SET 運算子
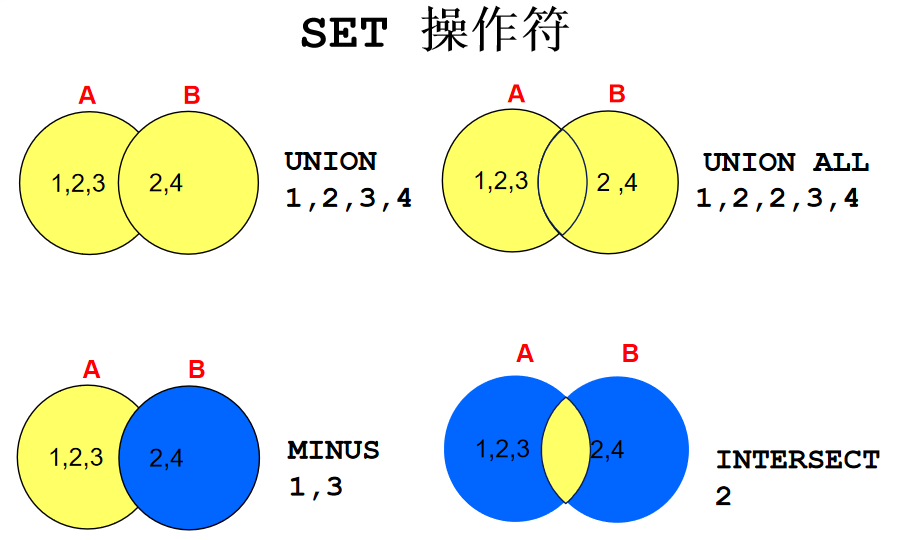
使用 SET 運算子注意事項
在SELECT 串列中的列名和運算式在**數量和資料型別**上要相對應
括號可以改變執行的順序
ORDER BY 子句:
只能在陳述句的最后出現
可以使用第一個查詢中的列名, 別名或相對位置
SELECT department_id, TO_NUMBER(null) location, hire_date FROM employees UNION SELECT department_id, location_id, TO_DATE(null) FROM departments;
SELECT employee_id, job_id,salary FROM employees UNION SELECT employee_id, job_id,0 FROM job_history;
使用相對位置排序舉例
COLUMN a_dummy NOPRINT SELECT 'sing' AS "My dream", 3 a_dummy FROM dual UNION SELECT 'I"d like to teach', 1 FROM dual UNION SELECT 'the world to', 2 FROM dual ORDER BY 2;
子查詢
單列子查詢
子查詢 (內查詢) 在主查詢之前一次執行完成, 子查詢的結果被主查詢(外查詢)使用 ,SELECT select_list FROM table WHERE expr operator (SELECT select_list FROM table);
多列子查詢
1. 多列子查詢
成對比較
問題:查詢與141號或174號員工的manager_id和department_id相同的其他員工的employee_id, manager_id, department_id
SELECT employee_id, manager_id, department_id FROM EMPLOYEES WHERE ( manager_id, department_id ) in ( SELECT manager_id, department_id FROM employees WHERE employee_id IN (141,174) ) and EMPLOYEE_ID not in (141,174)
不成對比較
SELECT employee_id, manager_id, department_id FROM employees WHERE manager_id IN ( SELECT manager_id FROM employees WHERE employee_id IN ( 174, 141 )) AND department_id IN ( SELECT department_id FROM employees WHERE employee_id IN ( 174, 141 )) AND employee_id NOT IN ( 174, 141 );
2. FROM 子句中使用子查詢
問題:回傳比本部門平均工資高的員工的last_name, department_id, salary及平均工資
方法一
select last_name,department_id,salary, (select avg(salary)from employees e3 where e1.department_id = e3.department_id group by department_id) avg_salary from employees e1 where salary > (select avg(salary) from employees e2 where e1.department_id = e2.department_id group by department_id )
方法二
SELECT a.last_name, a.salary, a.department_id, b.salavg FROM employees a, (SELECT department_id, AVG(salary) salavg FROM employees GROUP BY department_id) b WHERE a.department_id = b.department_id AND a.salary > b.salavg;
3. CASE 運算式中使用單列子查詢
問題:顯式員工的employee_id,last_name和location,其中,若員工department_id與location_id為1800的department_id相同,則location為’Canada’,其余則為’USA’,
SELECT employee_id, last_name, ( CASE WHEN department_id = ( SELECT department_id FROM departments WHERE location_id = 1800 ) THEN 'Canada' ELSE 'USA' END ) location FROM employees;
4. ORDER BY 子句中使用單列子查詢
問題:查詢員工的employee_id,last_name,要求按照員工的department_name排序
SELECT employee_id, last_name FROM employeese ORDER BY ( SELECT department_name FROM departments d WHERE e.department_id = d.department_id );
5. 相關子查詢
問題:查詢員工中工資大于本部門平均工資的員工的last_name,salary和其department_id

問題:若employees表中employee_id與job_history表中employee_id相同的數目不小于2,輸出這些相同id的員工的employee_id,last_name和其job_id
SELECT e.employee_id, last_name,e.job_id FROM employees e WHERE 2 <= (SELECT COUNT(*) FROM job_history WHERE employee_id = e.employee_id);
6. 相關更新
相關更新:使用相關子查詢依據一個表中的資料更新另一個表的資料



7. 相關洗掉
相關洗掉:使用相關子查詢依據一個表中的資料洗掉另一個表的資料

問題:洗掉表employees中,其與emp_history表皆有的資料
DELETE FROM employees E WHERE employee_id = (SELECT employee_id FROM emp_history WHERE employee_id = E.employee_id);
EXISTS /NOT EXISTS 運算子
問題:查詢公司管理者的employee_id,last_name,job_id,department_id資訊
SELECT employee_id, last_name, job_id, department_id FROM employees outer WHERE EXISTS ( SELECT 'X' FROM employees WHERE manager_id = outer.employee_id);
問題:查詢departments表中,不存在于employees表中的部門的department_id和department_name
SELECT department_id, department_name FROM departments d WHERE NOT EXISTS (SELECT 'X' FROM employees WHERE department_id = d.department_id);
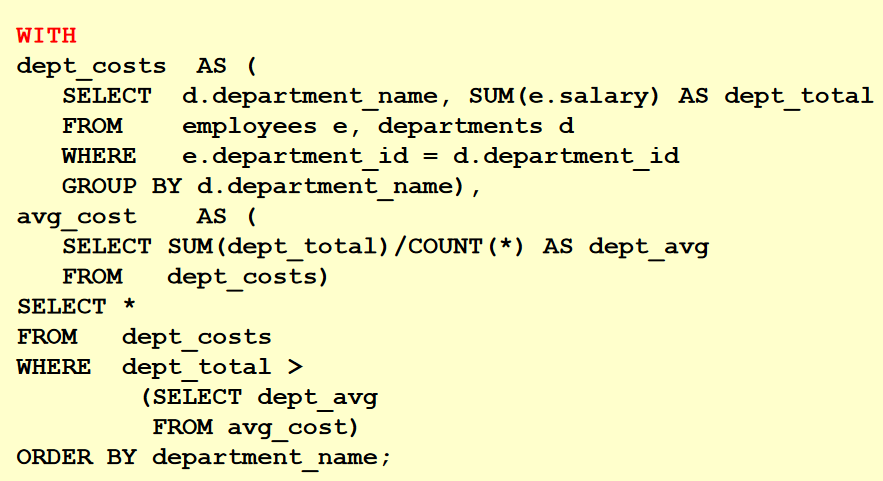
WITH 子句
1. 使用 WITH 子句, 可以避免在 SELECT 陳述句中重復書寫相同的陳述句塊
2. WITH 子句將該子句中的陳述句塊執行一次并存盤到用戶的臨時表空間中
3. 使用 WITH 子句可以提高查詢效率
問題:查詢公司中各部門的總工資大于公司中各部門的平均總工資的部門資訊
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/232994.html
標籤:Oracle
上一篇:oracle存盤程序轉達夢8存盤程序時踩過的坑2(完結篇)
下一篇:只需三步!慢日志去無蹤