精、點擊上方“碼農的后花園”,選擇“星標” 公眾號
精選文章,第一時間送達
上期講解了語意分割模型的基本架構和常用資料集,這期就講解一下語意分割資料集的制作,追下去吧~
制作總體步驟:
1. 使用lableme對圖片資料進行標注,生成對應圖片的x.json檔案,
2. 執行lableme下的內置函式labelme_json_to_dataset,依次手動生成圖片對應的x_json檔案(或者使用代碼一次性處理生成),
3. 對第二步生成檔案夾中的檔案進行處理,生成語意圖片label.pngtext-align: left">4. 將語意圖片轉換為類別灰度圖圖片-最終訓練標簽檔案,
一、檔案目錄結構:
二、正式開始制作
第一步:標注軟體的安裝
1.Anaconda Prompt中創建一個環境
conda create --name=labelImg python=3.6
2.激活進入剛建立的新環境,
conda activate labelImg
3.安裝界面支持pyqt5包
pip install pyqt5 -i https://pypi.douban.com/simple/
4.下載安裝labelme
pip install labelme -i https://pypi.douban.com/simple/
5.輸入命令labelme,就可以啟動程式進行資料標注
第二步:進行標注
A.單類別標注 - 即每一張圖片上只有一個目標
【1】在命令列中輸入命令 labelme,打開標注界面,然后打開要標注的圖片所在的檔案夾進行標注
Opendir “”Test_Image“” ->Create polygons ->Save->Next Image
【2】所有圖片標注完之后,標注檔案以x.json形式檔案進行保存,制作完成后放在目錄的before檔案夾下,
用VS2017可查看Json檔案內容,包含資訊為我們標注區域內每一個像素點的資料
【3】利用labelme的自帶函式labelme_json_to_dataset手動依次將每個json檔案格式轉換為語意圖片的資料,
1.cd 到json檔案所在的地方:cmd D:Test_Image
2.查看當前labelme安裝所在的環境label并激活
3.利用labelme_json_to_dataset手動依次對每張圖片的標注檔案x.json格式依次進行處理, 生成得到x_json檔案即每張圖片的對應的語意圖片 - 區域類別標簽(這個程序需要手動對每一張圖片的x.json檔案進行處理,比較麻煩,可以寫代碼直接一次性轉換)
命令:labelme_json_to_data [ x.json ] -> labelme標注生成的json檔案名
得到每張圖片的x.json檔案對應的區域類別標簽保存在每個x_json檔案中,如下所示:
每張圖片區域類別標簽內容 x_json檔案中的內容:
注解:
img.pngtext-align: center">
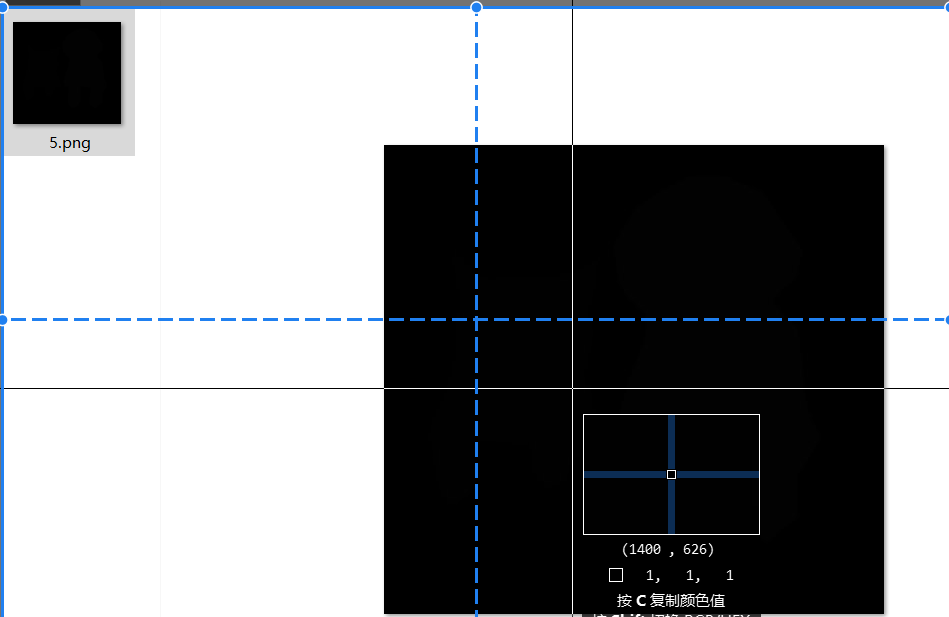
類別灰度圖圖片:
我們可以看到,貓這張圖片對應的類別灰度圖圖片所在區域的像素點的值均為 1,而背景所對應的像素點的值均為0
1. 這里我們需要首先新建一個包含全域類名稱的class_name.txt
2. 借助class_name.txt檔案,將圖片區域類別標簽檔案轉換成全域類別標簽檔案,轉換代碼:get_jpg_and_png.py
import os
from PIL import Image
import numpy as np
def main():
# 讀取原檔案夾
count = os.listdir("./before/")
for i in range(0, len(count)):
# 如果里的檔案以jpg結尾
# 則尋找它對應的png
if count[i].endswith("jpg"):
path = os.path.join("./before", count[i])
img = Image.open(path)
img.save(os.path.join("./jpg", count[i]))
# 找到對應的png
path = "./output/" + count[i].split(".")[0] + "_json/label.pngtext-align: center">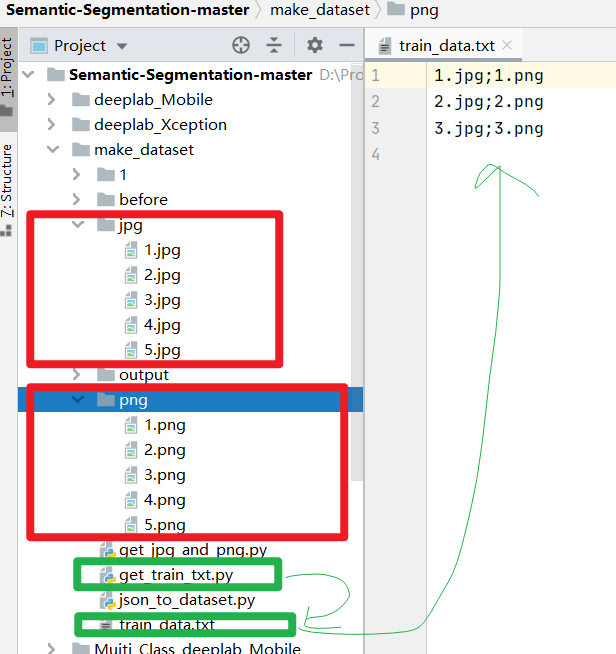
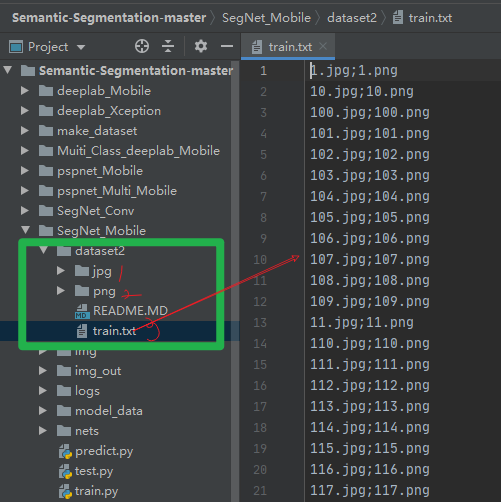
【5】最終訓練模型資料集的樣式:jpg檔案夾(原圖)+png檔案夾(全域灰度類別標簽) + train_data.txt(原圖和標簽的對應關系),放入模型當中即可訓練了,下期講解基于MobileNet的SegNet的語意分割模型,
B.多類別標注- 即一張圖片上有多個目標
標注程序和上述類似,對圖片上的多目標依次進行標注,生成的x_json檔案內容和單目標標注一樣,


新建一個包含全域類名稱的class_name.txt,然后類別灰度轉換, 利用get_jpg_and_png.py進行轉換,我們可以看到貓對應的區域像素點的值為1,對應類別1,同理狗對應區域的像素點的值為2,對應類別2,而背景區域像素點的值為0
進行類別灰度轉換之后,就可以進行模型訓練了,
最終訓練模型資料集的樣式:jpg檔案夾(原圖)+png檔案夾(全域灰度類別標簽) + train_data.txt(原圖和標簽的對應關系),放入模型當中即可訓練了,下期講解基于MobileNet的SegNet的語意分割模型,
好啦,資料標注的部分到這里就結束了,所有處理檔案代碼,回復關鍵字:專案實戰,即可獲取,
精彩推薦:
新教程之影像分割系列
影像分割系列 <-> 語意分割

更多優質內容?等你點在看

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/217277.html
標籤:其他
下一篇:python學習