在業界廣泛流傳著一句話:資料和特征決定了機器學習的上限,而模型和演算法只是逼近這個上限而已,
由此可見,資料和特征是多么的重要,而在資料大多數場景下,資料已經就緒,不同人對于同樣的資料處理得到的特征卻千差萬別,最終得到的建模效果也是高低立現,從資料到特征這就要從特征工程說起了...
0. 特征工程
首先介紹下,特征工程是什么:利用資料領域的相關知識來創建能夠使機器學習演算法達到最佳性能的特征的程序[1.wiki],特征工程是一個較大領域,它通常包括特征構建、特征提取和特征選擇這三個子模塊,重要性排序:特征構建>特征提取>特征選擇,先來介紹幾個術語:
- 特征構建:從原始資料中構建出特征,有時也稱作特征預處理,包括缺失值處理、例外值處理、無量綱化(標準化/歸一化)、啞編碼等,
- 特征提取:將原特征轉換為一組具有明顯物理意義或統計意義或核的新特征,
- 特征選擇:從特征集合中挑選一組最具統計意義的特征子集,
1. 特征降維
WHAT:將高維空間的特征通過刪級訓變換轉為低維空間特征 WHY:降低時間/空間復雜度、降低提取特征開銷、降噪、提升魯棒性、增強可解釋性、便于可視化; HOW:主要有兩種方式,即特征選擇和特征提取,1.1 特征選擇(子集篩選):
特征選擇方法主要分為三種:
- Filter:過濾式;按權重排序,不涉及到學習器,排序規則一般有方差法、相關系數法、互資訊法、卡方檢驗法、缺失值比例法(注意受范圍影響的方法需先歸一化)[2.zhihu],
- 方差法:計算各個特征的方差,然后根據閾值,選擇方差大于閾值的特征,可使用sklearn.feature_selection庫的VarianceThreshold類來實作,
- 缺失值比例法:計算各個特征的缺失值比例,將缺失值比例較大的特征過濾掉,
- 相關系數法:計算特征與輸出值的相關系數以及相關系數的 P值(常見的有:皮爾森相關系數用于數值特征的線性檢驗,秩相關系數用于類別特征的單調性檢驗),
- 互資訊法:計算定性特征與輸出值的相關性(運用了資訊熵理論),決策樹學習中的資訊增益等價于訓練資料集中類與特征的互資訊,
-
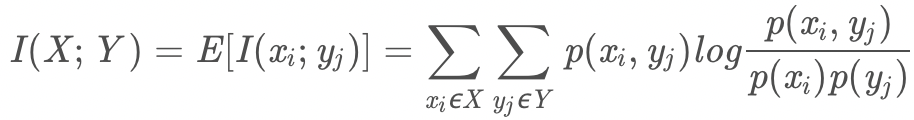
- 卡方檢驗法:對于每個特征與輸出值,先假設獨立,再觀察實際值與理論值的偏差來確定假設的正確性,即是否相關,
- Embedded:嵌入式;確定模型程序中自動完成重要特征挑選,基于懲罰項如嶺回歸(L2正則)、LASSO(L1正則),基于樹模型如GBDT、決策樹[3.cnblog],
- Wrapper:封裝式;用學習器的性能評判不同特征子集的效果,特征子集生成方式:完全搜索(前向&后向)、啟發式搜索、隨機搜索[3.cnblog],
1.2 特征提取(投影or轉換):
- 線性方法[4.csdn]:
- PCA:主成分分析;理論:通過正交變換將原始的 n 維資料集變換到一個新的被稱做主成分的資料集中,變換后的結果中第一個主成分具有最大的方差值;
- 特點:無監督,盡量少維度保留盡量多原始資訊(均方誤差最小),期望投影維度上方差最大,不考慮類別,去相關性,零均值化,喪失可解釋性
- ICA:獨立成分分析;將原特征轉化為相互獨立的分量的線性組合;PCA一般作為ICA的預處理步驟[5.zhihu],
- LDA:線性判別分析,有監督,盡可能容易被區分(高內聚、低耦合)[6.cnblog],
- SVD:奇異值分解,可用于PCA、推薦、潛在語意索引LSI,可并行,可解釋性不強
- 非線性方法:
- LLE:區域線性嵌入,非線性降維(基于圖),保持原有流行結構
- LE:拉普拉斯特征映射,非線性(基于圖),相互有聯系的點盡可能靠近
- t-SNE:t分布隨機臨近嵌入,將歐幾里得距離轉為條件概率表達點與點之間的相似度[7.datakit],
- AE:自動編碼器
- 聚類
特征降維方法對比先介紹到這里,更多內容后續繼續分解~
轉載請注明出處:資料挖掘篇——特征工程之特征降維(https://www.cnblogs.com/webary/p/12498886.html)
參考鏈接:
1.wiki:https://en.wikipedia.org/wiki/Feature_engineering
2.zhihu:https://www.zhihu.com/question/28641663
3.cnblog:https://www.cnblogs.com/pinard/p/9032759.html
4.csdn:https://blog.csdn.net/yujianmin1990/article/details/48223001
5.zhihu:https://www.zhihu.com/search?type=content&q=PCA%20ICA
6.cnblog:https://www.cnblogs.com/LeftNotEasy/archive/2011/01/08/lda-and-pca-machine-learning.html
7.datakit:http://www.datakit.cn/blog/2017/02/05/t_sne_full.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/22760.html
標籤:大數據
上一篇:sql server 陳述句問題