一、流式計算的未來
在谷歌發表了 GFS、BigTable、Google MapReduce 三篇論文后,大資料技術真正有了第一次飛躍,Hadoop 生態系統逐漸發展起來,
Hadoop 在處理大批量資料時表現非常好,主要有以下特點:
1、計算開始之前,資料必須提前準備好,然后才可以開始計算;
2、當大量資料計算完成之后,會輸出最后計算結果,完成計算;
3、時效性比較低,不適用于實時計算;
而隨著實時推薦、風控等業務的發展,資料處理時延要求越來越高,實時性要求也越來越高,Flink 開始在社區嶄露頭角,
Apache Flink 作為一款真正的流處理框架,具有較低的延遲性,能夠保證訊息傳輸不丟失不重復,具有非常高的吞吐,支持原生的流處理,
本文主要介紹 Flink 的時間概念、視窗計算以及 Flink 是如何處理視窗中的亂序資料,
二、Flink 中的時間概念
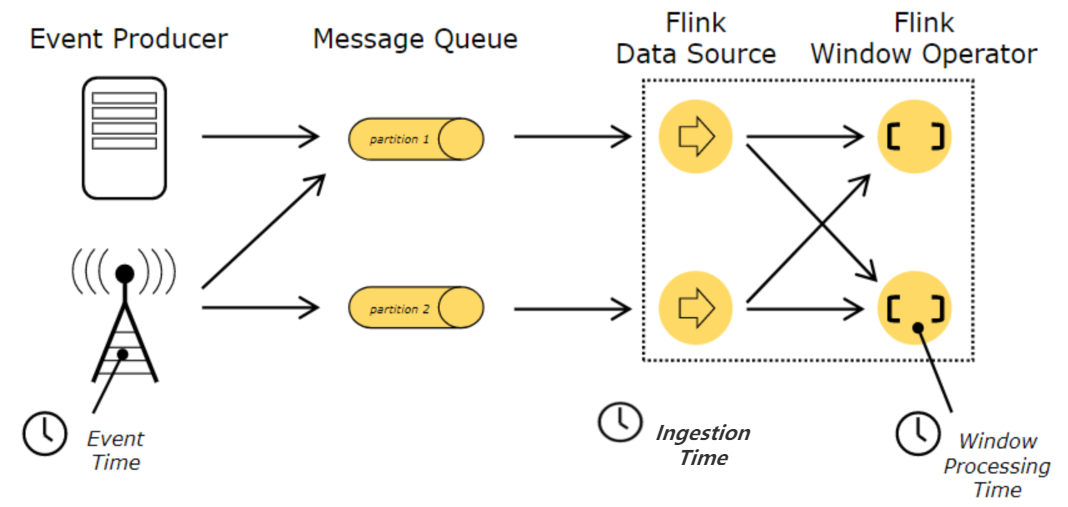
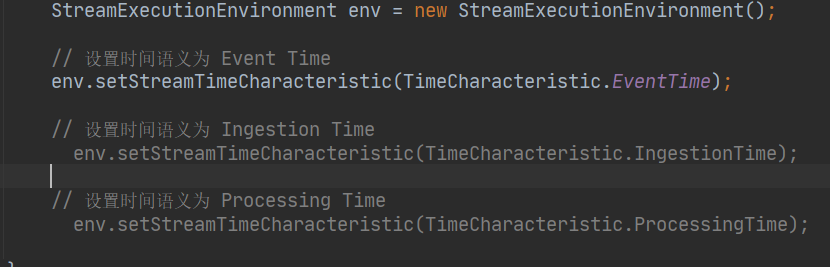
在 Flink 中主要有三種時間概念:
(1)事件產生的時間,叫做 Event Time;
(2)資料接入到 Flink 的時間,叫做 Ingestion Time;
(3)資料在 Flink 系統里被操作時機器的系統時間,叫做 Processing Time
處理時間是一種比較簡單的時間概念,不需要流和系統之間進行協調,可以提供最佳的性能和最低的延遲,但是在分布式環境中,多臺機器的處理時間無法做到嚴格一致,無法提供確定性的保障,
而事件時間是事件產生的時間,在進入到 Flink 系統的時候,已經在 record 中進行記錄,可以通過用提取事件時間戳的方式,保證在處理程序中,反映事件發生的先后關系,
三、Flink 為什么需要視窗計算
我們知道流式資料集是沒有邊界的,資料會源源不斷的發送到我們的系統中,
流式計算最終的目的是去統計資料產生匯總結果的,而在無界資料集上,如果做一個全域的視窗統計,是不現實的,
只有去劃定一定大小的視窗范圍去做計算,才能最侄訓總到下游的系統中,用來分析和展示,
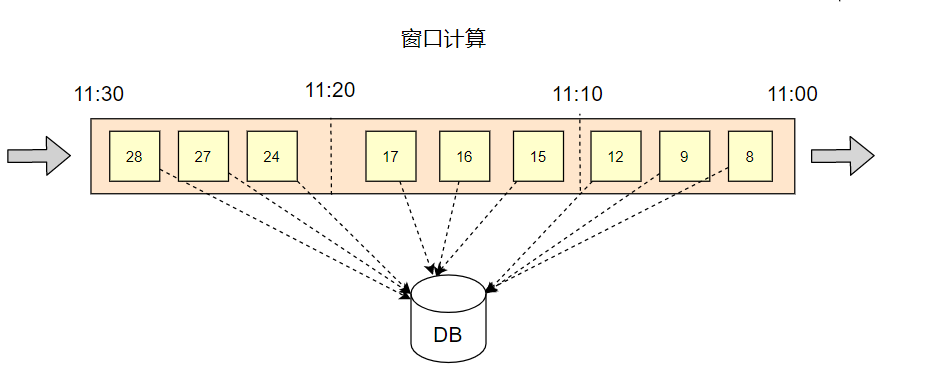
在 Flink 進行視窗計算的時候,需要去知道兩個核心的資訊:
- 每個 Element 的 EventTime 時間戳?(在資料記錄中指定即可)
- 接入的資料,何時可以觸發統計計算 ? (視窗 11:00 ~ 11:10 的資料全部被接收完)
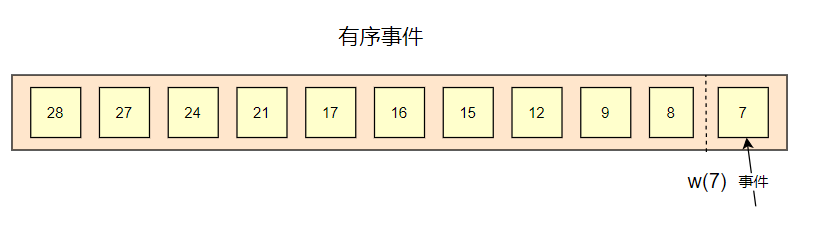
有序事件
假設在完美的條件下,資料都是嚴格有序,那么此時,流式計算引擎是可以正確計算出每個視窗的資料的
無序事件
但是現實中,資料可能會因為各種各樣的原因(系統延遲,網路延遲等)不是嚴格有序到達系統,甚至有的資料還會遲到很久,此時 Flink 需要有一種機制,允許資料可以在一定范圍內亂序,
這種機制就是水印,
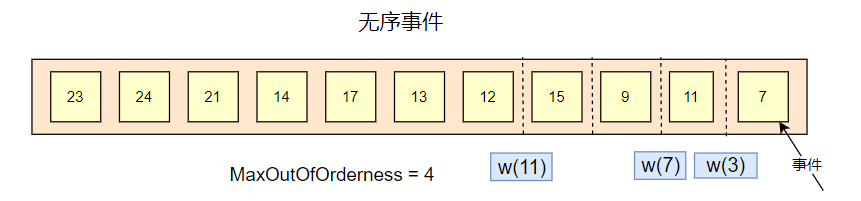
如上面,有一個引數: MaxOutOfOrderness = 4,為最大亂序時間,意思是可以允許資料在多少范圍內亂序,可以是 4 分鐘,4 個小時 等,
水印的生成策略是,當前視窗最大事件時間戳減去 MaxOutOfOrderness 的值,
如上圖,事件 7 會產生一個 w(3) 的水印,事件 11 會產生要給 w(7) 的水印,但是事件 9 ,是小于事件 11 的,此時不會觸發水印的更新,事件 15 會產生一個 w(11) 的水印, 也就是說,水印反映了事件的整體流轉的趨勢,只會上升,不會下降,
水印表示了所有小于水印值的事件都已經到達了視窗,
每當有新的最大時間戳出現時,就會產生新的 watermark
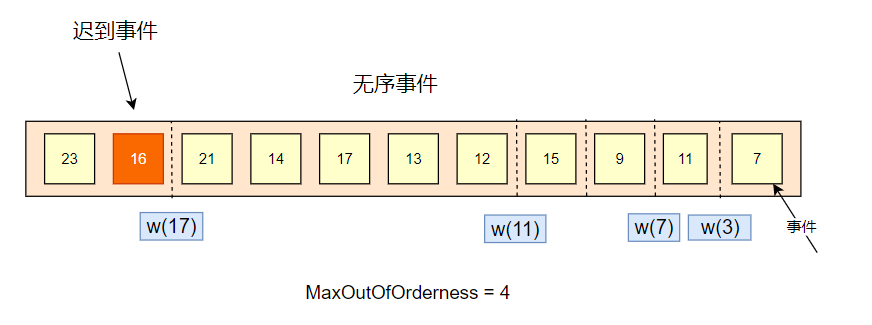
遲到事件
對于事件時間小于水印時間的事件,稱為遲到事件,遲到事件是不會被納入視窗統計的,
如下圖,21 的事件進入系統之后,會產生 w(17) 的水印,而后來的 16 事件,由于小于當前水印時間 w(17),是不會被統計的了,
何時觸發計算
我們用一個圖來展示何時會觸發視窗的計算
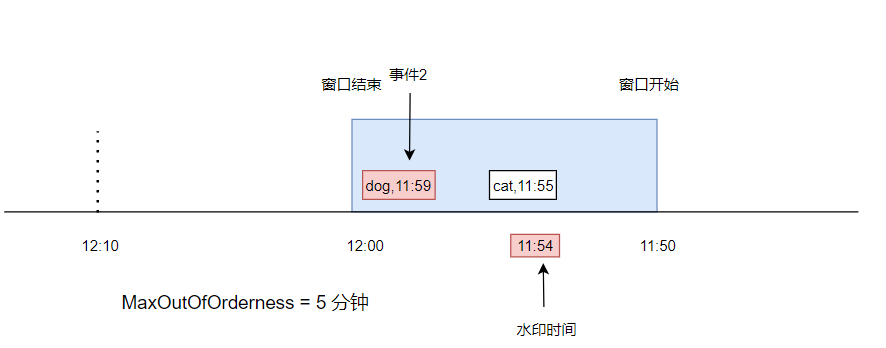
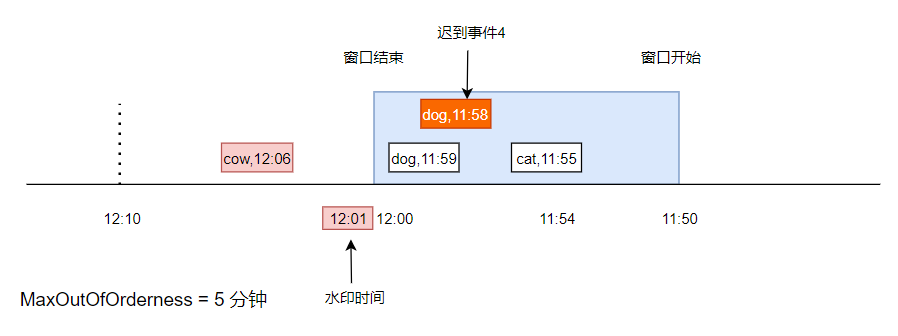
如下圖,表示一個 11:50 到 12:00 的視窗,此時有一條資料, cat,11:55,事件時間是 11:55,在視窗中,最大延遲時間是 5 分鐘,所以當前水印時間是 11:50

此時又來了一條資料,dog,11:59,事件時間是 11:59,進入到了視窗中,
由于這個事件時間比上次的事件時間大,所以水印被更新成 11:54,此時由于水印時間仍然小于視窗結束時間,所以仍然沒有觸發計算,
又來了一條資料, cow,12:06,此時水印時間被更新到了 12:01 ,已經大于了視窗結束時間,此時觸發了視窗計算(假設計算邏輯就是統計視窗內不同元素的個數),
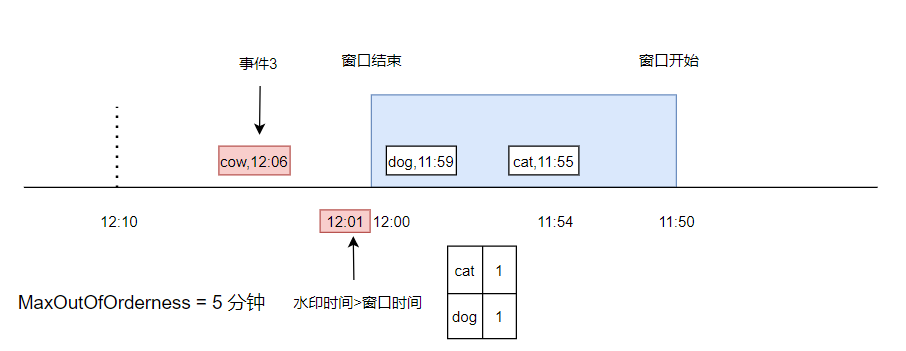
假設又來了一條事件,是 dog,11:58,由于它已經小于了水印時間,并且在上次觸發視窗計算之后,視窗已經被銷毀,所以,這條事件是不會被觸發計算的了,
此時,可以這個事件放到 sideoutput 佇列中,額外邏輯處理,
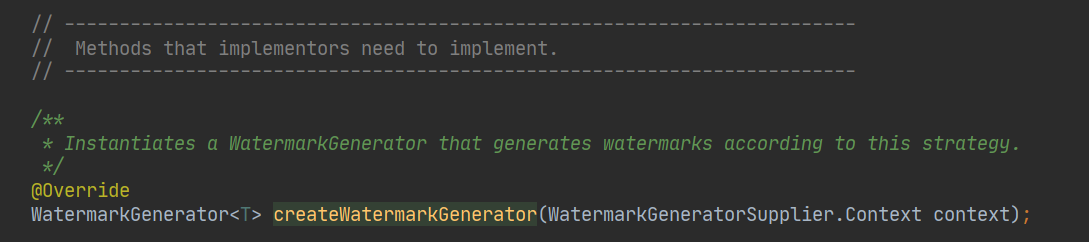
四、Flink 1.11 版本 中,如何定義水印
所以在 1.11 版本中,重構了水印生成介面,新版本中,主要通過 WatermarkStrategy 類,來使用不同的策略生成水印,
新的介面提供了很多靜態的方法和帶有預設實作的方法,如果想自己定義生成策略,可以實作這個方法:
生成一個 WatermarkGenerator
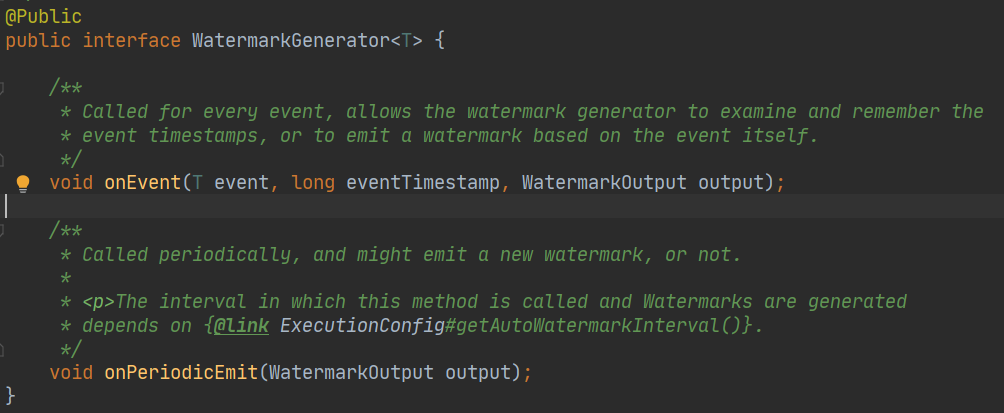
這個類也很簡單明了
- onEvent:如果我們想依賴每個元素生成一個水印發射到下游,可以實作這個方法;
- OnPeriodicEmit:如果資料量比較大的時候,我們每條資料都生成一個水印的話,會影響性能,所以這里還有一個周期性生成水印的方法,
為了方便開發,Flink 還提供了一些內置的水印生成方法供我們使用
- 固定延遲生成水印
我們想生成一個延遲 3 s 的固定水印,可以這樣做
DataStream dataStream = ...... ;
dataStream.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)));
- 單調遞增生成水印
相當于上述的延遲策略去掉了延遲時間,以 event 中的時間戳充當了水印,可以這樣使用:
DataStream dataStream = ...... ;
dataStream.assignTimestampsAndWatermarks(WatermarkStrategy.forMonotonousTimestamps());
五、一個簡單的小例子,來統計視窗中字母出現的次數
public class StreamTest1 {
@Data
@AllArgsConstructor
@NoArgsConstructor
@ToString
public static class MyLog {
private String msg;
private Integer cnt;
private long timestamp;
}
public static class MySourceFunction implements SourceFunction<MyLog> {
private boolean running = true;
@Override
public void run(SourceContext<MyLog> ctx) throws Exception {
while (true) {
Thread.sleep(1000);
ctx.collect(new MyLog(RandomUtil.randomString(1),1,System.currentTimeMillis()));
}
}
@Override
public void cancel() {
this.running = false;
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 資料源使用自定義資料源,每1s發送一條隨機訊息
env.addSource(new MySourceFunction())
// 指定水印生成策略是,最大事件時間減去 5s,指定事件時間欄位為 timestamp
.assignTimestampsAndWatermarks(
WatermarkStrategy.
<MyLog>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((event,timestamp)->event.timestamp))
// 按 訊息分組
.keyBy((event)->event.msg)
// 定義一個10s的時間視窗
.timeWindow(Time.seconds(10))
// 統計訊息出現的次數
.sum("cnt")
// 列印輸出
.print();
env.execute("log_window_cnt");
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/230966.html
標籤:大數據
上一篇:請教一個行轉列的SQL
下一篇:Redis資料結構