什么是索引?
索引是一種用于快速查詢和檢索資料的資料結構,常見的索引結構有: B樹, B+樹和Hash,
索引的作用就相當于目錄的作用,打個比方: 我們在查字典的時候,如果沒有目錄,那我們就只能一頁一頁的去找我們需要查的那個字,速度很慢,如果有目錄了,我們只需要先去目錄里查找字的位置,然后直接翻到那一頁就行了,
為什么要用索引?索引的優缺點分析
索引的優點
可以大大加快 資料的檢索速度(大大減少的檢索的資料量), 這也是創建索引的最主要的原因,畢竟大部分系統的讀請求總是大于寫請求的, 另外,通過創建唯一性索引,可以保證資料庫表中每一行資料的唯一性,
索引的缺點
- 創建索引和維護索引需要耗費許多時間:當對表中的資料進行增刪改的時候,如果資料有索引,那么索引也需要動態的修改,會降低SQL執行效率,
- 占用物理存盤空間 :索引需要使用物理檔案存盤,也會耗費一定空間,
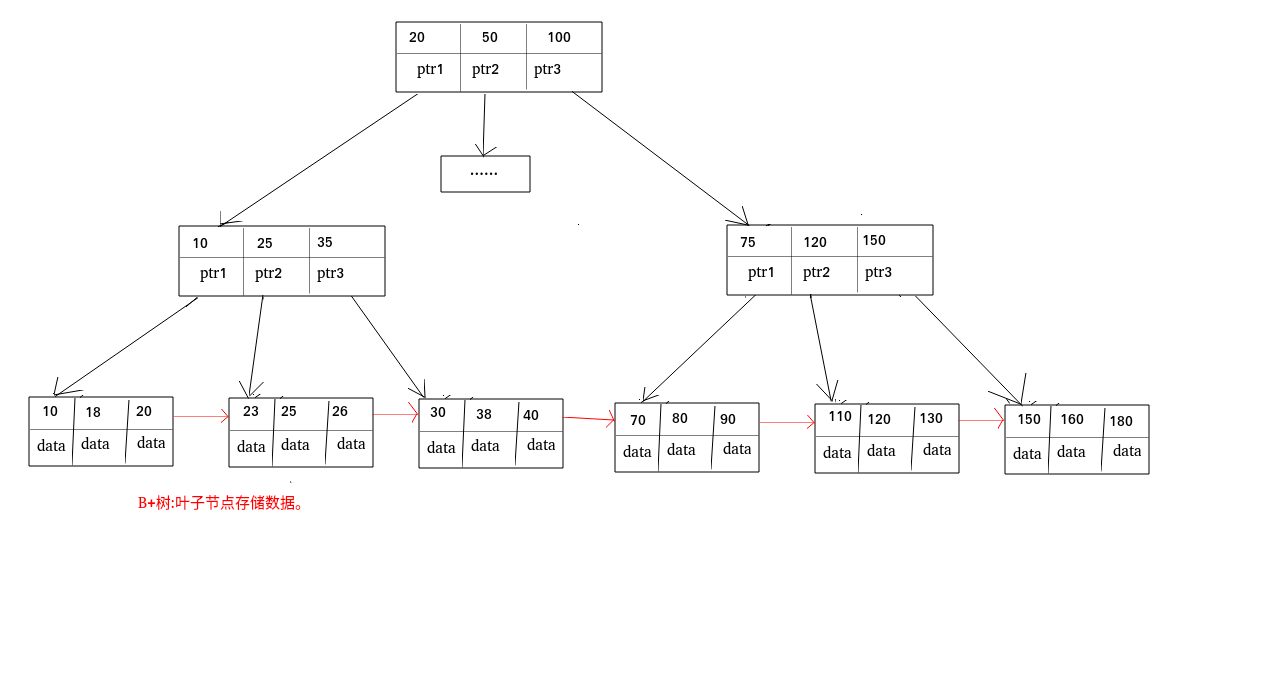
B樹和B+樹區別
- B樹的所有節點既存放 鍵(key) 也存放 資料(data);而B+樹只有葉子節點存放 key 和 data,其他內節點只存放key,
- B樹的葉子節點都是獨立的;B+樹的葉子節點有一條參考鏈指向與它相鄰的葉子節點,
- B樹的檢索的程序相當于對范圍內的每個節點的關鍵字做二分查找,可能還沒有到達葉子節點,檢索就結束了,而B+樹的檢索效率就很穩定了,任何查找都是從根節點到葉子節點的程序,葉子節點的順序檢索很明顯,
Hash索引和 B+樹索引優劣分析
Hash索引定位快
Hash索引指的就是Hash表,最大的優點就是能夠在很短的時間內,根據Hash函式定位到資料所在的位置,這是B+樹所不能比的,
Hash沖突問題
知道HashMap或HashTable的同學,相信都知道它們最大的缺點就是Hash沖突了,不過對于資料庫來說這還不算最大的缺點,
Hash索引不支持順序和范圍查詢(Hash索引不支持順序和范圍查詢是它最大的缺點,
試想一種情況:
SELECT * FROM tb1 WHERE id < 500;
B+樹是有序的,在這種范圍查詢中,優勢非常大,直接遍歷比500小的葉子節點就夠了,而Hash索引是根據hash演算法來定位的,難不成還要把 1 - 499的資料,每個都進行一次hash計算來定位嗎?這就是Hash最大的缺點了,
索引型別
主鍵索引(Primary Key)
資料表的主鍵列使用的就是主鍵索引,
一張資料表有只能有一個主鍵,并且主鍵不能為null,不能重復,
在mysql的InnoDB的表中,當沒有顯示的指定表的主鍵時,InnoDB會自動先檢查表中是否有唯一索引的欄位,如果有,則選擇該欄位為默認的主鍵,否則InnoDB將會自動創建一個6Byte的自增主鍵,
二級索引(輔助索引)
二級索引又稱為輔助索引,是因為二級索引的葉子節點存盤的資料是主鍵,也就是說,通過二級索引,可以定位主鍵的位置,
唯一索引,普通索引,前綴索引等索引屬于二級索引,
PS:不懂的同學可以暫存疑,慢慢往下看,后面會有答案的,也可以自行搜索,
- 唯一索引(Unique Key) :唯一索引也是一種約束,唯一索引的屬性列不能出現重復的資料,但是允許資料為NULL,一張表允許創建多個唯一索引,建立唯一索引的目的大部分時候都是為了該屬性列的資料的唯一性,而不是為了查詢效率,
- 普通索引(Index) :普通索引的唯一作用就是為了快速查詢資料,一張表允許創建多個普通索引,并允許資料重復和NULL,
- 前綴索引(Prefix) :前綴索引只適用于字串型別的資料,前綴索引是對文本的前幾個字符創建索引,相比普通索引建立的資料更小, 因為只取前幾個字符,
- 全文索引(Full Text) :全文索引主要是為了檢索大文本資料中的關鍵字的資訊,是目前搜索引擎資料庫使用的一種技術,Mysql5.6之前只有MYISAM引擎支持全文索引,5.6之后InnoDB也支持了全文索引,
二級索引: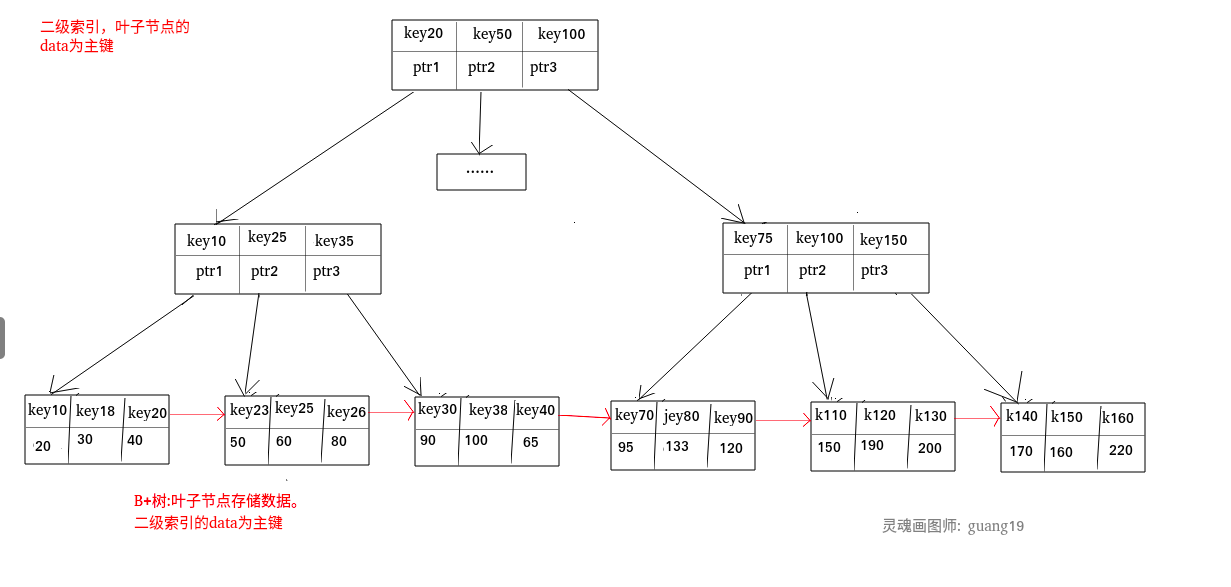
聚集索引與非聚集索引
聚集索引
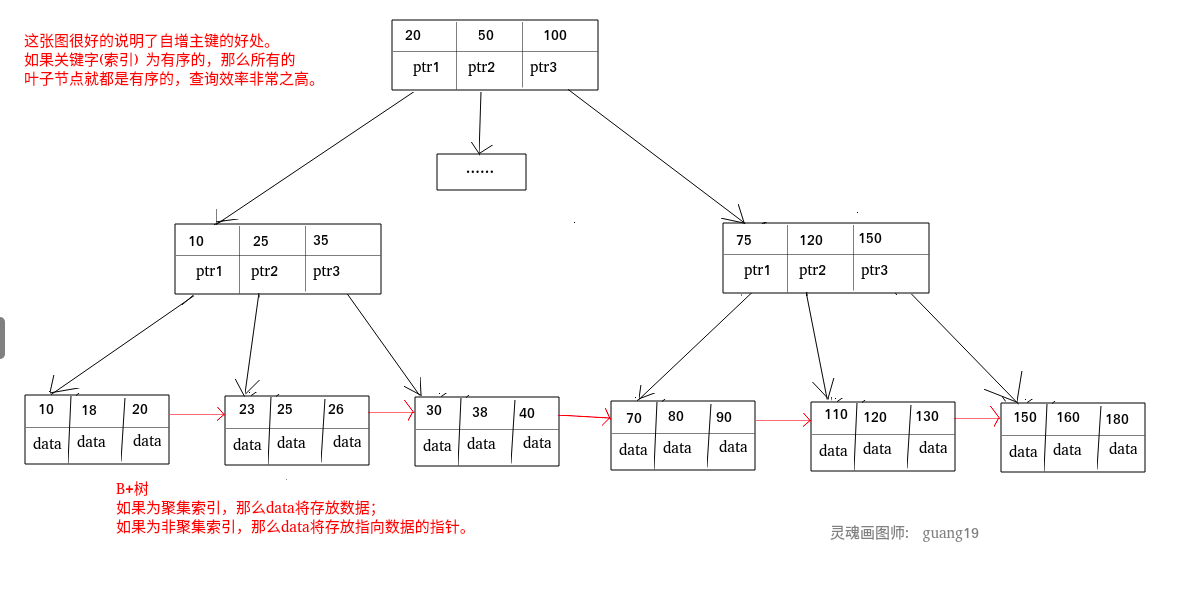
聚集索引即索引結構和資料一起存放的索引,主鍵索引屬于聚集索引,
在 Mysql 中,InnoDB引擎的表的 .ibd檔案就包含了該表的索引和資料,對于 InnoDB 引擎表來說,該表的索引(B+樹)的每個非葉子節點存盤索引,葉子節點存盤索引和索引對應的資料,
聚集索引的優點
聚集索引的查詢速度非常的快,因為整個B+樹本身就是一顆多叉平衡樹,葉子節點也都是有序的,定位到索引的節點,就相當于定位到了資料,
聚集索引的缺點
- 依賴于有序的資料 :因為B+樹是多路平衡樹,如果索引的資料不是有序的,那么就需要在插入時排序,如果資料是整型還好,否則類似于字串或UUID這種又長又難比較的資料,插入或查找的速度肯定比較慢,
- 更新代價大 : 如果對索引列的資料被修改時,那么對應的索引也將會被修改, 而且況聚集索引的葉子節點還存放著資料,修改代價肯定是較大的, 所以對于主鍵索引來說,主鍵一般都是不可被修改的,
非聚集索引
非聚集索引即索引結構和資料分開存放的索引,
二級索引屬于非聚集索引,
MYISAM引擎的表的.MYI檔案包含了表的索引, 該表的索引(B+樹)的每個葉子非葉子節點存盤索引, 葉子節點存盤索引和索引對應資料的指標,指向.MYD檔案的資料,
非聚集索引的葉子節點并不一定存放資料的指標, 因為二級索引的葉子節點就存放的是主鍵,根據主鍵再回表查資料,
非聚集索引的優點
更新代價比聚集索引要小 ,非聚集索引的更新代價就沒有聚集索引那么大了,非聚集索引的葉子節點是不存放資料的
非聚集索引的缺點
- 跟聚集索引一樣,非聚集索引也依賴于有序的資料
- 可能會二次查詢(回表) :這應該是非聚集索引最大的缺點了, 當查到索引對應的指標或主鍵后,可能還需要根據指標或主鍵再到資料檔案或表中查詢,
這是Mysql的表的檔案截圖:
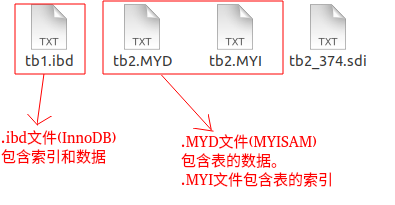
聚集索引和非聚集索引:
非聚集索引一定回表查詢嗎(覆寫索引)?
非聚集索引不一定回表查詢,
試想一種情況,用戶準備使用SQL查詢用戶名,而用戶名欄位正好建立了索引,
SELECT name FROM table WHERE username='guang19';
那么這個索引的key本身就是name,查到對應的name直接回傳就行了,無需回表查詢,
即使是MYISAM也是這樣,雖然MYISAM的主鍵索引確實需要回表, 因為它的主鍵索引的葉子節點存放的是指標,但是如果SQL查的就是主鍵呢?
SELECT id FROM table WHERE id=1;
主鍵索引本身的key就是主鍵,查到回傳就行了,這種情況就稱之為覆寫索引了,
覆寫索引
如果一個索引包含(或者說覆寫)所有需要查詢的欄位的值,我們就稱之為“覆寫索引”,我們知道在InnoDB存盤引擎中,如果不是主鍵索引,葉子節點存盤的是主鍵+列值,最侄訓是要“回表”,也就是要通過主鍵再查找一次,這樣就會比較慢覆寫索引就是把要查詢出的列和索引是對應的,不做回表操作!
覆寫索引即需要查詢的欄位正好是索引的欄位,那么直接根據該索引,就可以查到資料了, 而無需回表查詢,
如主鍵索引,如果一條SQL需要查詢主鍵,那么正好根據主鍵索引就可以查到主鍵,
再如普通索引,如果一條SQL需要查詢name,name欄位正好有索引, 那么直接根據這個索引就可以查到資料,也無需回表,
覆寫索引: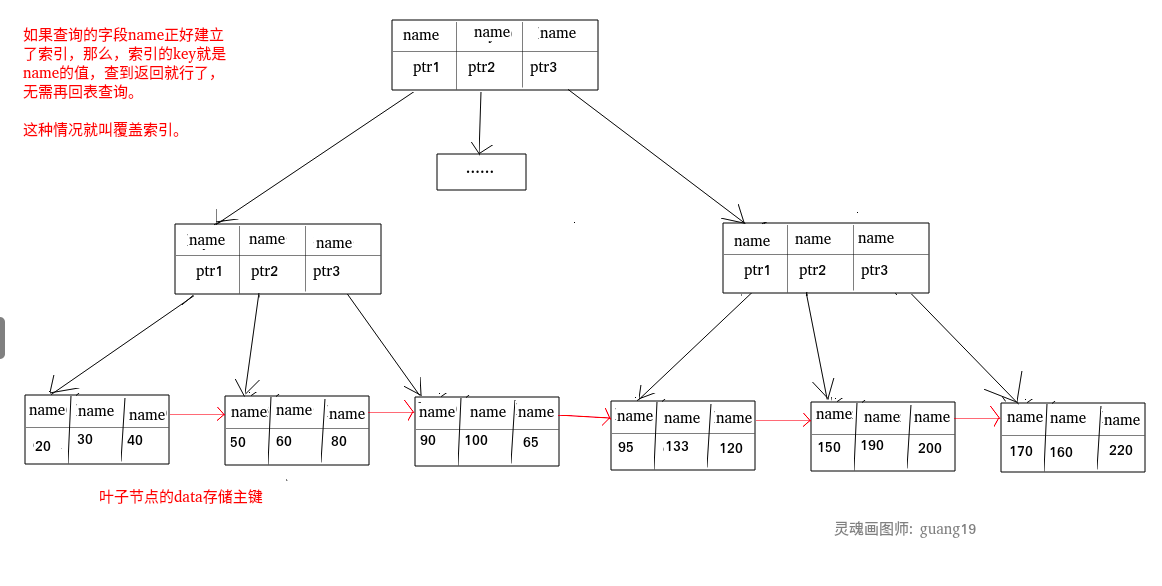
索引創建原則
單列索引
單列索引即由一列屬性組成的索引,
聯合索引(多列索引)
聯合索引即由多列屬性組成索引,
最左前綴原則
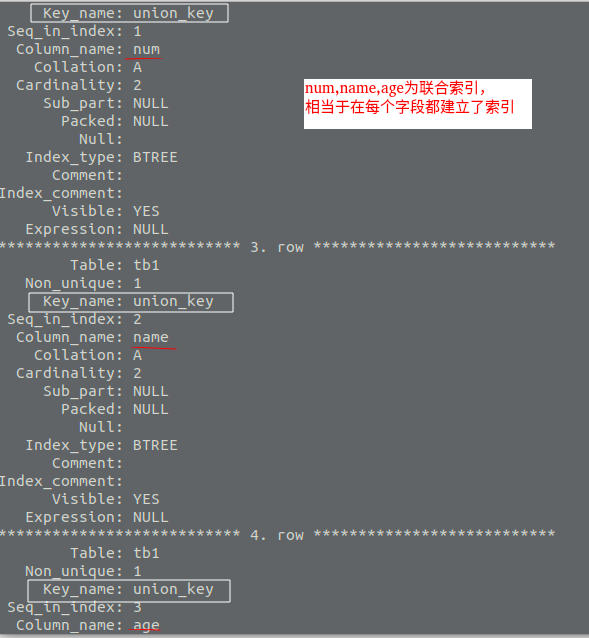
假設創建的聯合索引由三個欄位組成:
ALTER TABLE table ADD INDEX index_name (num,name,age)
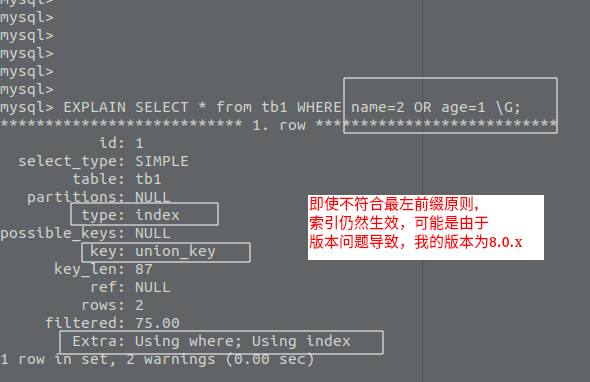
那么當查詢的條件有為:num / (num AND name) / (num AND name AND age)時,索引才生效,所以在創建聯合索引時,盡量把查詢最頻繁的那個欄位作為最左(第一個)欄位,查詢的時候也盡量以這個欄位為第一條件,
但可能由于版本原因(我的mysql版本為8.0.x),我創建的聯合索引,相當于在聯合索引的每個欄位上都創建了相同的索引:
無論是否符合最左前綴原則,每個欄位的索引都生效:
索引創建注意點
最左前綴原則
雖然我目前的Mysql版本較高,好像不遵守最左前綴原則,索引也會生效, 但是我們仍應遵守最左前綴原則,以免版本更迭帶來的麻煩,
選擇合適的欄位
1.不為NULL的欄位
索引欄位的資料應該盡量不為NULL,因為對于資料為NULL的欄位,資料庫較難優化,如果欄位頻繁被查詢,但又避免不了為NULL,建議使用0,1,true,false這樣語意較為清晰的短值或短字符作為替代,
2.被頻繁查詢的欄位
我們創建索引的欄位應該是查詢操作非常頻繁的欄位,
3.被作為條件查詢的欄位
被作為WHERE條件查詢的欄位,應該被考慮建立索引,
4.被經常頻繁用于連接的欄位
經常用于連接的欄位可能是一些外鍵列,對于外鍵列并不一定要建立外鍵,只是說該列涉及到表與表的關系,對于頻繁被連接查詢的欄位,可以考慮建立索引,提高多表連接查詢的效率,
不合適創建索引的欄位
1.被頻繁更新的欄位應該慎重建立索引
雖然索引能帶來查詢上的效率,但是維護索引的成本也是不小的, 如果一個欄位不被經常查詢,反而被經常修改,那么就更不應該在這種欄位上建立索引了,
2.不被經常查詢的欄位沒有必要建立索引
3.盡可能的考慮建立聯合索引而不是單列索引
因為索引是需要占用磁盤空間的,可以簡單理解為每個索引都對應著一顆B+樹,如果一個表的欄位過多,索引過多,那么當這個表的資料達到一個體量后,索引占用的空間也是很多的,且修改索引時,耗費的時間也是較多的,如果是聯合索引,多個欄位在一個索引上,那么將會節約很大磁盤空間,且修改資料的操作效率也會提升,
4.注意避免冗余索引
冗余索引指的是索引的功能相同,能夠命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )這兩個索引就是冗余索引,能夠命中后者的查詢肯定是能夠命中前者的 在大多數情況下,都應該盡量擴展已有的索引而不是創建新索引,
5.考慮在字串型別的欄位上使用前綴索引代替普通索引
前綴索引僅限于字串型別,較普通索引會占用更小的空間,所以可以考慮使用前綴索引帶替普通索引,
使用索引一定能提高查詢性能嗎?
大多數情況下,索引查詢都是比全表掃描要快的,但是如果資料庫的資料量不大,那么使用索引也不一定能夠帶來很大提升,
作者:Snailclimb
鏈接:資料庫索引總結 2
來源:github
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/224946.html
標籤:其他
上一篇:資料庫索引總結(二)