命令總結
# 選擇切換資料庫:
use DB_NAME
# 插入資料:
db.COLLECTION_NAME.insert({bson資料})
# 查詢所有資料:
db.COLLECTION_NAME.find()
# 格式化顯示查詢的資料:
db.COLLECTION_NAME.find().pretty()
# 條件查詢資料:
db.COLLECTION_NAME.find({K1:V1,K2:V2...})
# 查詢符合條件的第一條記錄:
db.COLLECTION_NAME.findOne({K1:V1,K2:V2...})
# 查詢符合條件的前幾條記錄:
db.COLLECTION_NAME.find({K1:V1,K2:V2...}).limit(條數)
# 查詢符合條件的跳過的記錄:
db.COLLECTION_NAME.find({K1:V1,K2:V2...}).skip(條數)
# 查詢滿足多個條件中任意條件的記錄:
db.COLLECTION_NAME.find({$or:[{K1:V1},{K2:V2},{K3:V3}...]})
# 對查詢結果進行升序排序
db.COLLECTION_NAME.find().sort({kEY:1})
# 對查詢結果進行降序排序
db.COLLECTION_NAME.find().sort({kEY:-1})
# 大于查詢
db.COLLECTION_NAME.find({KEY:{$gt:value}})
# 小于查詢
db.COLLECTION_NAME.find({KEY:{$lt:value}})
# 大于等于查詢
db.COLLECTION_NAME.find({KEY:{$gte:value}})
# 小于等于查詢
db.COLLECTION_NAME.find({KEY:{$lte:value}})
# 不等于查詢
db.COLLECTION_NAME.find({KEY:{$ne:value}})
# 查詢大于小于之間的資料記錄
db.COLLECTION_NAME.find({KEY:{$gt:NUMBER,$lt:NUMBER}})
# 查詢小于多少,或者大于多少的資料
db.COLLECTION_NAME.find({$or:[{KEY:{$lt:NUMBER}},{KEY:{$gt:NUMBER}}]})
# 統計查詢
db.COLLECTION_NAME.find().count()
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/213239.html
標籤:NoSQL
上一篇:NorthWind 資料庫中,Customers表最下面的orders是個什么
下一篇:MongoDB--副本集