1. 一條查詢的SQL陳述句是如何執行的?
拋出問題:我們平時操作MySQL資料庫,大多數都是使用Navicat連接遠程服務器上的資料庫,撰寫一條陳述句,例如:select name from user where id=1 ,然后就會回傳結果,但是有沒有思考過,當我們的工具或者程式連接到資料庫之后,實際上發生了什么事情?它的內部是如何作業的?
其實一條查詢的陳述句的執行流程分為以下幾步:
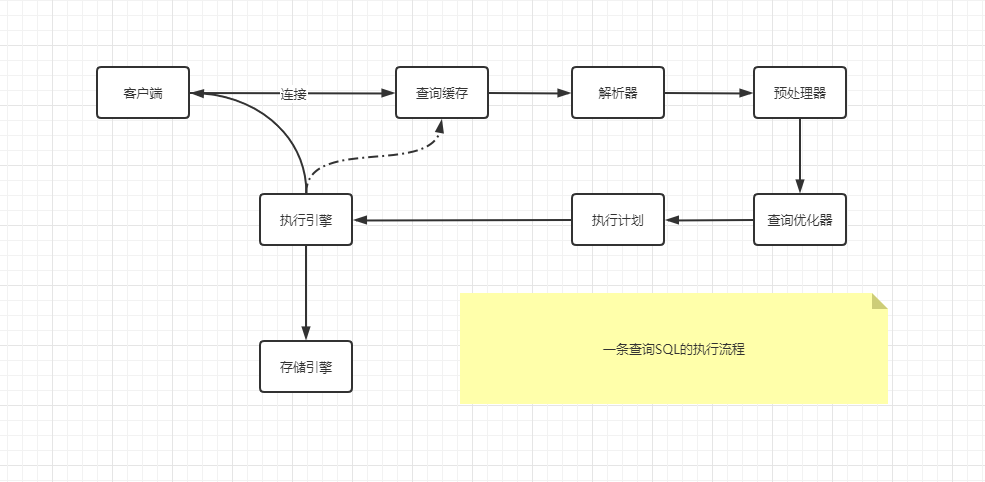
待我一步步解釋:
1.1、查詢快取
①、MySQL資料庫自帶的,
②、存盤形式是以KV對進行存盤的,例如Reids,為了就是加快資料的查詢效能,較少服務器的處理時間,
③、默認關閉的(不推薦使用),查詢快取是否開啟陳述句: show variables like 'query_cache%';
原因:例如:user表里面有100萬資料,但是沒索引,其中查詢陳述句為:select * from user where name='Kelly' ,第一次用時為5秒,那么執行同樣的陳述句第二次會變快嘛?答案:不會,因為查詢快取時默認關閉的,可以使用陳述句:show variables like 'query_cache%';進行 查看,開啟后查詢會變快嘛,結果會變快,
為什么不推薦使用查詢快取:主要還是自帶的查詢快取太過于雞肋,使用的場景有限,
a、第一個是它要求 SQL 陳述句必須一模一樣,中間多一個空格,字母大小寫不同都被認為是不同的的 SQL,
b、表里面任何一條資料發生變化的時候,這張表所有快取都會失效,所以對于有大量資料更新的應用,也不適合,
c、專門做專事,快取還是交給 ORM 框架(比如 MyBatis 默認開啟了一級快取),或者獨立的快取服務,比如 Redis 來處理更合適,
④、8.0版本查詢快取被移除掉了,
1.2、決議器
決議器:主要做的事情是對陳述句基于 SQL 語法進行詞法和語法分析和語意的決議,例如:select * from user where name='Kelly' 可以執行,但是如果是:slect * form user whree name='Kelly',就會提示你SQL陳述句報錯,這就是決議器做的事情,
①、語法分析:select name from user where id=88 ,這條sql陳述句就會被拆分為8個符號,每個符合什么型別,從哪里開始到哪里結束等,例如資料結構中的:鏈表,
②、語意分析:語法分析會對 SQL 做一些語法檢查,比如單引號有沒有閉合,然后根據 MySQL 定義的語法規則,根據 SQL 陳述句生成一個資料結構,這個資料結構我們把它叫做決議樹(select_lex),
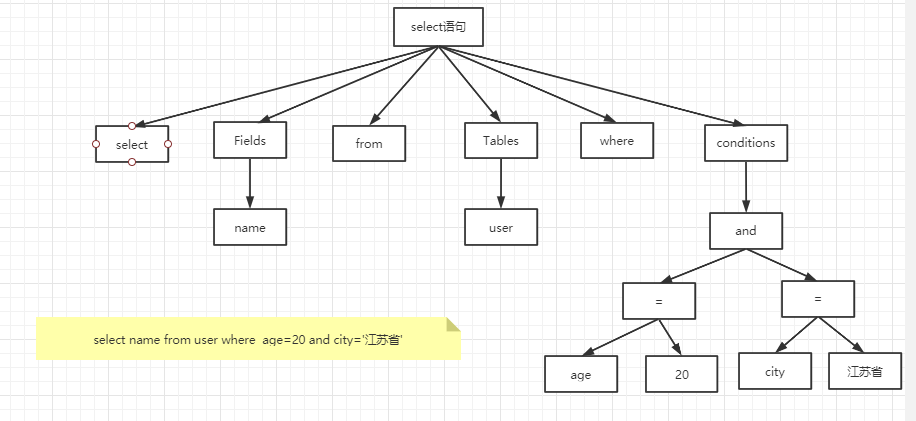
任何資料庫的中間件,比如 Mycat,Sharding-JDBC(用到了 Druid Parser),都必須要有詞法和語法分析功能,在市面上也有很多的開源的詞法決議的工具(比如 LEX,Yacc),
1.3、前處理器
①、解釋器是分析語法有沒有錯誤,但是它無法知道資料庫中有沒有資料表和欄位,例如:select name from user1 where id=88,這條陳述句語法沒問題,但是執行依然報錯,這就是前處理器做的活,因為資料庫中沒有user1這張表,只有user表,決議 SQL 的環節里面 就會用到這個前處理器,
②、它會檢查生成的決議樹,解決決議器無法決議的語意,比如,它會檢查表和列名是否存在,檢查名字和別名,保證沒有歧義,
③、預處理之后得到一個新的決議樹,
1.4、查詢優化器
①、什么是優化器?
得到決議樹之后,是不是執行 SQL 陳述句了呢?
這里我們有一個問題,一條 SQL 陳述句是不是只有一種執行方式?
或者說資料庫最終 執行的 SQL 是不是就是我們發送的 SQL?
這個答案是否定的,一條 SQL 陳述句是可以有很多種執行方式的,最侄訓傳相同的結果,他們是等價的,但是如果有這么多種執行方式,這些執行方式怎么得到的?最終選擇哪一種去執行?根據什么判斷標準去選擇?
這個就是 MySQL 的查詢優化器的模塊(Optimizer),
查詢優化器的目的就是根據決議樹生成不同的執行計劃(Execution Plan),然后選擇一種最優的執行計劃,MySQL 里面使用的是基于開銷(cost)的優化器,那種執行計劃開銷最小,就用哪種,
可以使用這個命令查看查詢的開銷:show status like 'Last_query_cost';
②、優化器可以做什么?
MySQL 的優化器能處理哪些優化型別呢?
舉兩個簡單的例子:
a、當我們對多張表進行關聯查詢的時候,以哪個表的資料作為基準表,
b、有多個索引可以使用的時候,選擇哪個索引,
實際上,對于每一種資料庫來說,優化器的模塊都是必不可少的,他們通過復雜的演算法實作盡可能優化查詢效率的目標,
但是優化器也不是萬能的,并不是再垃圾的 SQL 陳述句都能自動優化,也不是每次都能選擇到最優的執行計劃,大家在撰寫 SQL 陳述句的時候還是要注意,
③、優化器是怎么得到執行計劃的?
首先我們要啟用優化器的追蹤(默認是關閉的):SHOW VARIABLES LIKE 'optimizer_trace'; set optimizer_trace='enabled=on';
注意開啟這開關是會消耗性能的,因為它要把優化分析的結果寫到表里面,所以不要輕易開啟,或者查看完之后關閉它(改成 off),
接著我們執行一個 SQL 陳述句,優化器會生成執行計劃:select u.id from user u,user_config uc where u.id=uc.id
這個時候優化器分析的程序已經記錄到系統表里面了,我們可以查詢:
select * from information_schema.optimizer_trace\G
它是一個 JSON 型別的資料,主要分成三部分,準備階段、優化階段和執行階段,

expanded_query 是優化后的 SQL 陳述句,
considered_execution_plans 里面列出了所有的執行計劃,
分析完記得關掉它:set optimizer_trace="enabled=off"; SHOW VARIABLES LIKE 'optimizer_trace';
1.5、執行計劃
優化器完之后,得到一個什么東西呢?
優化器最侄訓把決議樹變成一個查詢執行計劃,查詢執行計劃是一個資料結構,
當然,這個執行計劃是不是一定是最優的執行計劃呢?
不一定,因為 MySQL 也有可能覆寫不到所有的執行計劃,
我們怎么查看 MySQL 的執行計劃呢?比如多張表關聯查詢,先查詢哪張表?在執行查詢的時候可能用到哪些索引,實際上用到了什么索引?
MySQL 提供了一個執行計劃的工具,我們在 SQL 陳述句前面加上 EXPLAIN,就可以看到執行計劃的資訊,
例如:EXPLAIN select name from user where id=1;
1.6、存盤引擎
得到執行計劃以后,SQL 陳述句是不是終于可以執行了?
問題又來了:
a、從邏輯的角度來說,我們的資料是放在哪里的,或者說放在一個什么結構里面?
b、執行計劃在哪里執行?是誰去執行?
①、 存盤引擎基本介紹
我們先回答第一個問題:在關系型資料庫里面,資料是放在什么結構里面的?
(放在表 Table 里面的)
我們可以把這個表理解成 Excel 電子表格的形式,所以我們的表在存盤資料的同時,還要組織資料的存盤結構,這個存盤結構就是由我們的存盤引擎決定的,所以我們也可以把存盤引擎叫做表型別,
在 MySQL 里面,支持多種存盤引擎,他們是可以替換的,所以叫做插件式的存盤引擎,為什么要搞這么多存盤引擎呢?一種還不夠用嗎?
這個問題先留著,
②、查看存盤引擎
比如我們資料庫里面已經存在的表,我們怎么查看它們的存盤引擎呢?
show table status from `plaso1`;
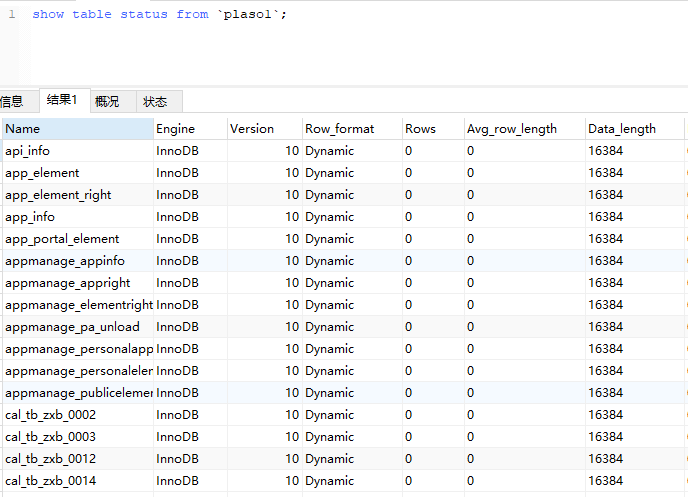
或者通過 DDL 建表陳述句來查看,
在 MySQL 里面,我們創建的每一張表都可以指定它的存盤引擎,而不是一個資料庫只能使用一個存盤引擎,存盤引擎的使用是以表為單位的,而且,創建表之后還可以修改存盤引擎,我們說一張表使用的存盤引擎決定我們存盤資料的結構,那在服務器上它們是 怎么存盤的呢?我們先要找到資料庫存放資料的路徑:
show variables like 'datadir';
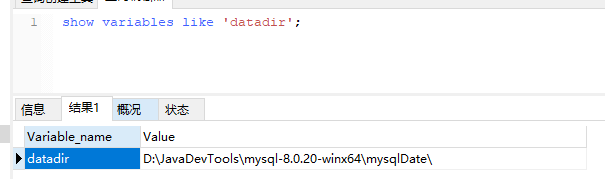
默認情況下,每個資料庫有一個自己檔案夾,以 plaso1 資料庫為例
任何一個存盤引擎都有一個 frm 檔案,這個是表結構定義檔案,

不同的存盤引擎存放資料的方式不一樣,產生的檔案也不一樣,innodb 是 1 個,memory 沒有,myisam 是兩個,這些存盤引擎的差別在哪呢?
③、存盤引擎比較
MyISAM 和 InnoDB 是我們用得最多的兩個存盤引擎,在 MySQL 5.5 版本之前,默認的存盤引擎是 MyISAM,它是 MySQL 自帶的,我們創建表的時候不指定存盤引擎,它就會使用 MyISAM 作為存盤引擎,
MyISAM 的前身是 ISAM(Indexed Sequential Access Method:利用索引,順序存取資料的方法),5.5 版本之后默認的存盤引擎改成了 InnoDB,它是第三方公司為 MySQL 開發的,
為什么要改呢?最主要的原因還是 InnoDB 支持事務,支持行級別的鎖,對于業務一致性要求高的場景來說更適合,
那么除了這兩個我們最熟悉的存盤引擎,資料庫還支持其他哪些常用的存盤引擎呢?
我們可以用這個命令查看資料庫對存盤引擎的支持情況
show engines ;
其中有存盤引擎的描述和對事務、XA 協議和 Savepoints 的支持,
XA 協議用來實作分布式事務(分為本地資源管理器,事務管理器),
Savepoints 用來實作子事務(嵌套事務),創建了一個 Savepoints 之后,事務就可以回滾到這個點,不會影響到創建 Savepoints 之前的操作,
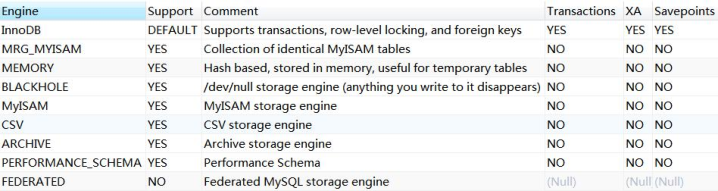
這些資料庫支持的存盤引擎,分別有什么特性呢?
MyISAM ( 3 個檔案)
應用范圍比較小,表級鎖定限制了讀/寫的性能,因此在 Web 和資料倉庫配置中,它通常用于只讀或以讀為主的作業,
特點:
支持表級別的鎖(插入和更新會鎖表),不支持事務,
擁有較高的插入(insert)和查詢(select)速度,
存盤了表的行數(count 速度更快),
(怎么快速向資料庫插入 100 萬條資料?我們有一種先用 MyISAM 插入資料,然后修改存盤引擎為 InnoDB 的操作,)
適合:只讀之類的資料分析的專案,
InnoDB (2 個檔案)
mysql 5.7 中的默認存盤引擎,InnoDB 是一個事務安全(與 ACID 兼容)的 MySQL存盤引擎,它具有提交、回滾和崩潰恢復功能來保護用戶資料,InnoDB 行級鎖(不升級為更粗粒度的鎖)和 Oracle 風格的一致非鎖讀提高了多用戶并發性和性能,InnoDB 將用戶 資料存盤在聚集索引中,以減少基于主鍵的常見查詢的 I/O,為了保持資料完整性,InnoDB 還支持外鍵參考完整性約束,
特點:
支持事務,支持外鍵,因此資料的完整性、一致性更高,
支持行級別的鎖和表級別的鎖,
支持讀寫并發,寫不阻塞讀(MVCC),
特殊的索引存放方式,可以減少 IO,提升查詢效率,
適合:經常更新的表,存在并發讀寫或者有事務處理的業務系統,
Memory (1 個檔案)
將所有資料存盤在 RAM 中,以便在需要快速查找非關鍵資料的環境中快速訪問,這個引擎以前被稱為堆引擎,其使用案例正在減少;InnoDB 及其緩沖池記憶體區域提供了一種通用、持久的方法來將大部分或所有資料保存在記憶體中,而 ndbcluster 為大型分布式數 據集提供了快速的鍵值查找,
特點:
把資料放在記憶體里面,讀寫的速度很快,但是資料庫重啟或者崩潰,資料會全部消失,只適合做臨時表,將表中的資料存盤到記憶體中,
CSV (3 個檔案)
它的表實際上是帶有逗號分隔值的文本檔案,csv表允許以csv格式匯入或轉儲資料,以便與讀寫相同格式的腳本和應用程式交換資料,因為 csv 表沒有索引,所以通常在正常操作期間將資料保存在 innodb 表中,并且只在匯入或匯出階段使用 csv 表,
特點:
不允許空行,不支持索引,格式通用,可以直接編輯,適合在不同資料庫之間匯入匯出
Archive (2 個檔案)
這些緊湊的未索引的表用于存盤和檢索大量很少參考的歷史、存檔或安全審計資訊,
特點:
不支持索引,不支持 update delete,
這是 MySQL 里面常見的一些存盤引擎,我們看到了,不同的存盤引擎提供的特性都不一樣,它們有不同的存盤機制、索引方式、鎖定水平等功能,
我們在不同的業務場景中對資料操作的要求不同,就可以選擇不同的存盤引擎來滿 足我們的需求,這個就是 MySQL 支持這么多存盤引擎的原因,
④、 如何選擇存盤引擎?
如果對資料一致性要求比較高,需要事務支持,可以選擇 InnoDB,
如果資料查詢多更新少,對查詢性能要求比較高,可以選擇 MyISAM,
如果需要一個用于查詢的臨時表,可以選擇 Memory,
如果所有的存盤引擎都不能滿足你的需求,并且技術能力足夠,可以根據官網內部手冊用 C 語言開發一個存盤引擎:
. 1.7、 執行引擎(y Query n Execution Engine ),回傳結果
OK,存盤引擎分析完了,它是我們存盤資料的形式,繼續第二個問題,是誰使用執行計劃去操作存盤引擎呢?
這就是我們的執行引擎,它利用存盤引擎提供的相應的 API 來完成操作,
為什么我們修改了表的存盤引擎,操作方式不需要做任何改變?因為不同功能的存盤引擎實作的 API 是相同的,最后把資料回傳給客戶端,即使沒有結果也要回傳,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/225992.html
標籤:MySQL