Redis開發
API及底層實作
全域命令
keys *:查看所有的鍵 O(n)
dbsize:鍵總數 O(1)
exists key :檢查鍵是否存在
del key:洗掉鍵
expire key seconds:鍵過期
ttl : 回傳鍵的剩余時間 (
- >=0: 剩余時間
- -1:沒設定過期時間
- -2:鍵不存在
)
type key:鍵的型別
object encoding:查詢內部編碼
資料結構和內部編碼:
每種資料結構都有兩種以上的內部編碼實作,好處:
- 可以改進內部編碼,而對外的資料結構和命令沒有影響
- 多種內部編碼實作可以在不同場景下發揮各自的優勢
單執行緒架構
為什么單執行緒還能這么快?
- 純記憶體訪問
- 非阻塞I/O,redis使用epoll作為I/O多路復用技術的實作
- 單執行緒避免了執行緒切換和競態產生的消耗
缺點:如果某個命令執行時間過長,會造成其他命令的阻塞,
字串
字串型別的值可以是普通字串,也可以是復雜字串(Json, Xml), 數字(整數、浮點數),二進制的圖片、音頻、視頻,但值最大不能超過512MB
字串api
-
set key value [ex seconds] [px milliseconds] [nx | xx]
- ex seconds : 為鍵設定秒級過期時間
- px milliseconds : 為鍵設定毫秒級過期時間
- nx : 鍵不存在才設定成功,用于添加
- xx : 鍵存在才設定成功,用于更新
-
get key
-
mset key value [key value ……]
-
mget key [key……]
-
incr key 自增
- 值不是整數,回傳錯誤
- 值是整數,回傳自增后的結果
- 鍵不存在,按照值為0自增,回傳結果為1
-
decr、incrby(自增指定數字)、decrby、incrbyfloat
-
append key value 向字串尾部追加值
-
strlen key 字串長度
每個中文占用3個位元組
-
getset key value 設定并回傳原值
-
setrange key offset value 設定指定位置的字符
-
getrange key start end 獲取部分字串,下標從0開始,包括右下標
字串內部編碼
有3種編碼:
- int:8個位元組的長整型
- embstr:小于等于39個位元組的字串
- raw:大于39個位元組的字串
通過object encoding key 查看內部編碼
使用場景
- 快取功能
- 計數:視頻播放數
- 共享session:出于分布式服務考慮,已不適用
- 限速:防盜刷
哈希
api
- hset key field value 設定值
- hget key field 獲取值
- hdel key field 洗掉filed
- hlen key 計算field的個數
- hmget key field [filed ……]
- hmset key filed value ……
- hexists key field 判斷field是否存在
- hkeys key 獲取所有field
- hvals key 獲取所有value
- hgetall key 獲取所有的f-v,如果個數過多,會造成阻塞
- hincrby key field
- hincrbyfloat key field
- hstrlen key field 計算value的長度
內部編碼
有2種:
ziplist (壓縮串列):當元素個數小于hash-max-ziplist-entries配置(默認512個)、同時所有值都小于hash-max-ziplist-value配置(默認64位元組),redis使用ziplist作為內部編碼,ziplist 使用緊湊的結構實作多個元素的連續存盤,在節省記憶體方面比hashtable更加好,
hashtable (哈希表):當上述條件無法滿足時,redis使用hashtable,因為此時ziplist 的讀寫效率會下降,而hashtable 的讀寫時間復雜度為O(1)
使用場景
快取:用戶的id作為鍵后綴,多對f-v對應每個用戶的屬性
串列
一個串列最多可以存盤232-1 個元素,串列中的元素是有序的且可以重復的
api
lpush key value 從左插入元素
rpush key value 從右插入元素
lrange 0 -1 從左到右獲取串列中的所有元素
linsert key before | after pivot value 從串列中找到等于pivot的元素,插入
lrange key start end 獲取指定索引范圍的所有元素,索引下標:從左到右是0 - N-1,從右到左是-1 - -N;lrange中的end元素包括自身,
lindex key index 獲取指定索引下標
llen key 獲取串列長度
lpop key 從左彈出元素
lrem key count value
- count > 0, 從左到右,最多洗掉count個value值的元素
- count < 0, 從右到左,最多洗掉count絕對值的元素
- count = 0,洗掉所有,
ltrim key start end 按照索引范圍剪串列
lset key index newValue 修改指定索引下標的元素
blpop/brpop key timeout 阻塞彈出
-
key 可以多個
-
timeout 如果串列為空,則等待timeout時間回傳,timeout = 0時,則一直等待,
-
如果串列不為空,立即回傳
注意:
- 如果有多個鍵,則從左到右遍歷鍵,有一個鍵可以回傳就立即回傳,
- 如果多個客戶端對同一個鍵執行blpop,則最先執行命令的客戶端回傳,其他客戶端阻塞,
內部編碼
ziplist:當串列元素個數小于list - max - ziplist - entries(默認512個),同時串列中每個元素的值小于list - max - ziplist - values(默認64位元組)
linkedlist:無法滿足ziplist條件,則用linkedlist
使用場景
- 訊息佇列:用rpush + blpop 實作阻塞佇列,多個消費者客戶端使用blpop阻塞“搶”串列尾部元素,多個客戶端保證了消費的負載均衡和高可用性,
- 文章串列:每個用戶有自己的文章串列,需要分頁展示文章串列
- rpush user:1:articles 文章
- lrange user:1:articles 0 9 (ps:取出前10條)
集合
集合不允許有重復元素,且元素是無序的,不能通過索引獲取,
api
sadd key element[...] 添加元素
srem key element[...] 洗掉元素
scard key 計算元素個數
sismember key element 判斷元素是否在集合中,回傳1存在,0不存在
srandmember key 【count】 隨機回傳集合中指定個數的元素
spop key 隨機彈出
smembers key 獲取所有元素,可能會造成阻塞
sinter key [key...] 求交集
sunion key [key...] 求并集
sdiff key [key...] 求差集
sinterstore / sunionstore / sdiffstore destination key [key...] 求結果并保存
內部編碼
intset(整數集合):元素都是整數并且元素個數小于 set - max - intset - entries (默認512個),減少記憶體的使用
hashtable(哈希表):無法滿足上述,則用hashtable
使用場景
- 標簽:比如用戶對娛樂、體育、歷史等比較感興趣,可以得到喜歡同一個標簽的人,以及用戶的共同喜好標簽,
- 給用戶添加標簽和給標簽添加用戶,需要在一個事務中進行
- 洗掉用戶下的標簽和洗掉標簽下的用戶,也需要在一個事務中進行
- 計算用戶共同感興趣的標簽:sinter user:1:tage user2:tag
- 抽獎
有序集合
沒有重復元素,給每個元素設定一個分數,作為排序的依據;提供了獲取指定元素分數和元素范圍查詢、計算成員排名等功能
api
zadd key score member [....] 添加成員
zcard key 計算成員個數
zscore key memeber 計算某個成員分數
zrank key memeber 從低到高排名
zrevrank key member 從高到底排名
zrem key member [....] 洗掉成員
zincrby key increment member 增加成員分數
zrange key start end [withscores] 回傳指定排名范圍成員
zrevrange key start end [withscores] 回傳指定排名范圍成員
zrangebyscore key min max 回傳指定分數范圍成員
zcount key min max 回傳指定分數范圍成員個數
zremrangebyrank key start end 洗掉指定排名范圍內的元素
zremrangebyscore key min max 洗掉指定分數范圍內的元素
zinterstore destination numkeys key [key...] [weights [weight ...]] [aggregate sum|min|max] 求交集
- destination : 保存到目標集合
- numkeys :鍵的個數
- weights:每個鍵的權重,默認是1
- aggregate :聚合運算,默認是sum
zunionstore......
內部編碼
ziplist:元素個數小于zset - max - ziplist - entries(默認128個),值小于zset - max - ziplist - value(默認64位元組)
skiplist:不滿足上述條件
使用場景
-
排行榜:比如對用戶上傳的視頻做排行榜,可以按照時間、播放量、贊數排行,
比如贊數:
-
添加用戶贊數
zadd ...
之后再獲得一個贊:zincrby ....
-
取消用戶贊數
zrem ...
-
展示獲取贊數最多的10個用戶
zrevrangebyrank ...
-
壓縮串列底層實作
壓縮串列是串列鍵和哈希鍵的底層實作之一,鍵值要么是小整數值,要么是短字串
壓縮串列是為了節約記憶體,是由一系列特殊編碼的連續記憶體塊組成的順序型資料結構,一個壓縮串列可以包含任意多個節點(entry),每個節點可以保存一個位元組陣列或者一個整數值
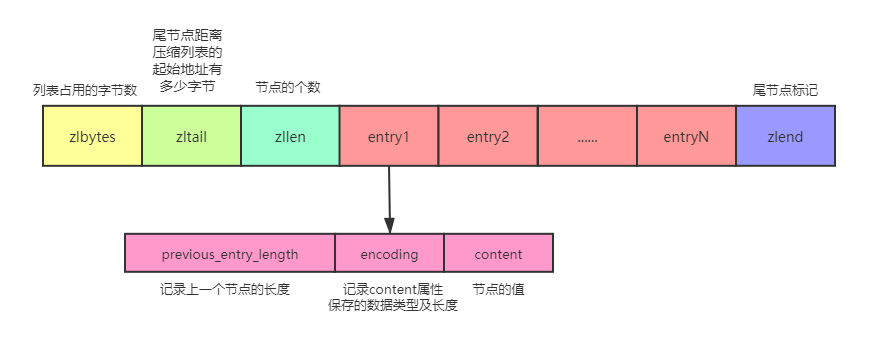
壓縮串列組成:
| 屬性 | 型別 | 長度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4位元組 | 記錄整個壓縮串列占用的位元組數:進行記憶體重分配或者計算zlend位置時使用 |
| zltail | uint32_t | 4位元組 | 記錄表尾節點距離壓縮串列的起始地址有多少位元組:可以無須遍歷就確定尾節點地址 |
| zllen | uint16_t | 2位元組 | 記錄串列包含的節點數量:當小于65535時,節點數量;否則,只能遍歷算出數量 |
| entryX | 串列節點 | 不定 | 壓縮串列節點,節點的長度由節點內容決定 |
| zlend | uint8_t | 1位元組 | 特殊值OxFF(十進制255),用于標記壓縮串列的末端 |
節點組成:
每個節點可以保存一個位元組陣列或一個整數值:
位元組陣列:
- 長度小于等于26 - 1的位元組陣列
- 小于等于214 - 1
- 小于等于232 - 1
整數值:
- 4位長,0-12的無符號整數
- 1位元組長的有符號整數
- 3位元組長的有符號整數
- int16_t 型別整數
- int32_t 型別整數
- int64_t 型別整數
previous_entry_length:以位元組為單位,可以是1位元組或5位元組,記錄前一個節點的長度
-
如果前一個節點的長度小于254位元組,該值為1位元組
-
如果前一個節點的長度大于等于254位元組,該值為5位元組,第一位元組會被設定為0xFE(254),后4個位元組表示前一節點的長度
作用:可以根據當前節點的起始地址計算前一節點的起始地址,壓縮串列從表尾到表頭的遍歷操作就是這樣實作的,
encoding:記錄content屬性保存的資料型別及長度
-
位元組陣列:1位元組、2位元組或5位元組長,值最高位為00,01或者10
編碼 編碼長度 content屬性保存的值 00bbbbbbb 1位元組 長度小于等于26 - 1位元組的位元組陣列 01bbbbbbb xxxxxxxx 2位元組 長度小于等于214 - 1位元組的位元組陣列 10___ aaa…… 5位元組 長度小于等于232 - 1位元組的位元組陣列 -
整數:1位元組長,值的最高位以11開頭
編碼 編碼長度 content屬性保存的值 11000000 1位元組 int16_t型別的整數 11010000 1位元組 int32_t型別的整數 11100000 1位元組 int64_t型別的整數 11110000 1位元組 1位元組 11111110 1位元組 8位有符號整數 1111xxxx 1位元組 沒有content屬性,本身包含了0-12的值
content:負責保存節點的值,節點值可以是一個整數或位元組陣列
連鎖更新:壓縮串列恰有好多個連續的、長度介于250位元組至253位元組的節點,當添加一個長度大于等于254位元組的節點時,可能會導致后續的節點的previous_entry_length屬性從1位元組擴展為5位元組,洗掉節點也可能產生更新,時間復雜度O(n2)
整數集合底層實作
整數集合是集合鍵的底層實作之一,集合只包含整數值元素并且元素數量不多,
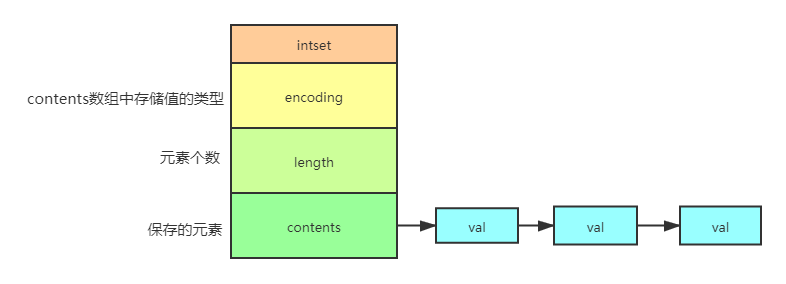
encoding:contents陣列中存盤值的型別
- int16_t
- int32_t
- int64_t
length:集合包含的元素個數
contents:按照從小到大的順序保存元素
升級:當添加一個新元素到整數集合時,并且新元素的型別比整數集合中所有元素型別都要長時,要先進行升級,然后才將新元素添加到整數集合中,
? 升級整數集合的三步驟:
-
根據新元素的型別,擴展整數集合底層陣列的空間大小,并為新元素分配空間
-
將底層陣列現有的所有元素都轉換成與新元素相同的型別,然后將元素放到正確的位置上,需要維持底層陣列的有序性
-
將新元素添加到底層陣列
每次升級都需要對底層陣列的元素進行型別轉換,因此向整數集合添加新元素的時間復雜度為O(N)
升級后新元素的位置:
? 引發升級的新元素的長度總是比整數集合所有的元素長度大,
- 新元素小于所有現有元素時,新元素會被放置在底層陣列的最開頭
- 新元素大于所有現有元素時,新元素會被放置在底層陣列的最末尾
升級的好處:提升整數集合的靈活性,盡可能節約記憶體
? 提升靈活性:整數集合通過自動升級底層陣列來適應新元素,因此可以隨意將不同型別的整數添加到集合中,靈活性較好,
? 節約記憶體:整數集合既能保存三種不同型別的值,又能確保升級操作只會在有需要的時候進行,可以盡量節省記憶體,
整數集合不支持降級,一旦升級,就會一直保持升級后的狀態
跳躍表底層實作
跳表是一種有序的資料結構,通過在每個節點中維持多個指向其他節點的指標,從而達到快速訪問節點的目的
跳表是有序集合鍵的底層實作之一,當有序集合中包含的元素個數較多或者元素的成員是比較長的字串時
redis用到跳表的地方:有序集合鍵、集群節點的內部資料結構
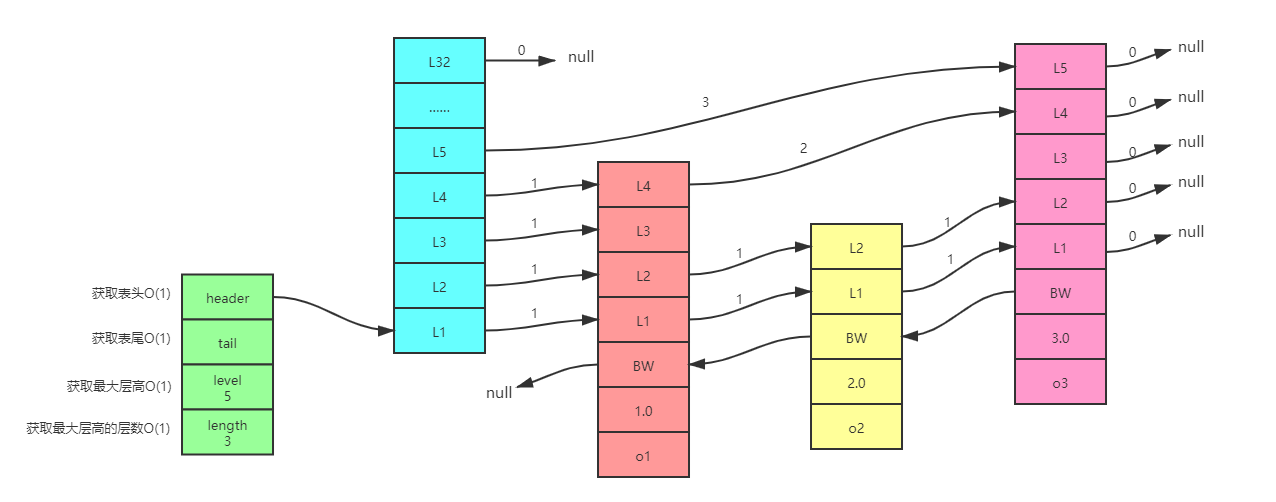
? 表頭節點的結構:表頭節點也有后退指標、分值和成員物件
- header:指向跳躍表的表頭節點
- tail:指向跳躍表的表尾節點
- level:記錄目前跳躍表內,層數最大的那個節點的層數(表頭節點的層數不計)
- length:跳躍表的長度
? 跳表節點的結構:
-
level陣列:level陣列可以包含多個元素,每個元素都包含前進指標和跨度,
? 前進指標用于從表頭向表尾訪問其他節點,跨度則記錄了前進指標所指向節點和當前節點的距離,
? 層的數量越多,訪問其他節點的速度就更快,
? 每次創建一個新節點時,會隨機生成一個1-32之間的值作為level陣列的大小,
? 跨度實際上是用來排位的,而不是遍歷:在查找某個節點的程序中,將沿途訪問過的所有層的跨度累計得到的結 果就是目標節點在跳表中的排位,
-
后退指標:指向位于當前節點的前一個節點,可以用于從表尾向表頭遍歷時使用,每次只能后退至前一個節點
-
分值:在跳表中,節點按各自所保存的分值從小到大排列
-
成員物件:節點所保存的成員物件
各個節點保存的成員物件必須是唯一的,但是多個節點保存的分值可以是相同的,如果分值相同,則按照成員物件的字典序來排序,較小的排前面,
字典底層實作
Redis資料庫使用字典作為底層實作,字典也是哈希鍵的底層實作之一,當包含的鍵值對比較多或者鍵值對中的元素都是比較長的字串時
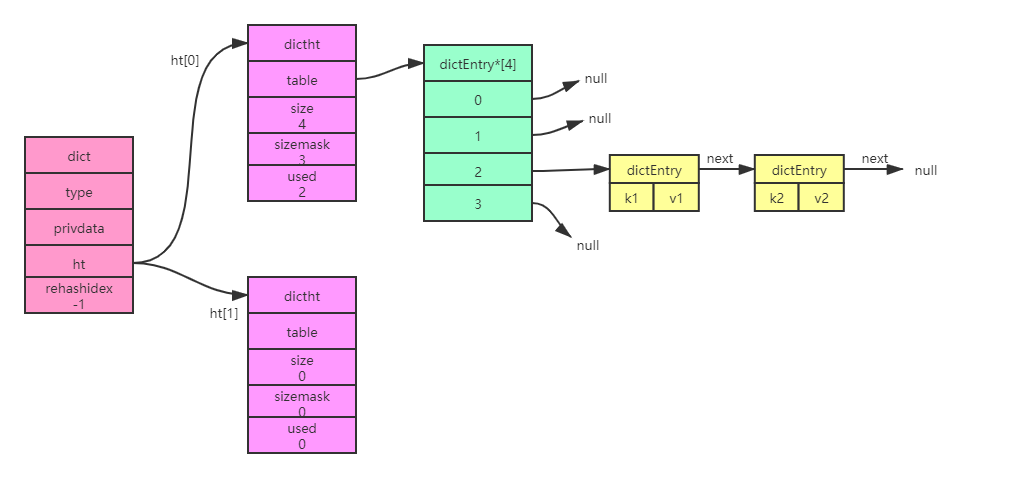
字典組成:
-
type:一個指向dictType結構的指標,每個dictType保存了一組用于操作特定型別鍵值對的函式
dictType包含的函式:計算hash值;復制鍵;復制值;銷毀鍵;銷毀值;對比鍵
-
privdata:傳給函式的可選引數
-
ht:包含兩個項的陣列,每個項都是一個哈希表,一般只是用ht[0],ht[1]只會在對ht[0]哈希表進行rehash使用
-
rehashidx:rehash索引,記錄當前rehash的進度,如果當前沒有進行rehash,值為-1
哈希表組成:
- table:哈希陣列,陣列中的每一個元素指向一個entry結構,每個entry保存一個鍵值對
- size:陣列的大小
- sizemask:等于size - 1,用hash值&sizemask算出鍵應該放在哪個索引上
- used:目前哈希表的鍵值對數量
哈希表節點組成:
- key:鍵
- v:值,可以是一個指標或者uint64_t或者是int64_t
- next:指向另一個節點的指標,將多個哈希值相同的鍵值對連接起來
哈希演算法:
使用MurmurHash2演算法,呼叫type中的計算哈希值的函式算出hash,然后和sizemask進行按位&運算
鍵沖突:
采用鏈地址法,為了速度考慮,采用頭插法,總是將新節點添加到鏈表的表頭
rehash:
當保存的鍵值對太多或太少,需要通過rehash對哈希表的大小進行相應的擴展或者收縮,讓負載因子維持在一個合理范圍內,
rehash步驟:
- 為哈希表ht[1] 分配空間,空間的大小取決于要執行的操作以及ht[0]當前包含的鍵值對數量:
- 如果是擴展操作,ht[1] 大小為第一個大于等于ht[0].used * 2 的 2n
- 如果是收縮操作,ht[1] 大小為第一個大于等于ht[0].used 的 2n
- 將ht[0] 的所有鍵值對rehash到ht[1]
- 當ht[0] 的所有鍵值對遷移到ht[1]后,釋放ht[0],將ht[1] 設定為ht[0],并為ht[1] 新建一個空白的哈希表,為下一次rehash做準備
哈希表的擴展與收縮:
擴展:
-
當前沒有在執行 BGSAVE 或 BGREWRITEAOF ,并且負載因子大于等于1
-
當前有在執行 BGSAVE 或 BGREWRITEAOF,并且負載因子大于等于5
負載因子 = (哈希表已保存的節點數量)/ 哈希表大小
在執行BGSAVE 或 BGREWRITEAOF 時,需要創建子行程,大多數作業系統都是采用寫時復制來優化子行程使用效率,所以在子行程存在期間,提高執行擴展所需負載因子,避免子行程存在期間進行擴展操作,避免不必要的記憶體寫入,最大限度節約記憶體,
收縮:負載因子小于0.1時,執行收縮操作,
漸進式rehash:
rehash并不是一次性完成,而是分多次、漸進式完成,如果鍵值對數量比較多,要一次性將全部鍵值對rehash到ht[1],可能會導致服務器在一段時間內停止服務
rehash步驟:
- 為ht[1] 分配空間
- 維持索引計數器rehashidx,并將值設為0,表示rehash開始
- rehash期間,每次對字典執行增刪改查時,順帶將ht[0] 在rehashidx 索引上的所有鍵值對rehash到ht[1],rehash完成后,rehashidx加1
- 當ht[0] 全部的鍵值對rehash完成后,將rehashidx設定為-1,表示完成
rehash期間操作:
- 增:新添加操作只被保存到ht[1],ht[0]不再進行任何添加操作,保證ht[0]鍵值對的數量只增不減,最終變成空表
- 刪、改、查:先在ht[0]里進行,如果沒有操作成功,再到ht[1]進行,
鏈表底層實作
鏈表是串列鍵的底層實作之一,除此之外,發布與訂閱、慢查詢、監視器等功能也用到了鏈表,Redis本身也使用了鏈表保存多個客戶端的狀態資訊
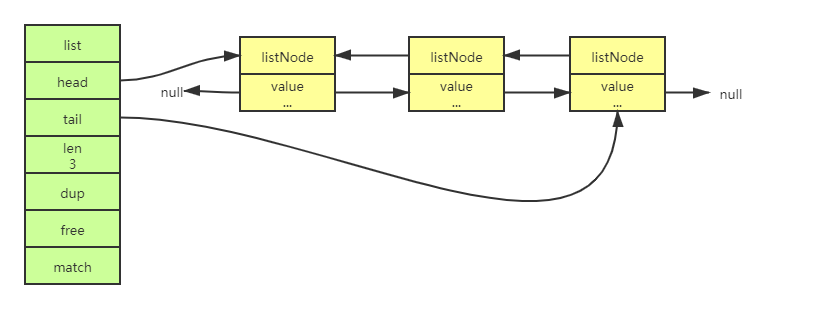
鏈表組成:
- head:表頭節點
- tail:表尾節點
- len:節點的數量
- dup:復制鏈表節點所保存的值
- free:釋放鏈表節點所保存的值
- mathch:對比鏈表節點所保存的值和另一個輸入值是否相等
節點組成:
- prev:前驅節點
- next:后置節點
- value:節點的值
特性:
- 雙向無環鏈表
- 帶表頭和表尾指標
- 帶鏈表長度計數器
- 多型
簡單動態字串
Redis中,C字串只會作為字串字面量,用在一些無須對字串值進行修改的地方,比如列印日志
字串值的鍵值對都是SDS實作的,SDS還可以被用作緩沖區:AOF緩沖區、客戶端輸入緩沖區
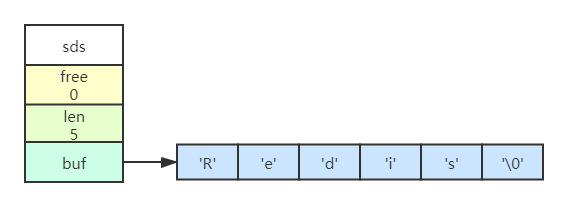
-
len:字串的長度
-
free:未使用的位元組數量
-
buf:位元組陣列,用于保存字串
SDS遵循C字串以空字符結尾的慣例,空字符的1位元組空間不計算在len中,好處:可以直接重用一部分C字串函式,
SDS與C字串的區別:
-
常數復雜度獲取字串長度
C字串不記錄自身的長度,要獲取長度,必須遍歷,O(N);SDS只要反問len屬性就可以知道長度,即使對一個非常長的字串鍵反復執行獲取長度的命令,也不會對系統造成任何影響,
-
杜絕緩沖區溢位
C字串如果沒有分配足夠的記憶體空間,在執行修改字串時可能會溢位,SDS杜絕了緩沖區溢位的可能性:當SDS修改時,會先檢查SDS空間是否滿足修改所需的要求,不滿足自動將SDS擴展至執行修改所需的大小,然后執行實際修改操作,
-
減少修改字串時的記憶體重分配次數
每次增長或縮短一個C字串,都要進行一次記憶體重分配操作:
-
如果是增長操作,需要先通過記憶體重分配來擴展底層陣列,忘了這一步會產生緩沖區溢位
-
如果是縮短操作,需要先通過記憶體重分配來釋放不再使用的空間,忘 了這一步會產生記憶體泄漏
記憶體重分配是一個耗時的操作,如果每次修改字串都要進行記憶體重分配,在修改頻繁的情況下,會對性能造成影響,
SDS的空間預分配和惰性空間兩種優化策略:
-
空間預分配:每次修改并需要對SDS進行擴展時,除了分配修改所需要的空間,還需要分配額外未使用的空間
-
如果修改之后,SDS的長度小于1MB,將分配和len屬性同樣大小的未使用空間,這時buf實際長度等于len位元組+free位元組+1位元組
-
如果修改之后,SDS的長度大于等于1MB,將分配1MB未使用空間,buf實際長度等于lenMB+1MB+1位元組
通過空間預分配,可以減少連續執行字串增長操作所需的記憶體重分配次數,和C字串對比,將連續增長N次所需的記憶體重分配次數從必定的N次降低為最多N次
-
-
惰性空間釋放:優化縮短SDS操作,需要縮短SDS時,不是立即用記憶體重分配來回收縮短后多出來的位元組,而是使用free記錄這些位元組的數量,并等待將來使用,
通過惰性空間釋放,SDS避免了縮短字串所需的記憶體重分配操作,并為將來可能有的增長操作提供了優化
-
-
二進制安全
C字串除了字串末尾的空字符外,里面不能包含空字符,使得只能保存文本資料,不能保存圖片、音頻、視頻等二進制檔案,
SDS的buf屬性是保存二進制資料,SDS會以處理二進制的方式處理buf陣列,資料寫入時什么樣,讀出時就什么樣,
-
重用部分C字串函式
SDS遵循C字串以空字符結尾,可以讓保存文本資料的SDS重用一部分C字串函式,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/230969.html
標籤:其他
上一篇:MongoD Windows版本zip安裝(發生了SocketException: Error connecting to 127.0.0.1:27017錯誤,解決此問題的辦法)