HDFS架構
官網地址
HDFS采用主/從架構,HDFS群集由單個NameNode和多個DataNode組成,
簡單一致性模型
HDFS應用程式需要檔案的一寫多讀訪問模式,檔案一旦創建、寫入和關閉,除了追加和截斷外,不需要更改,支持將內容追加到檔案末尾,但不能在任意位置更新,此假設簡化了資料一致性問題,并實作了高吞吐量資料訪問,MapReduce應用程式或Web爬蟲應用程式非常適合此模型,
“移動計算比移動資料更劃算”(“Moving Computation is Cheaper than Moving Data”)
NameNode and DataNodes
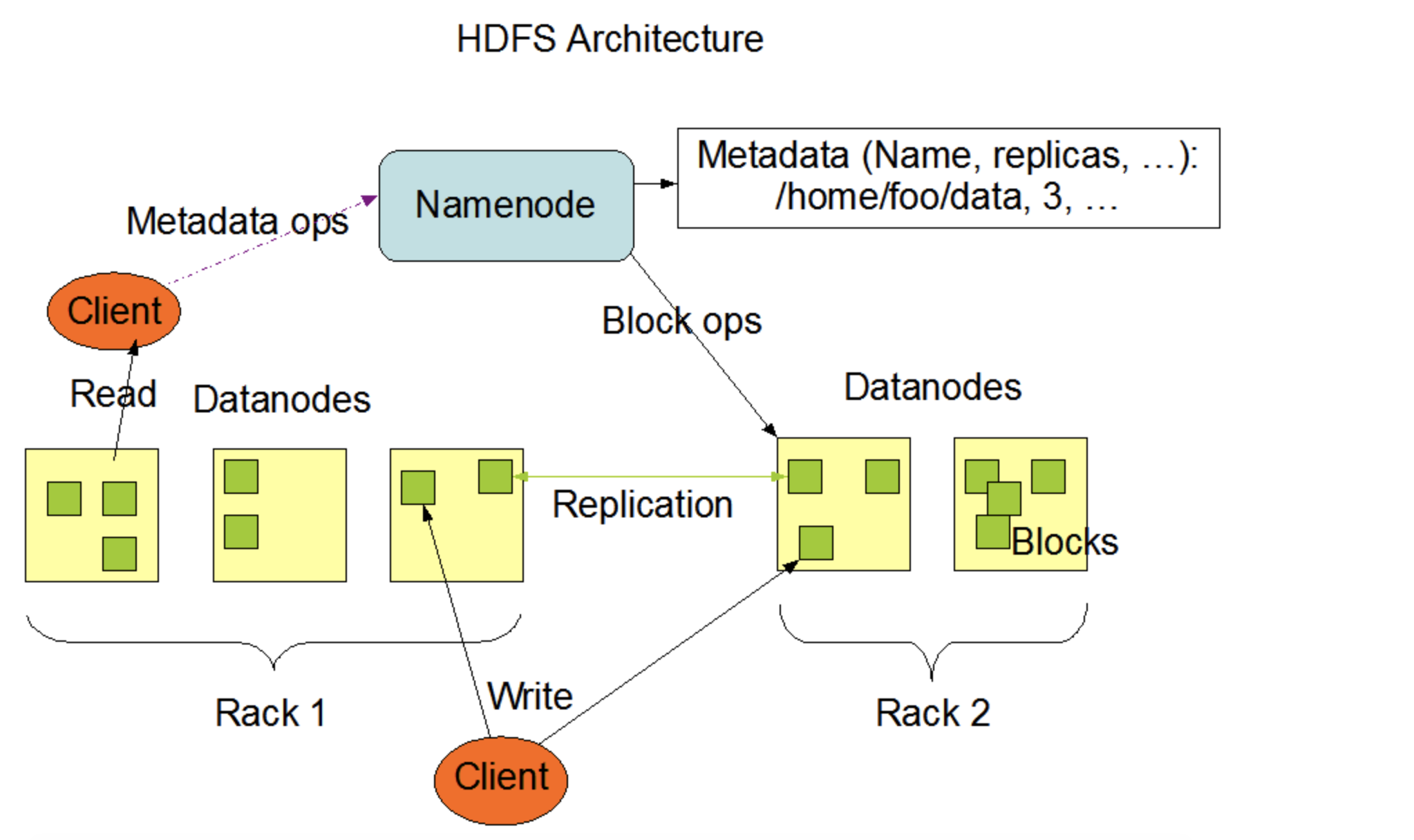
NameNode的職責:
- 控制客戶端對檔案的訪問(客戶端對檔案的訪問必須經過NN)
- NameNode執行檔案系統命名空間 (namespace) 操作,如打開、關閉和重命名檔案和目錄
- 決定了塊 (Data Block) 到DataNode的映射
DataNode的職責:
- 真正存盤資料(Block)
- DataNode負責為客戶端的讀寫請求提供服務
- DataNode還根據NameNode的指示執行塊 (Data Block) 的創建、洗掉和復制
典型的部署有一臺只運行NameNode軟體的專用機器,集群中的每臺其他機器都運行DataNode軟體的一個實體,NameNode是所有HDFS元資料的仲裁器和存盤庫,系統的設計方式是用戶資料永遠不會流經NameNode,
The File System Namespace 檔案系統命名空間
HDFS 也是目錄樹結構,根目錄是 /
HDFS支持傳統的分層檔案組織,用戶或應用程式可以創建目錄并在這些目錄中存盤檔案,檔案系統命名空間層次結構類似于大多數其他現有檔案系統;用戶可以創建和洗掉檔案、將檔案從一個目錄移動到另一個目錄或重命名檔案,HDFS支持用戶配額和訪問權限,HDFS不支持硬鏈接或軟鏈接,但是,HDFS架構并不排除實施這些功能,
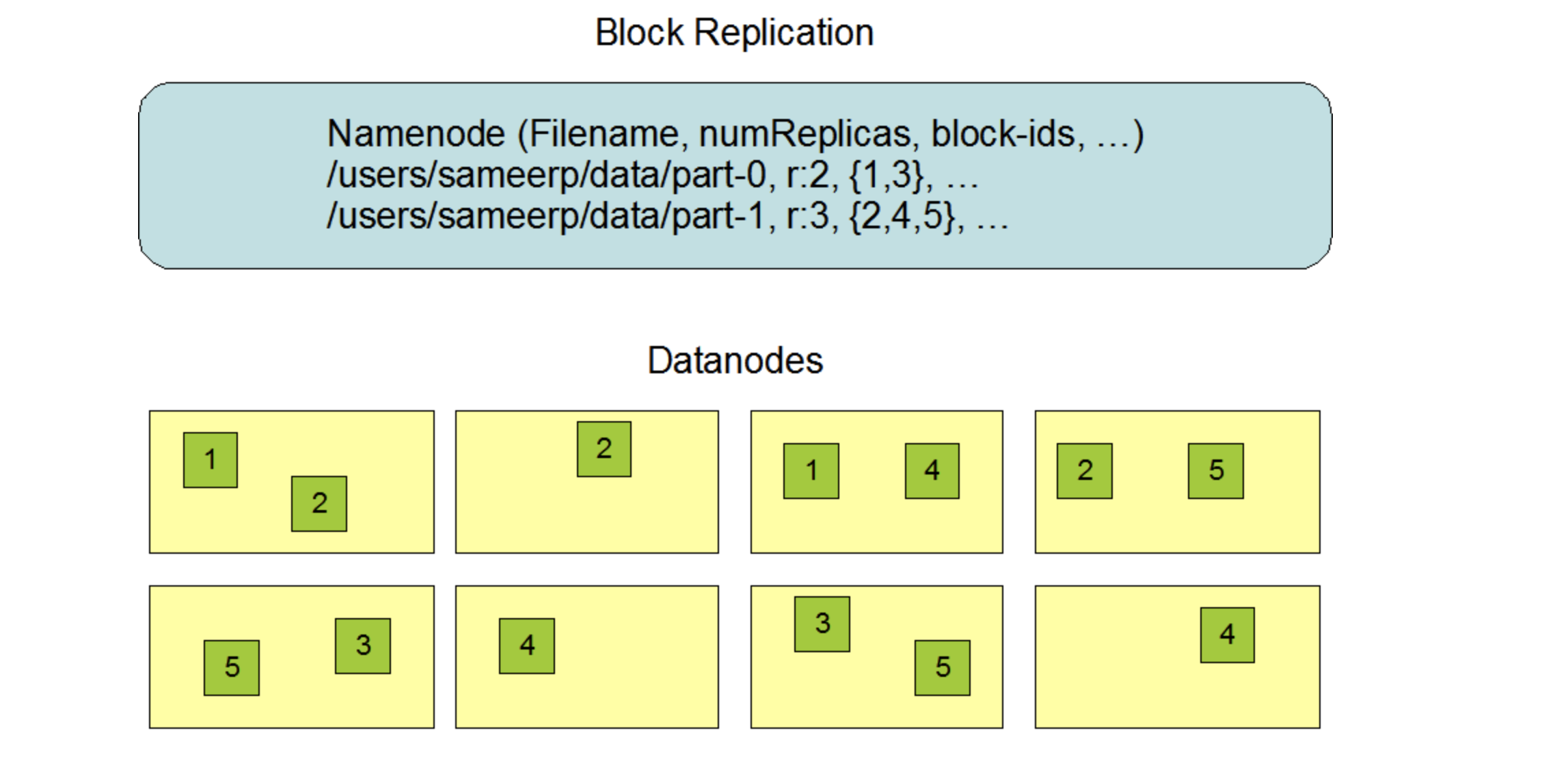
NameNode維護檔案系統命名空間,對檔案系統命名空間或其屬性的任何更改都由NameNode記錄,應用程式可以指定HDFS應該維護的檔案副本數量,檔案的副本數稱為該檔案的復制因子,此資訊由NameNode存盤,
Data Replication 資料副本
HDFS被設計用于在大型集群中跨機器可靠地存盤非常大的檔案,它以塊序列的形式存盤每個檔案,復制檔案的塊是為了容錯,塊大小和復制因子可配置每個檔案,
應用程式可以指定檔案副本的數量,復制因子可以在檔案創建時指定,以后可以更改,HDFS中的檔案是一次性寫的(除了追加和截斷),并且在任何時候都嚴格只有一個writer,
NameNode負責所有與塊復制有關的決策,它定期從集 群中的每個資料節點接收心跳和塊報告,接收到心跳信號意味著DataNode正在正常作業,Blockreport包含 DataNode上所有塊的串列,
副本放置策略
支持機架的副本放置策略的目的是提高資料可靠性、可用性和網路帶寬利用率,
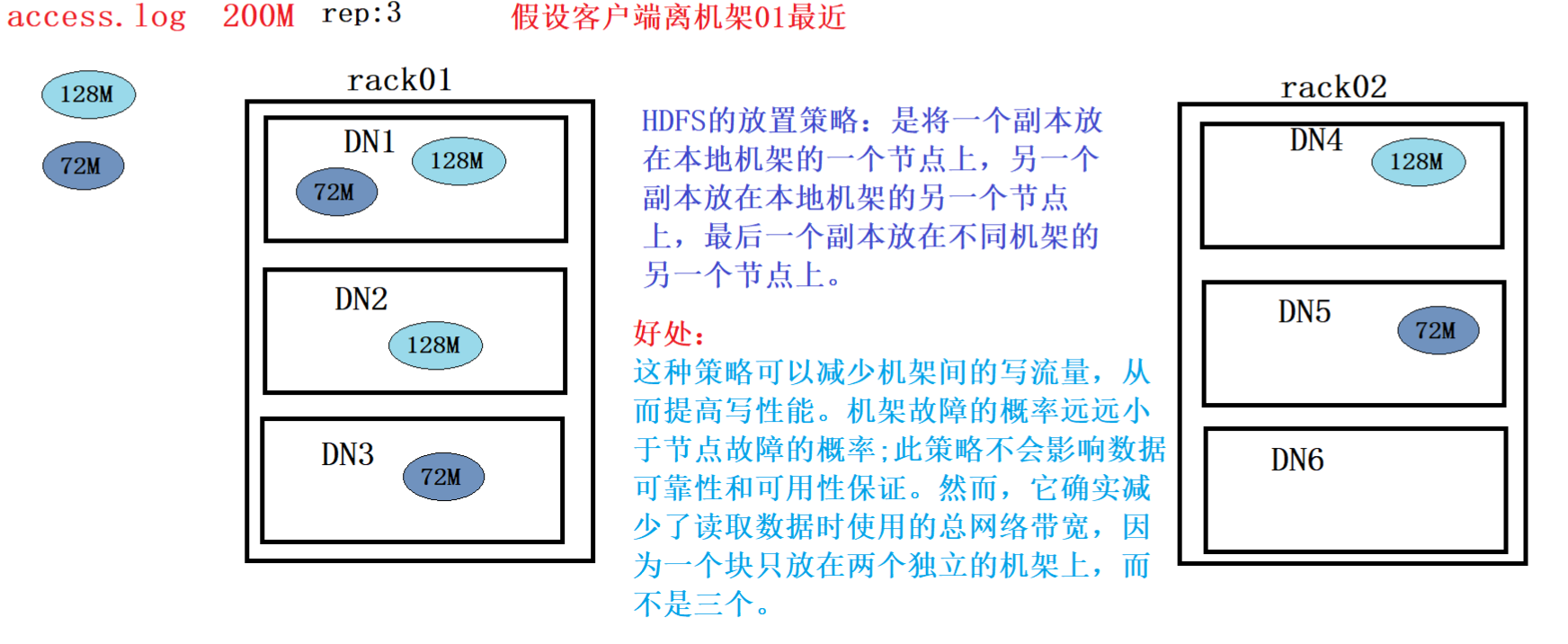
副本的選擇
原則: 就近原則
為了最小化全域帶寬消耗和讀取延遲,HDFS試圖滿足來自離讀取器最近的副本的讀取請求,如果在與reader節點相同的機架上存在一個副本,則首選該副本來滿足讀 請求,如果HDFS集群跨越多個資料中心,那么駐留在本 地資料中心的副本優于任何遠程副本,
Safemode 安全模式
在啟動時,NameNode進入一個稱為Safemode的特殊狀態,當NameNode處于Safemode狀態時,不會發生資料塊的復制,NameNode從資料節點接收心跳和 Blockreport訊息,Blockreport包含DataNode托管的資料塊串列,每個塊都有一個指定的最小副本數量,當該資料塊的最小副本數量( dfs.namenode.replication.min =1)已與 NameNode簽入時,就認為該塊是安全復制的,當安全復制的資料塊的可配置百分比( dfs.namenode.safemode.threshold-pct =0.999f) 通過NameNode(加上額外的30秒)檢查后, NameNode將退出安全模式狀態,然后,它確定仍然少于指定副本數量的資料塊串列(如果有的話),然后 NameNode將這些塊復制到其他資料節點,
Safemode模式開啟時不能有寫操作
Safemode的相關命令:
[hadoop@hadoop101 subdir0]$ hdfs dfsadmin [-safemode <enter | leave | get | wait>]
enter:#進入安全模式
leave:#退出安全模式
get:#獲取安全模式的狀態
如果NN的的存盤空間不足也會進入安全模式,此時手 動是退不出安全模式,
The Persistence of File System Metadata 檔案系統元資料的持久化
查看NN上editlog事務日志的命令:
[hadoop@hadoop101 current]$ hdfs oev -p XML -i edits_0000000000000000003-0000000000000000085 -o /home/hadoop/data/edit01.xml
查看NN上fsimage檔案的命令:
[hadoop@hadoop101 current]$ hdfs oiv -p XML -i fsimage_0000000000000000085 -o /home/hadoop/data/image01.xml
我們發現記憶體中的元資料資訊持久化成fsimage的時候,在fsimage中存盤了目錄樹、副本數、檔案和block的映射,但是沒有block和DataNode的映射,為什么???
因為block和DataNode的映射根本就沒有必要持久化, NN中元資料資訊存盤的block和DataNode的映射是通 過DataNode定期向NN發送塊報告得到了,只需要保存 在記憶體的元資料資訊中即可,
注意:HDFS中一個block的元資料資訊大約是150B,
所以HDFS不適合存盤小檔案,
checkpoint
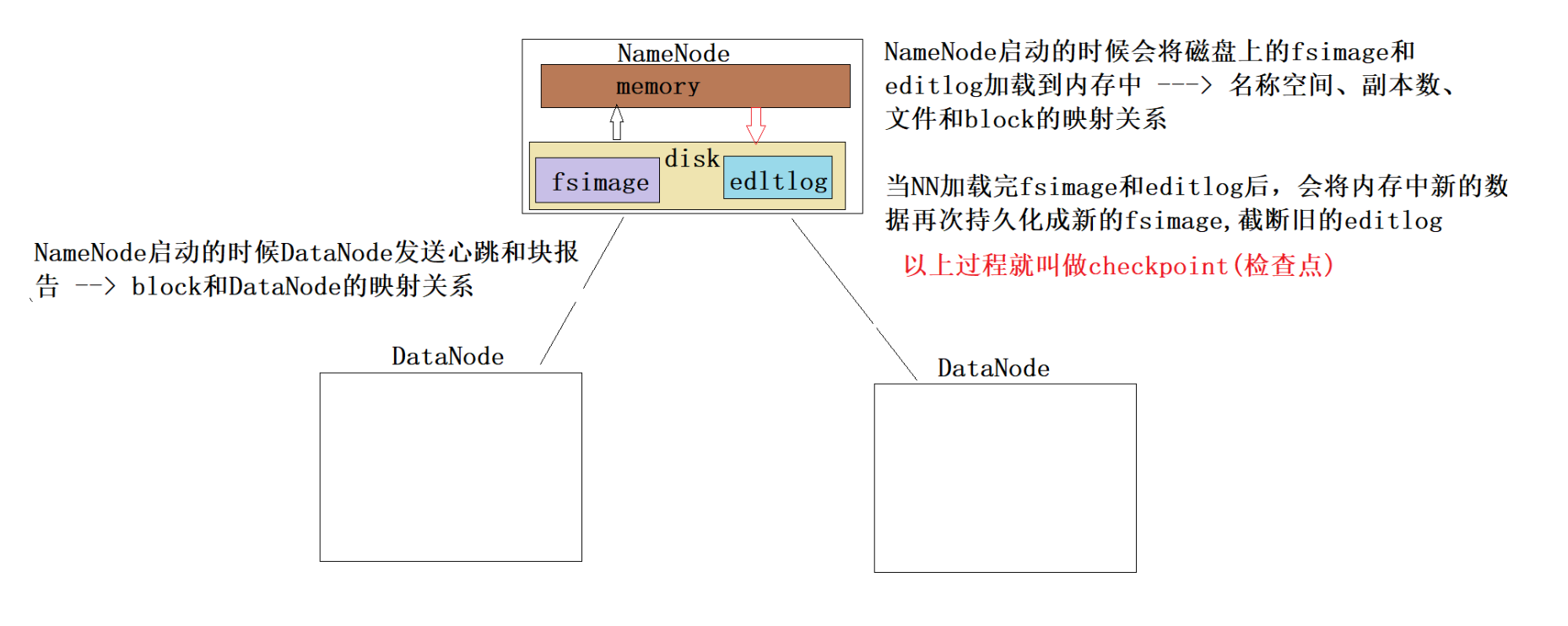
塊報告
DataNode不了解HDFS檔案,
當DataNode啟動時,它會掃描它的本地檔案系統,生成與每個本地檔案對應的所有HDFS資料塊的串列,并將該報告發送給NameNode: 這就是Blockreport,
SecondaryNameNode

配置2NN
vim hdfs-site.xml
<property>
<!--2NN位置-->
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop102:50090</value>
</property>
注意:
./hadoop-daemon.sh單啟命令,你要在哪一個節點上啟動哪一個行程,單啟命令就必須在該節點上執行,sbin/start-dfs.sh hdfs集群的群起命令
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/218804.html
標籤:大數據
上一篇:資料庫洗掉用戶資料后進行id自增,導致用戶每次進網站id一直變,求幫助
下一篇:【11月12日】Hadoop架構