問題描述:
表中一共有三位“科長”,但是表中不允許“科長”的記錄單獨出現。如果“科長”的記錄單獨出現了,需要將該記錄合并到當天的第一條資料上。(將“科長”記錄的username,travelname合并到當天的第一條資料中,其它資料以第一條資料為準。)
資料庫表如下:
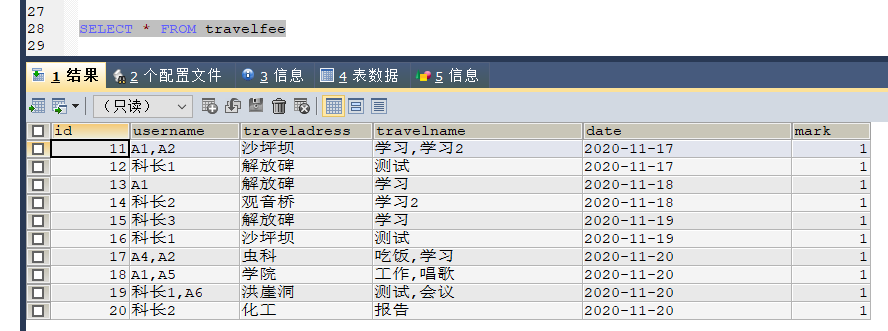
合并資料后的效果圖如下:
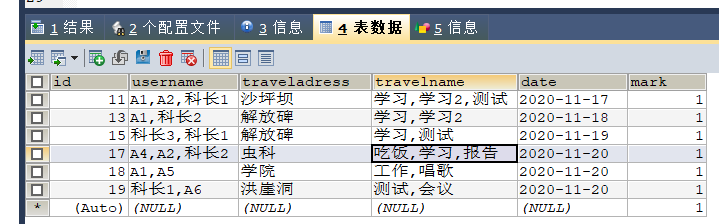
折騰了好久,希望mysql大神指點一下,謝謝!!!
uj5u.com熱心網友回復:
看不懂你的取數邏輯。從ID11 和12合并,到17和20合并,這個邏輯是怎么來的,沒看明白。
而且traveladress,是取2條件記錄中第1條的值?
ID19這條,又不是合并的。這是啥邏輯
uj5u.com熱心網友回復:
ID11和12都在同一天2020-11-17,ID12中,科長2的資料單獨出現,需要合并到當天的第一條,所以D12合并到D11;ID17~20,也是同一天2020-11-20,ID20中,科長2資料單獨出現,需要合并到當天的第一條資料,即D17uj5u.com熱心網友回復:
ID11和12都在同一天2020-11-17,ID12中,科長2的資料單獨出現,需要合并到當天的第一條,所以D12合并到D11;ID17~20,也是同一天2020-11-20,ID20中,科長2資料單獨出現,需要合并到當天的第一條資料,即D17
uj5u.com熱心網友回復:
ID11和12都在同一天2020-11-17,ID12中,科長2的資料單獨出現,需要合并到當天的第一條,所以D12合并到D11;ID17~20,也是同一天2020-11-20,ID20中,科長2資料單獨出現,需要合并到當天的第一條資料,即D17
這個邏輯我我感覺有問題。
如果 含有'科長'的記錄,不能單獨存在,那么,17-20這4條記錄(同一個日期范圍)
就應該是17+19合并,18+20合并,才對。
這18和20又是獨立的,又不發生合并,這邏輯不知道咋理解
uj5u.com熱心網友回復:
最后這句話,糾正一下。18和19的記錄又是獨立存在,不發生合并,那19不是帶有科長的值嗎?uj5u.com熱心網友回復:
好家伙,你這是要把原始資料給合并了,還是通過查詢或者SQL轉換來顯示合并的效果uj5u.com熱心網友回復:
意思是說,同一天內,科長不能單獨一個人出現在記錄,可以跟其他人一起出現。19中,科長跟其他人一起出現是允許的,20中單獨出現是不允許的。
打個比方,某單位要求科長不能一個人出差,必須要兩個人或者以上,而組員可以一個人出差。但現實中科長一個人出差了,那么需要把科長一個人出差的記錄合并到當天的其它出差記錄中,這里選擇合并到當天的第一條記錄。
uj5u.com熱心網友回復:
通過查詢或者SQL轉換來顯示合并的效果。
uj5u.com熱心網友回復:
第一次合并要求是根據date和traveladress,把username和travelname資料合并。這個用group_concat()和group by 很容易實作。現在需要在此基礎上把“科長”單獨出現的記錄合并到當天的第一條資料中,為了方便處理,我把第一次合并的內容弄成了一個視圖。
uj5u.com熱心網友回復:
測驗結果:
if object_id('tempdb.dbo.#travelfee')is not null drop table #travelfee
--建表
CREATE TABLE #travelfee
(
id int,
username varchar(10),
traveladress varchar(20),
travelname varchar(20),
mDate varchar(10),
mark int default(1)
)
--測驗資料
insert into #travelfee
select 11,'A1,A2','沙坪壩','學習,學習2','2020-11-17',1 union all
select 12,'科長1','解放碑','測驗','2020-11-17',1 union all
select 13,'A1','解放碑','學習','2020-11-18',1 union all
select 14,'科長2','觀音橋','學習2','2020-11-18',1 union all
select 15,'科長3','解放碑','學習','2020-11-19',1 union all
select 16,'科長1','沙坪壩','測驗','2020-11-19',1 union all
select 17,'A4,A2','蟲科','吃飯,學習','2020-11-20',1 union all
select 18,'A1,A5','學院','作業,唱歌','2020-11-20',1 union all
select 19,'科長1,A6','洪崖洞','測驗,會議','2020-11-20',1 union all
select 20,'科長2','化工','報告','2020-11-20',1
--查詢
;with cta as (
select *,row_number() over (partition by mDate order by getdate()) as isFlag from #travelfee
),
ctb as (
select
min(case when b.isFlag =1 then b.id else 0 end) as Id
,stuff( (select ',' +username from #travelfee where mDate = a.mDate for xml path('')),1,1,'') as username
,a.traveladress
,a.travelname
,a.mDate
from #travelfee as a
left join cta as b on a.id = b.id
group by a.traveladress,a.travelname,a.mDate
)
select * from ctb where Id !=0 order by Id
--洗掉
drop table #travelfee
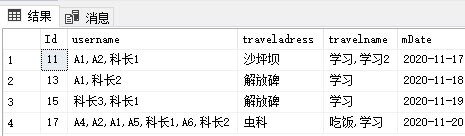
最大的問題,是在同一日期,存在多條科長的記錄時,要怎么處理。也就是它的匹配邏輯是怎樣的
uj5u.com熱心網友回復:
謝謝您,這個效果我也實作過:
select id,group_concat(username) username,traveladress,group_concat(travelname) travelname,date,mark
from travelfee
group by date

但這不是最終的效果,ID 11~16處理沒問題,而17~20有問題。
17~20中,17~19的記錄是允許的,即組員可以單獨或者組隊出差、科長可以跟組員出差,但是20只有科長一個人出差,是不允許的。
那么需要將20的資料插入到17~19中任意一條即可,為了方便處理,選擇插入第一條
uj5u.com熱心網友回復:
沒事。共同研究一下。
是這樣的,從業務場景,要先考慮,在同一個日期中,會存在2次,或2次以上科長時,要怎么處理這些記錄。
如果說,只會一個日期出現2次,那只需要做下回圈遍歷,把每1次的記錄,去和它靠前(上條 非科長的記錄)做下分組標識。
最后再來處理按組合并。
這是一個思路上的問題,而且還要考慮,如果科長出現多次時,最后一次的記錄向上沒有匹配的記錄,要怎么處理它的分組。
uj5u.com熱心網友回復:
我補充說明一下。mark的值為1,表示全天出差。那么對于三位科長來說,同一日期中,同一個科長的資料只會出現一次。即會有四種情況:一,科長單獨出差(這個不允許,需要合并);二,科長跟科長組隊出差(允許);三,科長跟組員組隊出差(允許);四,多個科長跟組員出差(允許)。
同時,我看了一下資料,發現不可能出現一個日期只有科長出差的記錄,即一定會有組員出差。所以我的思路是:把這張表的資料根據date分成兩組,一組是科長單獨出現,一組科長不單獨出現。然后把【單獨出現的科長記錄】插入到【科長不單獨出現的第一條】。我把兩組的資料可以分別查出來,但是一合并再分組,就不行了。
我也經常解決一些比較難的SQL陳述句,但這一次的合并要求,折騰了好久,解決不了。涉及到我的知識盲區了
uj5u.com熱心網友回復:
為了方便測驗:CREATE TABLE `travelfee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) DEFAULT NULL,
`traveladress` varchar(50) DEFAULT NULL,
`travelname` varchar(50) DEFAULT NULL,
`date` date DEFAULT NULL,
`mark` int(11) DEFAULT '1',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=utf8
insert into `travelfee`(`id`,`username`,`traveladress`,`travelname`,`date`,`mark`) values
(11,'A1,A2','沙坪壩','學習,學習2','2020-11-17',1),
(12,'科長1','解放碑','測驗','2020-11-17',1),
(13,'A1','解放碑','學習','2020-11-18',1),
(14,'科長2','觀音橋','學習2','2020-11-18',1),
(15,'科長3','解放碑','學習','2020-11-19',1),
(16,'科長1','沙坪壩','測驗','2020-11-19',1),
(17,'A4,A2','蟲科','吃飯,學習','2020-11-20',1),
(18,'A1,A5','學院','作業,唱歌','2020-11-20',1),
(19,'科長1,A6','洪崖洞','測驗,會議','2020-11-20',1),
(20,'科長2','化工','報告','2020-11-20',1);
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/225207.html
標籤:疑難問題