| Master URL | Meaning |
|---|---|
| local | 在本地運行,只有一個作業行程,無并行計算能力, |
| local[K] | 在本地運行,有K個作業行程,通常設定K為機器的CPU核心數量, |
| local[*] | 在本地運行,作業行程數量等于機器的CPU核心數量, |
| spark://HOST:PORT | 以Standalone模式運行,這是Spark自身提供的集群運行模式,默認埠號: 7077,詳細檔案見:Spark standalone cluster, |
| mesos://HOST:PORT | 在Mesos集群上運行,Driver行程和Worker行程運行在Mesos集群上,部署模式必須使用固定值:--deploy-mode cluster,詳細檔案見:MesosClusterDispatcher. |
| yarn-client | 在Yarn集群上運行,Driver行程在本地,Executor行程在Yarn集群上,部署模式必須使用固定值:--deploy-mode client,Yarn集群地址必須在HADOOPCONFDIR or YARNCONFDIR變數里定義, |
| yarn-cluster | 在Yarn集群上運行,Driver行程在Yarn集群上,Work行程也在Yarn集群上,部署模式必須使用固定值:--deploy-mode cluster,Yarn集群地址必須在HADOOPCONFDIR or YARNCONFDIR變數里定義, |
用戶在提交任務給Spark處理時,以下兩個引數共同決定了Spark的運行方式,· –master MASTER_URL :決定了Spark任務提交給哪種集群處理,· –deploy-mode DEPLOY_MODE:決定了Driver的運行方式,可選值為Client或者Cluster,
Standalone 模式運行機制
Standalone集群有四個重要組成部分,分別是:
- Driver:是一個行程,我們撰寫的Spark應用程式就運行在Driver上,由Driver行程執行;2) Master(RM):是一個行程,主要負責資源的調度和分配,并進行集群的監控等職責;3) Worker(NM):是一個行程,一個Worker運行在集群中的一臺服務器上,主要負責兩個職責,一個是用自己的記憶體存盤RDD的某個或某些partition;另一個是啟動其他行程和執行緒(Executor),對RDD上的partition進行并行的處理和計算,4) Executor:是一個行程,一個Worker上可以運行多個Executor,Executor通過啟動多個執行緒(task)來執行對RDD的partition進行并行計算,也就是執行我們對RDD定義的例如map、flatMap、reduce等算子操作,
Standalone Client 模式
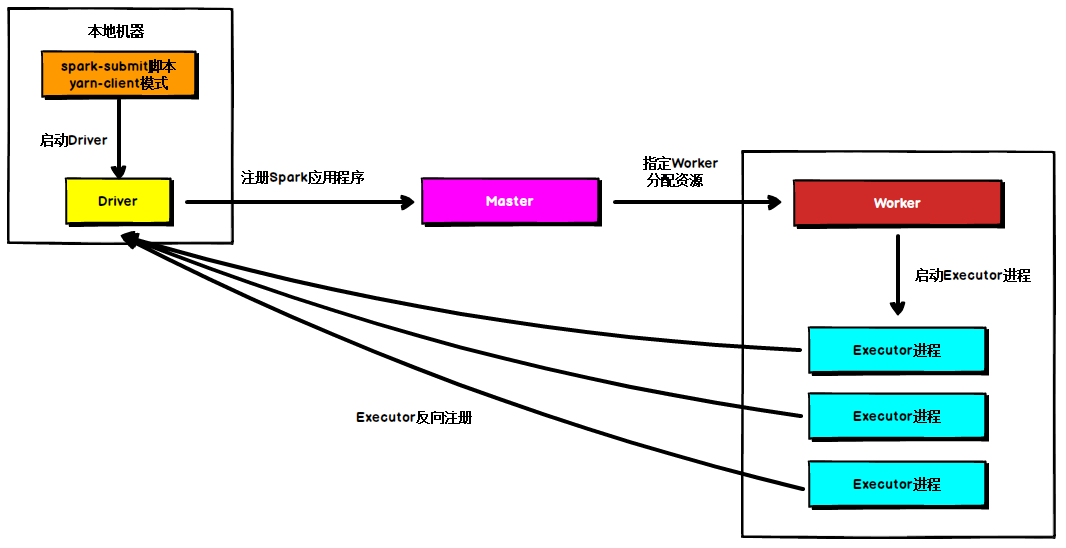
在Standalone Client模式下,Driver在任務提交的本地機器上運行,Driver啟動后向Master注冊應用程式,Master根據submit腳本的資源需求找到內部資源至少可以啟動一個Executor的所有Worker,然后在這些Worker之間分配Executor,Worker上的Executor啟動后會向Driver反向注冊,所有的Executor注冊完成后,Driver開始執行main函式,之后執行到Action算子時,開始劃分stage,每個stage生成對應的taskSet,之后將task分發到各個Executor上執行,
Standalone Cluster模式
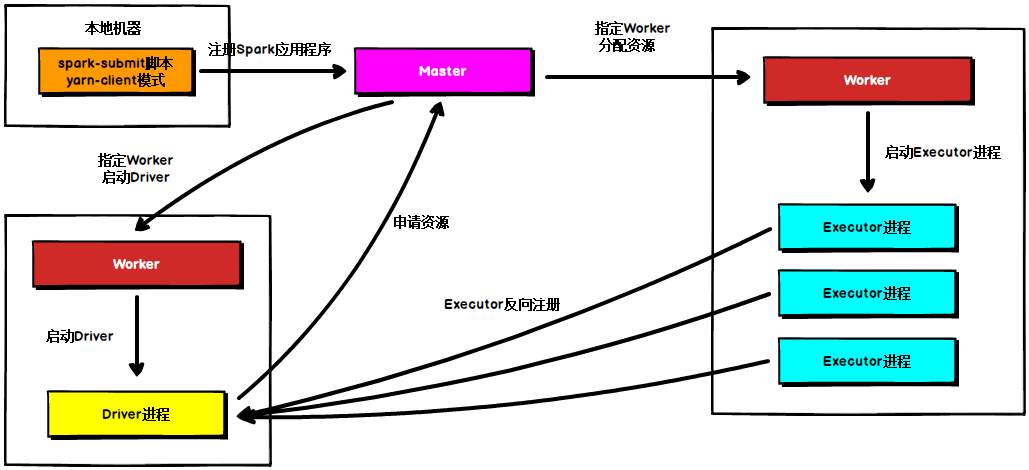
在Standalone Cluster模式下,任務提交后,Master會找到一個Worker啟動Driver行程, Driver啟動后向Master注冊應用程式,Master根據submit腳本的資源需求找到內部資源至少可以啟動一個Executor的所有Worker,然后在這些Worker之間分配Executor,Worker上的Executor啟動后會向Driver反向注冊,所有的Executor注冊完成后,Driver開始執行main函式,之后執行到Action算子時,開始劃分stage,每個stage生成對應的taskSet,之后將task分發到各個Executor上執行,注意Standalone的兩種模式下(client/Cluster),Master在接到Driver注冊Spark應用程式的請求后,會獲取其所管理的剩余資源能夠啟動一個Executor的所有Worker,然后在這些Worker之間分發Executor,此時的分發只考慮Worker上的資源是否足夠使用,直到當前應用程式所需的所有Executor都分配完畢,Executor反向注冊完畢后,Driver開始執行main程式,
Yarn 模式運行機制
Yarn Client 模式
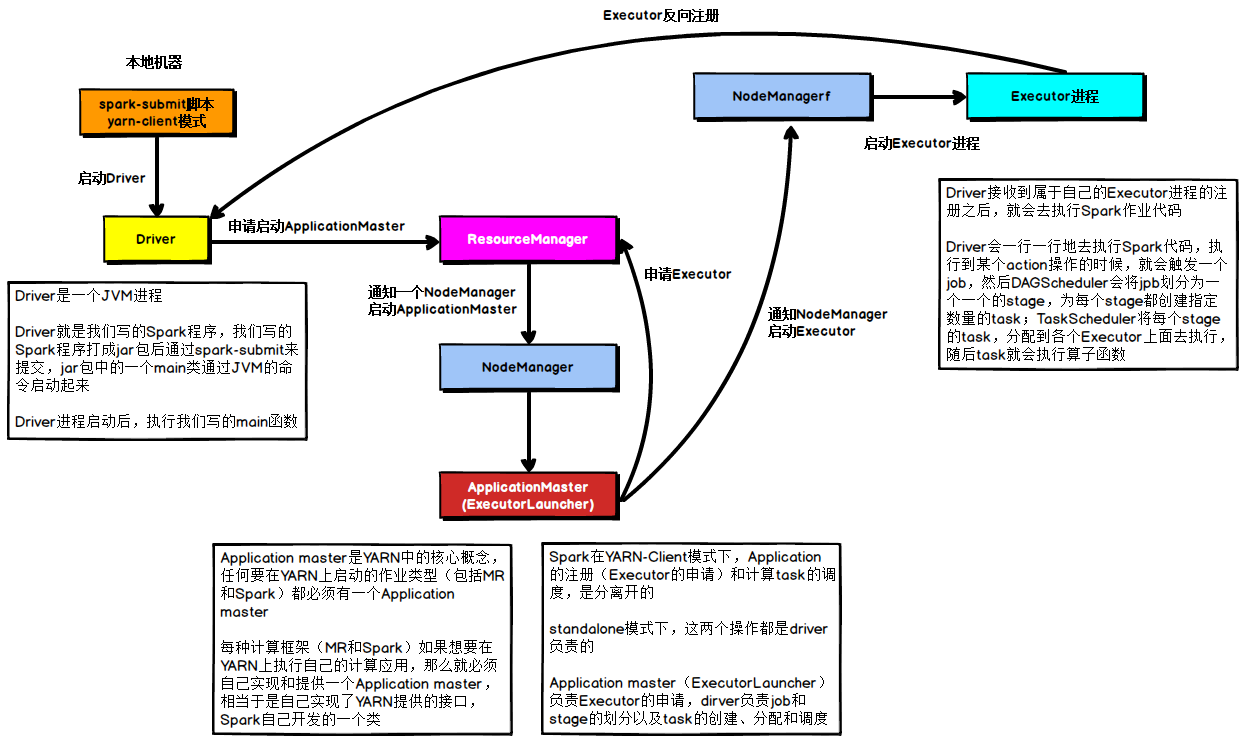
在YARN Client模式下,Driver在任務提交的本地機器上運行,Driver啟動后會和ResourceManager通訊申請啟動ApplicationMaster,隨后ResourceManager分配container,在合適的NodeManager上啟動ApplicationMaster,此時的ApplicationMaster的功能相當于一個ExecutorLaucher,只負責向ResourceManager申請Executor記憶體,
ResourceManager接到ApplicationMaster的資源申請后會分配container,然后ApplicationMaster在資源分配指定的NodeManager上啟動Executor行程,Executor行程啟動后會向Driver反向注冊,Executor全部注冊完成后Driver開始執行main函式,之后執行到Action算子時,觸發一個job,并根據寬依賴開始劃分stage,每個stage生成對應的taskSet,之后將task分發到各個Executor上執行,
Yarn Cluster 模式
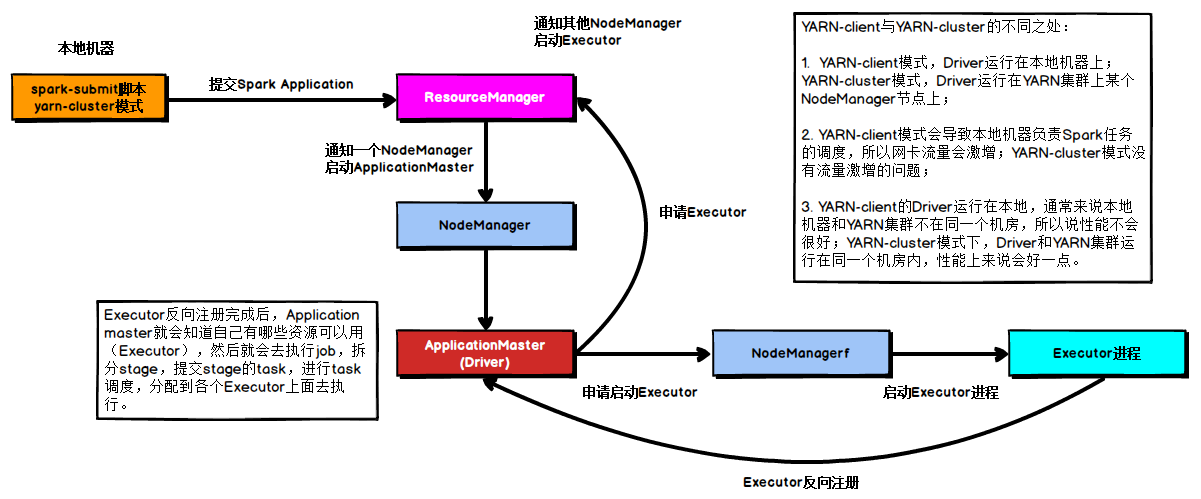
在YARN Cluster模式下,任務提交后會和ResourceManager通訊申請啟動ApplicationMaster,隨后ResourceManager分配container,在合適的NodeManager上啟動ApplicationMaster,此時的ApplicationMaster就是Driver,
Driver啟動后向ResourceManager申請Executor記憶體,ResourceManager接到ApplicationMaster的資源申請后會分配container,然后在合適的NodeManager上啟動Executor行程,Executor行程啟動后會向Driver反向注冊,Executor全部注冊完成后Driver開始執行main函式,之后執行到Action算子時,觸發一個job,并根據寬依賴開始劃分stage,每個stage生成對應的taskSet,之后將task分發到各個Executor上執行,
作者:十一喵先森
鏈接:https://juejin.im/post/5e1c414fe51d451cad4111d1
來源:掘金
著作權歸作者所有,商業轉載請聯系作者獲得授權,非商業轉載請注明出處,
我的解釋:
Standalone Cluster模式
spark集群----一個公司.騰訊
master----老板
worker----部門
driver---專案經理
execotur---執行器---程式員
application---自己撰寫的程式---客戶提要求
流程:
任務提交后,
Master(老板)會找到一個Worker(部門)啟動Driver(專案)行程
把application(客戶的需求)提交給driver(專案經理),
driver(專案經理)去spark(公司)集群中找到master(老板)要資源,需要多部門配合.
master(老板)會根據調度演算法找到可用的多個worker(部門),
Driver(專案經理)在worker(部門)中啟動executor(程式員)程式.
Driver(專案經理)開始執行main函式,之后執行到Action算子時,開始劃分stage,每個stage生成對應的taskSet,之后將task分發到各個Executor(程式員)上執行
Yarn Cluster 模式
Application---需求
ApplicationMaster(Driver)---專案經理
Executor---程式員
yarn---公司
ResourceManager---老板
NodeManager---部門
流程:
本地機器提交application(需求)到resourcemanager(老板),
resourcemanager(老板)在NodeManager(部門)上啟動ApplicationManster(專案),就是driver.
ApplicationMaster(專案經理)向ResourceManager(老板)申請Executor(程式員)記憶體,
在合適的多個NodeManager(部門)上啟動Executor(程式員)行程,
Driver(專案經理)開始執行main函式,
并根據寬依賴開始劃分stage,每個stage生成對應的taskSet,之后將task分發到各個Executor(程式)上執行,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/224906.html
標籤:其他
上一篇:Spark引數優化
下一篇:Spark內核-任務調度機制