第5章 DataStreamAPI
參考書籍
Stream Processing with Apache Flinkhttps://www.oreilly.com/library/view/stream-processing-with/9781491974285/
《基于Apache Flink的流處理》https://book.douban.com/subject/34912177/
注:本文主要是針對《基于Apache Flink的流處理》的筆記
1-8章筆記下載地址
本章介紹了Flink的DataStream API的基礎知識,我們將展示常用的Flink流應用程式的結構和組件,討論Flink的型別系統和支持的資料型別,并介紹資料轉換(data transformation)和磁區轉換(partitioning transformation),讀完這一章,你將知道如何實作一個具有基本功能的流處理應用程式,
5.1 Hello,Flink!
首先舉一個簡單的例子作為開始
/** 定義一個case class作為傳感器讀取資料的資料型別*/
/** Case class to hold the SensorReading data. */
case class SensorReading(id: String, timestamp: Long, temperature: Double)
/** 放主函式的object*/
/** Object that defines the DataStream program in the main() method */
object AverageSensorReadings {
/** main() defines and executes the DataStream program */
def main(args: Array[String]) {
// 設定流式執行環境
// set up the streaming execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 在應用中使用事件時間
// use event time for the application
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 配置水位線
// configure watermark interval
env.getConfig.setAutoWatermarkInterval(1000L)
// 從流式資料源中創建DataStream[SensorReading]物件
// ingest sensor stream
val sensorData: DataStream[SensorReading] = env
// 添加傳感器Source
// SensorSource generates random temperature readings
.addSource(new SensorSource)
// 設定時間戳和水位線
// assign timestamps and watermarks which are required for event time
.assignTimestampsAndWatermarks(new SensorTimeAssigner)
val avgTemp: DataStream[SensorReading] = sensorData
// 將溫度從華氏溫度轉換為攝氏溫度
// convert Fahrenheit to Celsius using an inlined map function
.map( r =>
SensorReading(r.id, r.timestamp, (r.temperature - 32) * (5.0 / 9.0)) )
// 根據傳感器id來分組資料
// organize stream by sensorId
.keyBy(_.id)
// 按照1秒的滾動視窗分組
// group readings in 1 second windows
.timeWindow(Time.seconds(1))
// 使用用戶自定義函式來計算平均溫度
// compute average temperature using a user-defined function
.apply(new TemperatureAverager)
// 列印到控制臺
// print result stream to standard out
avgTemp.print()
// 開始執行應用
// execute application
env.execute("Compute average sensor temperature")
}
}
構建一個典型的Flink流式程式需要以下幾步
- 設定執行環境
- 從資料源中讀取一潭訓多條流
- 通過一系列流式轉換來實作應用邏輯
- 選擇性地將結果輸出到一個或多個資料匯中
- 執行程式
5.1.1 設定執行環境
Flink應用程式需要做的第一件事是設定它的執行環境,執行環境確定程式是在本地機器上運行還是在集群上運行,在DataStream API中,應用程式的執行環境由StreamExecutionEnvironment表示,
有兩種設定執行環境的方式
-
呼叫靜態
getExecutionEnvironment()方法來檢索執行環境,此方法回傳本地或遠程環境,具體取決于呼叫該方法的背景關系,如果通過連接到遠程集群從提交客戶端呼叫該方法,則回傳遠程執行環境,否則,它回傳一個本地環境, -
也可以通過
createxxx方法來顯式設定執行環境,具體代碼如下// 創建一個本地的流式執行環境 val localEnv = StreamExecutionEnvironment.createLocalEnvironment() // 創建一個遠程的流式執行環境 val remoteEnv = StreamExecutionEnvironment.createRemoteEnvironment( "host", // JobManager的主機名 1234, // JobManager的埠號 "path/to/jarFile.jar" // 需要傳輸到JobManager的JAR包 )
執行環境還提供了很多配置選項,比如
- 通過
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)指定當前應用使用事件時間語意 - 設定并行度
- 啟動容錯等
5.1.2 讀取輸入流
StreamExecutionEnvironment提供了一系列創建流式資料源的方法,用來將資料流讀取到應用中,這些資料流的來源可以是訊息佇列或者檔案,也可以動態生成,
在實體中,讀取代碼如下
// 從流式資料源中創建DataStream[SensorReading]物件
// ingest sensor stream
val sensorData: DataStream[SensorReading] = env
// 添加傳感器Source
// SensorSource generates random temperature readings
.addSource(new SensorSource)
// 設定時間戳和水位線
// assign timestamps and watermarks which are required for event time
.assignTimestampsAndWatermarks(new SensorTimeAssigner)
5.1.3 應用轉換(Apply Transformation)
當獲取到了DataStream,就可以對其應用轉換(we can apply a transformation on it),轉換的型別有很多:
- 有些轉換可以生成新的
DataStream,并且可能是不同型別的(eg.DataStream[Int] => DataStream[String]) - 有些轉換不修改
DataStream中的條目,而是通過磁區或分組對其進行重新組織, - 應用程式的邏輯是通過一系列轉換定義的,
在實體中,轉換代碼如下
val avgTemp: DataStream[SensorReading] = sensorData
// 將溫度從華氏溫度轉換為攝氏溫度
// convert Fahrenheit to Celsius using an inlined map function
.map( r =>
SensorReading(r.id, r.timestamp, (r.temperature - 32) * (5.0 / 9.0)) )
// 根據傳感器id來分組資料
// organize stream by sensorId
.keyBy(_.id)
// 按照1秒的滾動視窗分組
// group readings in 1 second windows
.timeWindow(Time.seconds(1))
// 使用用戶自定義函式來計算平均溫度
// compute average temperature using a user-defined function
.apply(new TemperatureAverager)
5.1.4 輸出結果
流應用程式通常將其結果發送到一些外部系統(external system),如Apache Kafka、檔案系統或資料庫,Flink提供了一組流式資料匯,可用于將資料寫入不同的系統,也可以實作自己的流式資料匯,還有一些應用程式不發出結果,而是通過Flink的可查詢狀態(queryable state)功能在內部保存結果,
在我們的示例中,會將DataStream[SensorReading]中的記錄作為結果輸出,每個記錄包含傳感器在5秒內的平均溫度,通過呼叫print()將結果流寫入標準輸出:
avgTemp.print()
5.1.5 執行
當應用定義完成后,可以通過呼叫StreamExecutionEnvironment.execute()來執行它:
env.execute("Compute average sensor temperature")
Flink程式都是通過延遲計算(lazily execute)的方式執行,
- 也就是說,那些創建資料源和轉換操作的API呼叫不會立即觸發任何實際的資料處理,
- 相反,這些API呼叫只是在執行環境中創建一個執行計劃,該計劃包括從環境創建的流式資料源以及應用于這些資料源之上的一系列轉換,
- 只有在呼叫
execute()時,系統才會觸發程式的執行,
構建完成的計劃會被轉換為JobGraph并提交給JobManager執行,
- 根據執行環境的型別,系統可能需要將JobGraph發送到作為本地執行緒啟動的JobManager,或將JobGraph發送到遠程JobManager,
- 如果JobManager遠程運行,除了JobGraph之外,我們還需要提供一個包含應用程式的所有類和所需依賴項的JAR檔案,
5.2 轉換操作
在本節中,我們將概述DataStream API中的基本轉換,
- 流式轉換以一個或多個資料流作為輸入,并將它們轉換為一個或多個輸出流,
- 撰寫一個DataStream API程式本質上可以歸結為:通過組合不同的轉換來創建一個滿足應用邏輯的Dataflow圖,
大多數流式轉換都基于用戶自定義的函式來完成,這些函式封裝了用戶的邏輯,指定了如何將輸入流的元素轉換為輸出流的元素,函式可以通過實作某個特定轉換的介面類來定義,例如下面的MapFunction
class MyMapFunction extends MapFunction[Int, Int] {
override def map(value: Int): Int = value + 1
}
DataStream API為那些最常見的資料轉換操作都提供了對應的轉換抽象,我們將DataStreamAPI的轉換分為四類
- 作用于單個事件的基本轉換
- 針對相同鍵值事件的KeyedStream轉換
- 將多條資料流合并為一潭訓將一條資料流拆分成多條流的轉換
- 對流中的事件進行重新組織的分發轉換
5.2.1 基本轉換
基本轉換單獨處理每個事件,這意味著每個輸出記錄都是由單個輸入記錄生成的,常見的基本轉換函式有:簡單的值轉換、記錄拆分或過濾等,
5.2.1.1 Map
通過呼叫DataStream.map()方法可以指定map轉換來產生一個新的DataStream,它將每個輸入事件傳遞給用戶自定義的映射器(user-defined mapper),映射器回傳一個輸出事件,這個輸出事件可能是不同型別的(eg, DataStream[Int] => DataStream[String]),圖5-1顯示了將每個正方形轉換為圓形的map轉換,
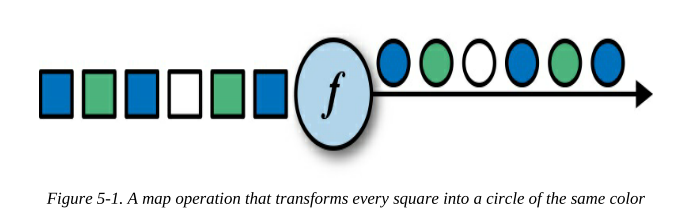
MapFunction的兩個型別引數分別是是輸入事件的型別和輸出事件的型別,MapFunction的map()方法將每個輸入事件準確地轉換為一個輸出事件:
// T: 輸入元素的型別
// O: 輸出元素的型別
MapFunction[T,O]
> map(T): O
下面舉一個簡單的例子
val sensorIds: DataStream[String] = reading.map(new MyMapFunction)
class MyMapFunction extends MapFunction[SensorReading, String] {
override def map(r: SensorReading): String = r.id
}
也可以用Lambda運算式進一步簡化
val sensorIds: DataStream[String] = reading.map(r => r.id)
5.2.1.2 Filter
fliter轉換通過一個回傳值為Boolean型別的函式來決定事件的去留:
- 如果回傳值為true,那么它會保留輸入事件并且將其轉發到輸出,
- 否則它會把事件丟棄,
- 通過呼叫DataStream.filter()方法可以指定過濾器轉換,并生成與輸入DataStream相同型別的輸出DataStream,
- 圖5-2顯示了一個只保留白色方塊的過濾操作,
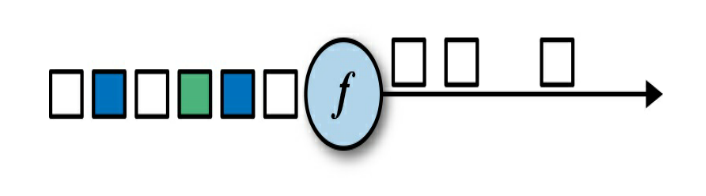
FilterFunction型別引數是輸入流的型別,它的filter()方法接收一個輸入事件并回傳一個布林值:
FilterFunction[T]
> filter(T): Boolean
下面舉個簡單的例子
var filteredSensors = readings.filter(r => r.temperature >= 25)
5.2.1.3 FlatMap
flatMap轉換與map類似,但是它可以為每個輸入事件生成零個、一個或多個 輸出事件,
圖5-3顯示了一個基于傳入事件的顏色區分其輸出的flatMap操作,
- 如果輸入是白色方塊,則不加改動直接輸出,
- 將黑色方塊復制,
- 將灰色方塊丟棄掉,
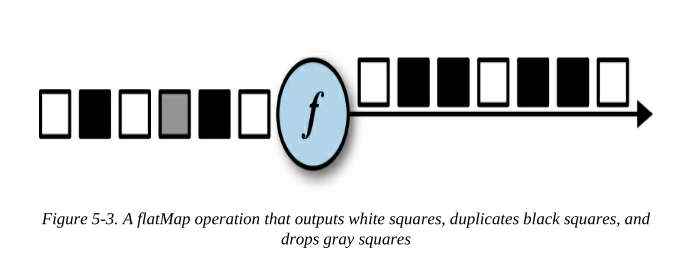
flatMap函式定義如下,可以通過向Collector物件傳遞資料的方式來回傳零個、一個或多個事件作為結果
// T: 輸入元素的型別
// O: 輸出元素的型別
FlatMapFunction[T, O]
// 回傳值為Unit,也就是不回傳
// Collector[O]作為輸出引數
> flatMap(T, Collector[O]): Unit
flatMap函式還可以如下定義
FlatMapFunction[T, O]
> flatMap(T): TraversableOnce[O]
下面舉一個簡單的例子
val words = sensorData.flatMap(r => r.id.split(" "))
5.2.2 基于KeyedStream的轉換
KeyedStream抽象可以從邏輯上將事件按照鍵值分配到多個獨立的事件子流中,
KeyedStream可以根據鍵來維護內部狀態,所有具有相同鍵的事件可以訪問相同的狀態,
接下來先介紹keyBy轉換,它可以將要一個DataStream轉換為一個KeyedStream,然后介紹滾動聚合和Reduce,它們可以作用在KeyedStream上
5.2.2.1 keyBy
keyBy轉換通過鍵來將DataStream轉換為KeyedStream,資料流中的事件會根據不同的鍵被分配到不同的磁區(partition),具有相同鍵的所有事件都由下游算子的同一個任務處理,
我們假設以輸入事件的顏色作為鍵,圖5-4將黑色事件分配給一個磁區,將所有其他事件分配給另一個磁區,
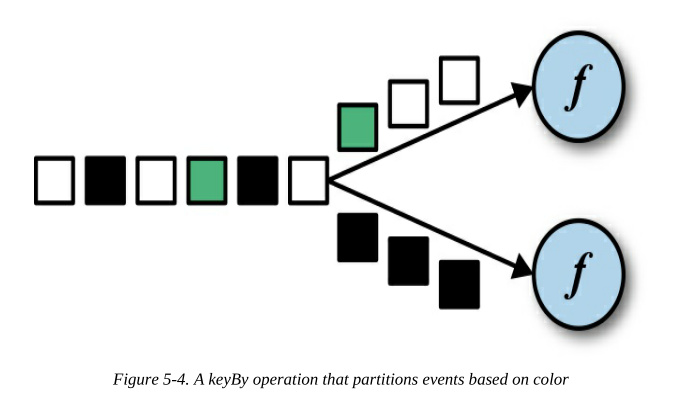
keyBy可以用多種方式來設定如何分類,如下所示
下面舉一個keyBy的例子
val readings: DataStream[SensorReading] = ...
val keyed: KeyedStream[SensorReading, String] = readings.keyBy(r => r.id)
5.2.2.2 滾動聚合
滾動聚合 應用于KeyedStream上,它生成一個包含聚合結果(如求和、最小值和最大值)的DataStream,
- 滾動聚合運算子為每個鍵保存一個聚合值,
- 對于每個輸入事件,算子更新相應的聚合值,并將更新后的值作為輸出事件發送給下游,
- 滾動聚合操作需要接收一個用于指定聚合目標欄位的引數,該引數指定在哪個欄位上計算聚合,
DataStream API提供了以下滾動聚合方法:
| 名稱 | 描述 |
|---|---|
sum() |
滾動計算輸入流在指定欄位上的和 |
max() |
滾動計算輸入流在指定欄位上的最大值 |
min() |
滾動計算輸入流在指定欄位上的最小值 |
minBy() |
滾動計算輸入流中迄今為止最小值,回傳該值所在事件 |
maxBy() |
滾動計算輸入流中起勁為止最大值,回傳該值所在事件 |
注意:不能將多個滾動聚合方法組合使用,每次只能計算一個,
例子:對一個Tuple3[Int, Int, Int]型別的資料在第一個欄位上按照鍵值分組,然后滾動計算第二個欄位的和
val inputStream: DataStream[(Int, Int, Int)] = env.fromElements(
(1, 2, 2),
(2, 3, 1),
(2, 2, 4),
(1, 5, 3))
val resultStream: DataStream[(Int, Int, Int)] = inputStream
.keyBy(0)
.sum(1)
"""output
(1, 2, 2)
(2, 3, 1)
(2, 5, 1)
(1, 7, 2)
第一個欄位是分組,第二個欄位是計算之后的和,第三個欄位沒有意義
"""
5.2.2.3 Reduce
reduce轉換是滾動聚合的一般化(generalization),
- 它在KeyedStream上應用了一個ReduceFunction,該函式將每個輸入事件與當前的reduce結果進行一次組合,并輸出一個DataStream,
- reduce不會改變DataStream的型別,輸出流的型別與輸入流的型別相同,
ReduceFunction介面定義如下
// T: 元素型別
ReduceFunction[T]
> reduce(T, T): T
下面舉一個reduce轉換的例子,在下面的例子中,資料流是會以語言型別作為鍵來進行磁區,最終結果是針對每個語言產生一個不斷更新的單詞串列:
val inputStream: DataStream[(String, List[String])] = env.fromElements(
("en", List("tea")),
("fr", List("vin")),
("en", List("cake")))
val resultStream: DataStream[(String, List[String])] = inputstream
.keyBy(0)
.reduce((x, y) => (x._1, x._2 ::: y._2))
"""output
("en", List("tea"))
("fr", List("vin"))
("en", List("tea", "cake"))
"""
5.2.3 多流轉換
許多應用需要將多個輸入流聯合起來處理,還有一些應用需要將一條流分割成多條子流以應用不同的邏輯,下面,我們將討論那些同時處理多個輸入流或產生多個輸出流的DataStream API轉換,
5.2.3.1 Union
DataStream.union()方法可以合并兩個或多個相同型別的DataStream,并生成一個新的型別相同的DataStream,
圖5-5顯示了一個union操作,它將黑色和灰色事件合并到單個輸出流中,
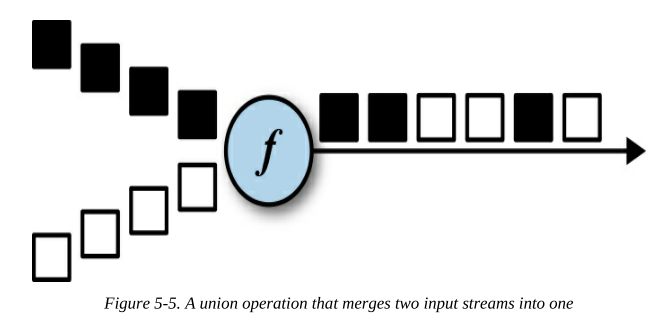
union執行程序中,來自兩條流的事件會以FIFO的方式合并,其順序無法保證(The operator does not
produce a specific order of events.),此外,union運算子不會對資料進行去重,每個輸入事件都被發送到下游,
下面舉個把三條資料流合并為一條的例子
val parisStream: DataStream[SensorReading] = ...
val tokyoStream: DataStream[SensorReading] = ...
val rioStream: DataStream[SensorReading] = ...
val allCities: DataStream[SensorReading] = parisStream,union(tokyoStream, rioStream)
5.2.3.2 Connect,coMap,coFlatMap
考慮這樣一個應用,它監視森林區域,并在發生火災的風險很高時發出警報,應用從溫度傳感器和煙感傳感器上接收資料,當溫度超過給定的閾值 并且 煙霧水平很高時,應用程式會發出火災警報,這時,為了判斷兩者是否同時成立,我們需要合并兩條流來根據兩條流的資訊來綜合判斷
由此可見,合并兩個流的事件是流處理中非常常見的需求,下面來看看相關的API
DataStream.connect()方法接收一個DataStream并回傳一個ConnectedStreams物件,該物件表示兩個聯結在一起的流:
val first: DataStream[Int] = ...
val second: DataStream[String] = ...
val connected: ConnectedStreams[Int, String] = first.connect(second)
ConnectedStreams物件提供了map()和flatMap(),具體用法略
默認情況下,connect()不會在兩個流的事件之間 建立關系,因此兩個流的事件被隨機分配給算子任務,這種行為會產生不確定的結果,通常是不希望看到的,為了在ConnectedStreams上產生確定性結果,可以將connect()與keyBy()或broadcast()結合使用,
- 當使用
keyBy()時,connect()轉換會將兩條資料流中具有相同鍵的事件發送到同一個算子任務上 - 而當使用
broadcast()時,兩條流中有一條被廣播,它的事件被分發給下游算子的所有任務上,這樣可以保證聯合處理這兩個輸入流的元素,
5.2.3.1 Split和Select
split是union的逆操作,它將輸入流 分割為與輸入流相同型別的兩個或多個輸出流,每個輸入事件可以被發送給零個、一個或多個 輸出流,因此,split操作還可以用于過濾或復制事件,
圖5-6顯示了一個split算子,它將所有白色事件與其他事件分開,發往不同的資料流,
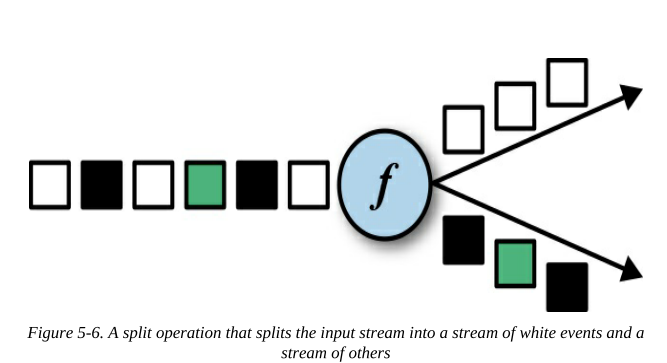
split()方法以一個OutputSelector函式介面作為引數,
// IN: 同DataStream的元素型別
OutputSelector[IN]
> select(IN): Iterable[String]
每個輸入事件到來時都會呼叫OutputSelector.select()方法,并隨即回傳一個java.lang.Iterable[String],回傳的這個String串列中的每個String是這個事件所屬的輸出流的名稱,
split()方法回傳一個SplitStream物件,這個物件提供一個select()方法,通過指定輸出名稱從SplitStream中選擇一潭訓多條流,
實體5-2:將一個數字流分成一個大數字流和一個小數字流
val inputStream: DataStream[(Int, String)] = ...
val splitted: SplitStream[(Int, String)] = inputStream
.split(t => if (t._1 > 1000) Seq("large") else Seq("small"))
val large: DataStream[(Int, String)] = splitted.select("large")
val small: DataStream[(Int, String)] = splitted.select("small")
val all: DataStream[(Int, String)] = splitted.select("large", "small")
5.2.4 分發轉換
當使用DataStream API構建應用程式時,系統會根據操作語意和配置的并行度來自動選擇資料磁區策略并將資料轉發到正確的目標,有時我們可能希望能夠手動選擇磁區策略,在本節中,我們將介紹DataStream中用于控制磁區策略或自定義磁區策略的方法,
下面是常見的磁區策略
| 名稱 | 描述 |
|---|---|
| 隨機 | 隨機資料交換策略由DataStream.shuffle()方法實作,該方法將事件隨機分配到下游算子的并行任務中, |
| 輪流(Round-Robin) | 輪流方法將輸入流的事件以輪流方式均勻分配給后繼任務, |
| 重調(Rescale) | rescale()也是以輪流的方式對事件進行分發,但是每個上游任務只與一部分下游任務建立發送通道,當上游任務數遠小于下游任務數時,這種方法比較好用,下圖展示了輪流和重調的區別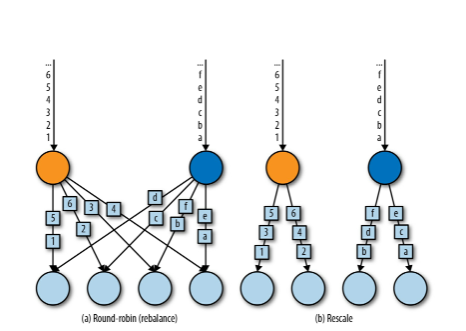 |
| 廣播(Broadcast) | broadcast()將輸入流中的事件復制,并發送給發送給下游算子的所有并行任務, |
| 全域(global) | global()方法將輸入資料流的所有事件發送給下游運算子的第一個并行任務,必須小心使用這種磁區策略,因為將所有事件路由到同一任務可能會影回應用程式性能 |
| 自定義 | 如果所有預定義的磁區策略都不合適,你可以利用partitionCustom()方法來自定義磁區策略 |
自定義磁區例子如下
val numbers: DataStream[(Int)] = ...
numbers.partitionCustom(myPartitioner, 0)
object myPartitioner extends Partitioner[Int]{
val r = scala.util.Random
override def partition(key: Int, numPartitions: Int): Int = {
if (key < 0) 0 else r.nextInt(numPartitions)
}
}
5.3 設定并行度
算子的并行度可以在執行環境級別或算子級別進行控制,默認情況下,應用的所有算子的并行度被設定為應用執行環境的并行度,而執行環境的并行度將根據應用啟動時所處的背景關系自動初始化,
- 如果應用程式在本地執行環境中運行,則將并行度設定為與CPU內核數量相等,
- 在向運行的Flink集群提交應用程式時,除非用戶顯示指定,否則環境并行度將設定為集群的默認并行度
最好將算子并行度設定為隨環境并行度變化的值而不要設定為定值,例如:假設環境并行度為x,可以設定算子并行度為y = x/2,當在本機運行時x=8, y=4,而在集群運行時x=32,y=16,這樣當運行環境變化時,算子并行度也可以隨之變化,
下面的例子演示了如何獲取環境并行度以及如何設定環境并行度
// 獲取環境并行度
val env = StreamExecutionEnvironment.getExecutionEnvironment
val defaultParallelism = env.getParallelism
// 設定環境并行度
env.setParallelism(32)
下面的例子演示了如何設定算子的并行度
// 獲取環境并行度
val env = StreamExecutionEnvironment.getExecutionEnvironment
val defaultParallelism = env.getParallelism
val result = env.addSource(new CustomSource)
// 設定map的并行度為默認并行度的兩倍
.map(new MyMapper).setParallelism(defalutParallelism * 2)
// print資料匯的并行度固定為2
.print().setParallelism(2)
5.4 型別
Flink DataStream應用所處理的事件會以資料物件的形式存在,這些資料物件需要能夠被序列化和反序列化,以通過網路發送它們,或將它們寫入狀態后端、檢查點和保存點,或從狀態后端讀取,Flink使用型別資訊(type information)的概念來表示資料型別,并為每種資料型別自動生成特定的序列化器、反序列化器和比較器,
一般情況下,Flink都可以自動提取資料物件的型別資訊,但當自動提取器失效時,我們也需要手動指定型別資訊,
本節我們會討論Flink支持的型別,如何為資料型別創建型別資訊,以及當Flink無法自動推斷函式的回傳型別的時如何以提示的方式幫助型別系統,
5.4.1 支持的資料型別
Flink支持Java和Scala中可用的所有常見資料型別,可以分為以下類別
- 原始型別
- Java和Scala元組
- Scala樣例類(case class)
- POJO
- 一些特殊型別:陣列、串列、映射、列舉等
對于POJO的解釋:如果一個類滿足如下條件,它會被Flink看作POJO
- 是一個公有類
- 有一個公有的無參默認建構式
- 所有欄位都是公有的或者提供了相應的
getter以及setter方法 - 所有欄位型別都必須是Flink支持的
對特殊型別的解釋:Flink支持多種特殊型別,比如
- 原始或者物件型別的陣列;
- Java的ArrayList、HashMap和Enum型別
- Hadoop的Writable型別,
- Scala的Either、Option和Try型別以及Flink內部實作的Java版本的Either型別
5.4.2 為資料型別創建型別資訊
在Flink的型別系統中,核心類是TypeInformation,它為系統生成序列化器和比較器提供了必要的資訊,當應用提交執行時,Flink的型別系統嘗試為框架處理的每個資料型別自動推斷TypeInformation,因此,大多數情況下,我們都沒有必要手動指定型別資訊,但當自動推斷失靈時,就需要我們為特定資料型別手動生成TypeInformation了,
下面舉幾個生成TypeInformation的例子
// 原始型別的TypeInformation
val stringType: TypeInformation[String] = Types.STRING
// Scala元祖的TypeInformation
val tupleType: TypeInformation[(Int, Long)] = Types.TUPLE[(Int, Long)]
// case class的TypeInformation
val caseClassType: TypeInformation[Person] = Types.CASE_CLASS[Person]
5.4.3 顯式提供型別資訊
顯示提供TypeInformation的方式有兩種,第一種是通過實作ResultTypeQueryable介面來擴展函式,如下面例子所示
class Tuple2ToPersonMapper extends MapFunction[(String, Int), Person] with ResultTypeQueryable[Person] {
override def map(v: (String, Int)): Person = Person(v._1, v._2)
//實作ResultTypeQueryable
override def getProducedType: TypeInformation[Person] = Types.CASE_CLASS[Person]
}
第二種,在定義Dataflow時使用Java DataStream API中的returns()方法來顯式指定某算子的回傳型別
persons = inputStream
.map(t => new Person(t._1, t._2))
.returns(Types.CASE_CLASS[Person])
5.5 定義鍵和參考欄位
在Flink中有很多需要使用鍵索引(key specification)和欄位參考(field reference)的地方,Flink采用各種各樣的靈活方式來定義鍵:通過元素的欄位位置來定義、通過基于字串的欄位運算式來定義、通過KeySelector函式來定義
5.5.1 欄位位置
如果資料型別是元組,則只需使用對應元組元素的欄位位置就可以定義鍵,
例如下面這個例子使用元組的第二個欄位作為輸入流的鍵值
val input: DataStream[(Int, String, Long)] = ...
val keyed = input.keyBy(1)
此外,還可以使用多個元組欄位來定義復合鍵
val keyed2 = input.keyBy(1, 2)
5.5.2 欄位運算式
另一種定義鍵和選擇欄位的方法是使用基于字串的欄位運算式,欄位運算式適用于元組、pojo和case類,
// 最簡單的欄位運算式
val keyedSensors = sensorStream.keyBy("id")
// 在元組型別上使用欄位運算式
val keyed = inputStream.keyBy("_1")
// 使用點運算子來嵌套POJO欄位為鍵值
val persons = inputStream.keyBy("address.zip")
// 使用通配符 `_` 來選擇元組中的全部欄位作為鍵
val keyed = inputStream.keyBy("birthday._")
5.5.3 KeySelector函式
第三種指定鍵的方式是使用KeySelector函式,它可以從輸入事件中提取鍵
// T: 輸入元素的型別
// KEY: 鍵值型別
KeySelector[IN, KEY]
> getKey(IN): KEY
下面的例子會回傳元組中的最大欄位來作為鍵值
val input = DataStream[(Int, Int)] = ...
val keyedStream = input.keyBy(value =https://www.cnblogs.com/t0ugh/p/> math.max(value._1, value._2))
5.6 實作函式
在DataStream API中有很多地方需要使用自定義函式,本節將介紹Flink中定義函式的幾種方式
5.6.1 函式類
Flink中所有用戶自定義函式都是以介面或者抽象類的形式對外暴露的,如MapFunction、FilterFunction和ProcessFunction等
我們可以通過實作介面或者繼承抽象類的方式來定義函式,例如下面的例子
class MyFilter extends FilterFunction[String]{
override def filter(value: String): Boolean = {
value.contains("flink")
}
}
val filted = sentences.filter(new MyFilter())
函式必須是可序列化的
Flink使用Java序列化來序列化所有函式物件,以便將它們發送給對應的算子任務,用戶函式中包含的所有內容都必須是可序列化的,如果您的函式需要一個非序列化的物件實體,您可以將其實作為一個富函式,并在open()方法中初始化非序列化欄位,或者重寫Java序列化和反序列化方法,
5.6.2 Lambda函式
也可以通過Lambda運算式的方式來定義函式
val filted = sentences.filter(_.contains("flink"))
5.6.3 富函式
有時,我們需要在函式 處理第一個記錄之前進行一些初始化作業或者取得函式執行相關的背景關系資訊,DataStream API提供了豐富的函式,它和我們之前見到的普通函式相比可以對外提供更多功能,
DataStream API中的所有轉換函式都有對應的富函式,富函式的使用位置和普通函式以及Lambda函式相同,富函式的名稱以Rich開頭,例如RichMapFunction、RichFlatMapFunction等,
當使用富函式時,你可以對應函式的生命周期實作兩個額外的方法:
-
open()方法是富函式的初始化方法,它在每個任務首次呼叫轉換方法之前呼叫一次 -
close()方法是富函式的終止方法,會在每個任務最后一次呼叫轉換方法后呼叫一次,因此,它通常用于清理和釋放資源, -
另外,還可以使用富函式自帶的
getRuntimeContext()方法來從函式的Runtime中獲取一些資訊
class MyFlatMap extends RichFlatMapFunction[Int, (Int, Int)]{
var subTaskIndex = 0
override def open(config: Configuration): Unit = {
subTaskIndex = getRuntimeContext.getIndexOfThisSubtask
//進行一些初始化作業
}
override def flatMap(in: Int, out: Collector[(Int, Int)]): Unit = {
//子任務的編號從0開始
if(in % 2 == subTaskIndex){
out.collect((subTaskIndex, in))
}
//做一些額外處理作業
}
override def close(): Unit = {
//做一些清理作業
}
}
5.7 匯入外部和Flink依賴
在實作Flink應用時經常需要添加一些外部依賴,應用在執行時,必須能夠訪問到所有依賴,默認情況下,Flink集群只加載核心API依賴(DataStream和DataSet API),對于應用的其他依賴則必須顯式提供,
有兩種方法來確保所在執行應用時可以訪問到所有依賴:
- 將所有依賴打進應用的Jar包中,生成一個“胖Jar”
- 將依賴放到Flink的
./lib目錄下,這樣在Flink行程啟動時就會將依賴加載到Classpath中
推薦使用第一種方式,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/228948.html
標籤:大數據