目錄
- 一、簡介
- 1.1 什么是Elasticsearch?
- 1.2 Elasticsearch 的用途
- 1.3 Elasticsearch 的作業原理
- 1.4 Elasticsearch 索引是什么?
- 二、 基本概念
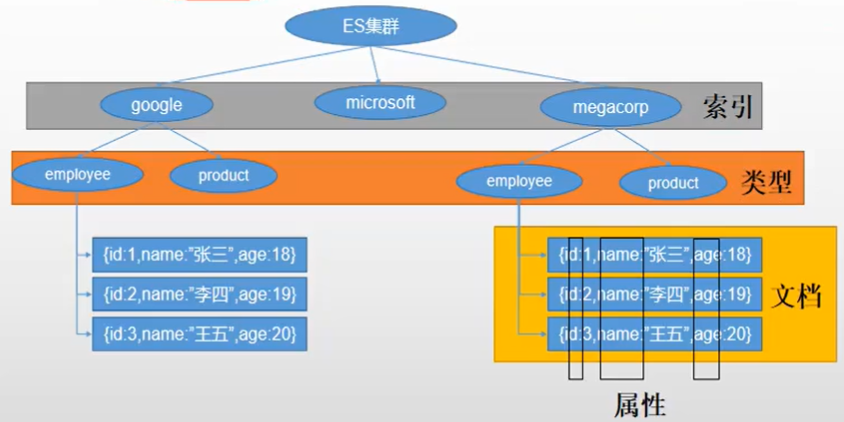
- 2.1 Index(索引)
- 2.2 Type(型別)
- 2.3 Document (檔案)
- 三、在Docker環境中安裝 ES + Kibana
- 3.1 下載鏡像
- 3.2 創建實體
- 3.2.1 elasticsearch
- 3.2.2 kibana
- 四、初步檢索
- 4.1 _cat
- 4.1.1 查看節點資訊
- 4.1.2 查看健康狀況
- 4.1.3 查看主節點資訊
- 4.1.3 查看所有的索引
- 4.2 索引一個檔案
- 4.2.1 put帶ID保存
- 4.2.2 POST保存
- 4.3 查詢檔案
- 4.4 更新檔案
- 4.1 POST 帶 _update 更新
- 4.2 其他更新
- 4.5 洗掉檔案&索引
- 4.6 bulk 批量 API
- 4.1 _cat
一、簡介
1.1 什么是Elasticsearch?
Elasticsearch是一個分布式的開源搜索和分析引擎, 適用于所有型別的資料,包括文本、數字、地理空間、結構化和啡結構化資料,Elasticsearch 在Apache Lucene的基礎上開發而成,由Elasticsearch N.V. (即現在的Elastic)于2010年首次發布,Elasticsearch 以其簡單的REST風格API、分布式特性、速度和可擴展性而聞名,是Elastic Stack的核心組件: Elastic Stack是適用于資料采集、充實、存盤、分析和可視化的一組開源工具,人們通常將Elastic Stack稱為ELK Stack (代指Elasticsearch、Logstash和Kibana),目前Elastic Stack包括一系列豐富的輕星型資料采集代理, 這些代理統稱為Beats,可用來向Elasticsearch發送資料,
1.2 Elasticsearch 的用途
Elasticsearch在速度和可擴展性方面表現出色,能夠索引多種型別的內容,意味著可以用于多種用例:
- 應用程式搜索
- 網站搜索
- 企業搜索
- 日志處理分析
- 基礎設施指標和容器檢測
- 應用程式性能檢測
- 地理空間資料分析和可視化
- 安全分析
- 業務分析
1.3 Elasticsearch 的作業原理
原始資料會從多個來源(包括日志、系統指標和網路應用程式)輸入到 Elasticsearch 中,資料采集指在Elasticsearch中進行索引之前決議、標準化并充實這些原始資料的程序,這些資料在 Elasticsearch 中索引完成之后,用戶便可針對他們的資料運行復雜的查詢,并使用聚合來檢索自身資料的復雜匯總,在 Kibana 中,用戶可以基于自己的資料創建強大的可視化,分享儀表板,并對 Elastic Stack 進行管理,
1.4 Elasticsearch 索引是什么?
Elasticsearch 索引指相互關聯的檔案集合,Elasticsearch 會以 JSON 檔案的形式存盤資料,每個檔案都會在一組鍵(欄位或屬性的名稱)和它們對應的值(字串、數字、布林值、日期、數值組、地理位置或其他型別的資料)之間建立聯系,
Elasticsearch 使用的是一種名為倒排索引的資料結構,這一結構的設計可以允許十分快速地進行全文本搜索,倒排索引會列出在所有檔案中出現的每個特有詞匯,并且可以找到包含每個詞匯的全部檔案,
在索引程序中,Elasticsearch 會存盤檔案并構建倒排索引,這樣用戶便可以近實時地對檔案資料進行搜索,索引程序是在索引 API 中啟動的,通過此 API 您既可向特定索引中添加 JSON 檔案,也可更改特定索引中的 JSON 檔案,
二、 基本概念
2.1 Index(索引)
動詞: 相當于 MySQL 中的 insert
名詞: 相當于 MySQL 中的 Database
2.2 Type(型別)
在 index (索引) 中,可以定義一個或多個型別,類似于 MySQL 中的 Table ,每一種型別的資料放在一起
把一條資料存在 ES 的某個索引的某個型別下,相當于 MySQL 的某個資料庫的某張表下
2.3 Document (檔案)
保存在某個 索引(資料庫)下, 某種 型別(表) 的一個 Document 檔案(一條資料), 檔案是 JSON格式的,Document 就像是 MySQL 中的某個 Table 里面的內容,
三、在Docker環境中安裝 ES + Kibana
3.1 下載鏡像
docker pull elasticsearch:7.4.2
docker pull kibana:7.4.2

3.2 創建實體
3.2.1 elasticsearch
先在本機中創建一個自己的目錄 , 如:/mydata/elasticsearch , 然后再目錄底下創建三個檔案夾 data 、 config 和plugins,為后面創建elasticsearch實體時,可以做一個檔案映射,便于我們對 es 實體進行修改,
同時,在 config 檔案夾里,新建 elasticsearch.yml 組態檔,并配置 es 可以被遠程的任何機器進行訪問
mkdir -p /mydata/elasticsearch/data
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/plugins
echo "http.host:0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml
啟動 elasticsearch 實體
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx256m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
-e "discovery.type=single-node" : 設定 es 為單節點運行
-e ES_JAVA_OPTS="-Xms64m -Xmx256m": 設定 es 的最小記憶體使用 64M ,最大記憶體使用為 256 M

啟動成功后,訪問 http://主機IP:9200 ,能看到如下資訊,即為創建成功
注: 如果啟動失敗,可以通過命令 docker logs elasticsearch 查看啟動日志,可能出現的錯誤:
1、沒有權限訪問,因為我們啟動的命令掛載到了外面, 所以可能存在無法訪問的寫入的權限
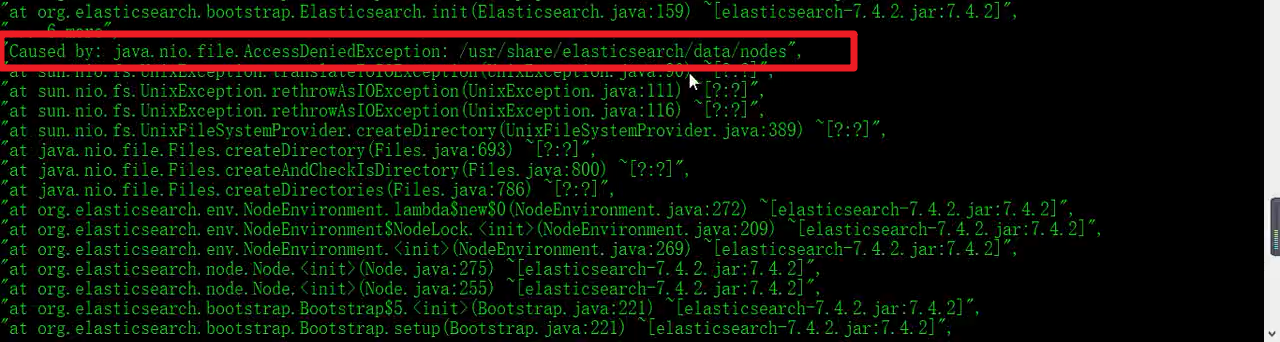
解決方案: 使用命令 chmod -R 777 /mydata/elasticsearch 給任何用戶任何組所有權限,重啟es實體即可,
3.2.2 kibana
kibana只需要創建實體,關聯我們剛剛的es即可
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://主機IP:9200 \
-p 5601:5601 -d kibana:7.4.2
上面的命令是根據官方檔案查看而來的,不過這條命令在虛擬機中好像無法啟動(我本地 [vmware 15.6 + centos7] 的環境下,一直無法啟動成功,連接失敗),而在阿里云ESC服務器上,可以成功啟動,遇到上訴的情況,可以通過下面這條命令查看 es 實際暴露的 ip,把上面的主機 IP 修改為對應的 ip 即可
//007e為elasticsearch的id
docker inspect 007e 或者 docker inspect elasticsearch

則,kibana 創建的示例的命令為
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://172.17.0.3:9200 \
-p 5601:5601 -d kibana:7.4.2
由于我們剛剛在執行前一個命令的時候,已經創建了一個名為 kibana 的實體,所以需要先洗掉后,在執行上一步的命令
// 查看所有運行中的實體
docker ps
// 查看所有的實體
docker ps -a
// 洗掉 kibana 的實體
docker rm kibana
訪問 http://主機ip:5601 ,看到如下頁面即為創建成功
可使用下面的兩個命令,使得我們主機重啟后,實體也會自動啟動
docker update --restart=always elasticsearch docker update --restart=always kibana
四、初步檢索
4.1 _cat
4.1.1 查看節點資訊
GET http://主機ip:9200/_cat/nodes

4.1.2 查看健康狀況
GET http://主機ip:9200/_cat/health
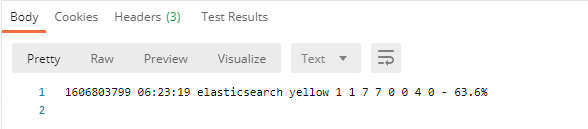
4.1.3 查看主節點資訊
GET http://主機ip:9200/_cat/master

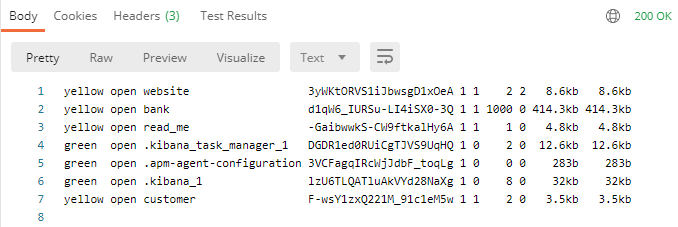
4.1.3 查看所有的索引
GET:http://主機ip:9200/_cat/indices
4.2 索引一個檔案
MySQL:保存一條資料到表中
保存一個資料,保存在哪個索引的哪個型別下, 可以指定唯一標識
MySQL: 保存在哪個資料庫的哪張表下
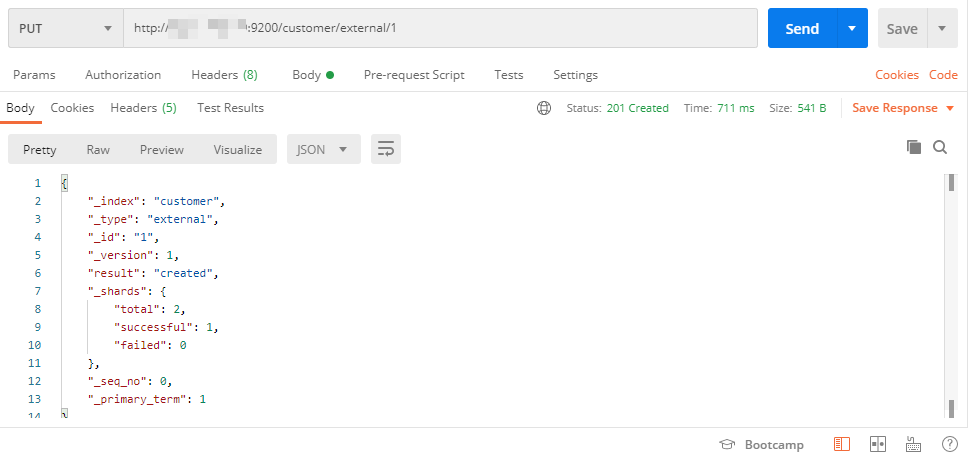
4.2.1 put帶ID保存
新增更新二合一,第一次發送為新增,后面的則為更新,不指定id會報錯,一般用做于修改
PUT /customer/external/1
{
"name": "John Doe"
}
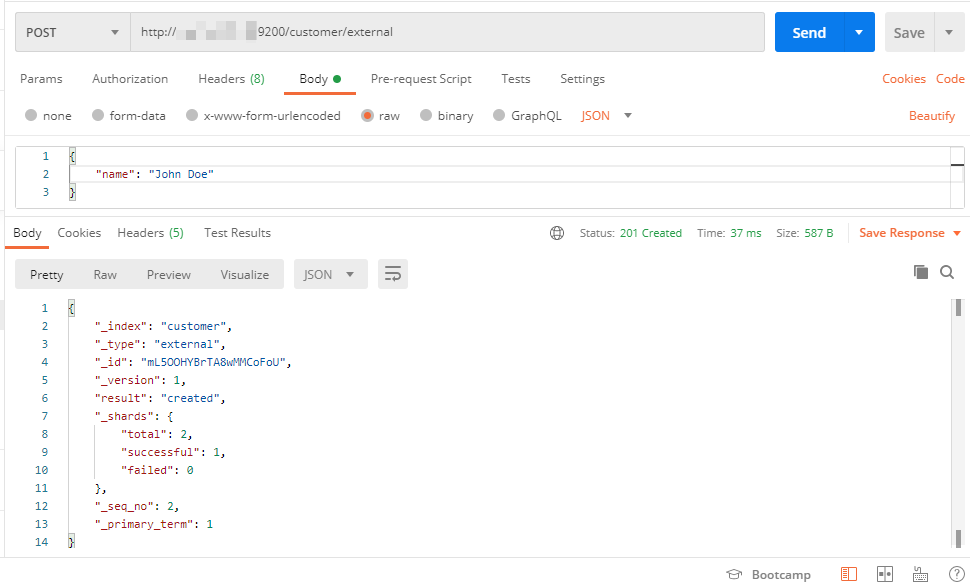
4.2.2 POST保存
新增修改二合一,不帶ID或者帶ID但是之前沒有資料為新增,帶ID且之前有資料,為修改
PUT /customer/external/
{
"name": "John Doe"
}
4.3 查詢檔案
查詢 哪個索引 下的 哪個型別 下的 哪條資料
MySQL: 查詢哪個資料庫下的哪張表的哪條資料
GET /customer/external/1
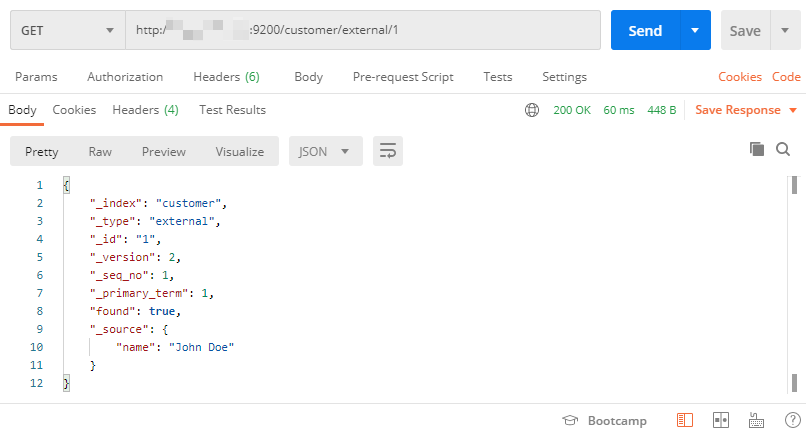
_seq_no:并發控制欄位,每次更新就會 +1 ,可以用來做樂觀鎖
_primary_term:可用于做樂觀鎖,主分片重新分配,如重啟,就會變化
樂觀鎖使用:
更新前,先查詢出當前的資料,可以獲取當前 _seq_no以及當前 _primary_term
更新的時候,帶上?if_seq_no={當前 _seq_no }&if_primary_term={當前 _primary_term}
4.4 更新檔案
4.1 POST 帶 _update 更新
POST /customer/external/1/_update
{
# doc 的內容為檔案的最新值
"doc": {
"name": "John Doew"
}
}
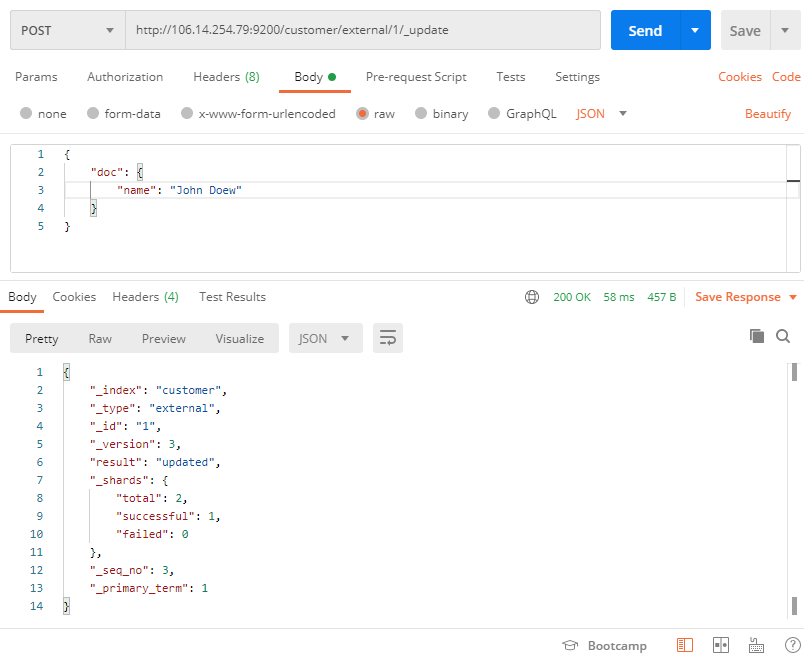
POST 帶 _update 更新, 會對比原資料,如果更新的資料與原來一致,則
_version、_seq_no不會變化, 且result的值為noop,意思為沒有做任何操作,且可以給原有的檔案中,新增一個屬性{ # 帶 _update doc不可省略, doc 的內容為檔案的最新值 "doc": { "name": "John Doew", "age": 20 } }如上的請求也是可以成功的
4.2 其他更新
POST /customer/external/1
{
"name": "John Doew"
}
PUT /customer/external/1
{
"name": "John Doew"
}
以上兩種方式的更新,永遠為更新操作,不會對比原來的操作,每次請求 _version 、 _seq_no都在不斷疊加,且同 帶 _updte 的 POST 請求一樣,可以為原有檔案新增上新的屬性
4.5 洗掉檔案&索引
發送 DELETE 請求, 需要指定到具體的檔案、索引
DELETE /customer/external/1
DELETE /customer
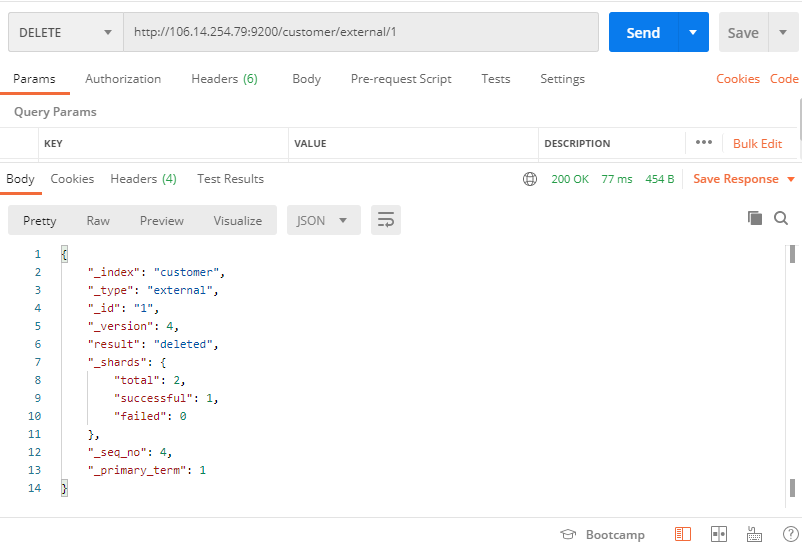
在 ElasticSearch 中, 不提供洗掉型別的方法
4.6 bulk 批量 API
必須發送 POST 請求,在 PostMan 中無法模擬請求,這里需要用到 kibana
POST /customer/external/_bulk 在 customer 索引下的 external 型別中批量執行
# 一個大括號代表一個操作,兩行為一個動作
{"index":{"_id": "1"}} # 索引一個檔案,檔案的id為1
{"name": "John Doe"} # 檔案的內容
{"index":{"_id": "2"}}
{"name": "John Doe"}
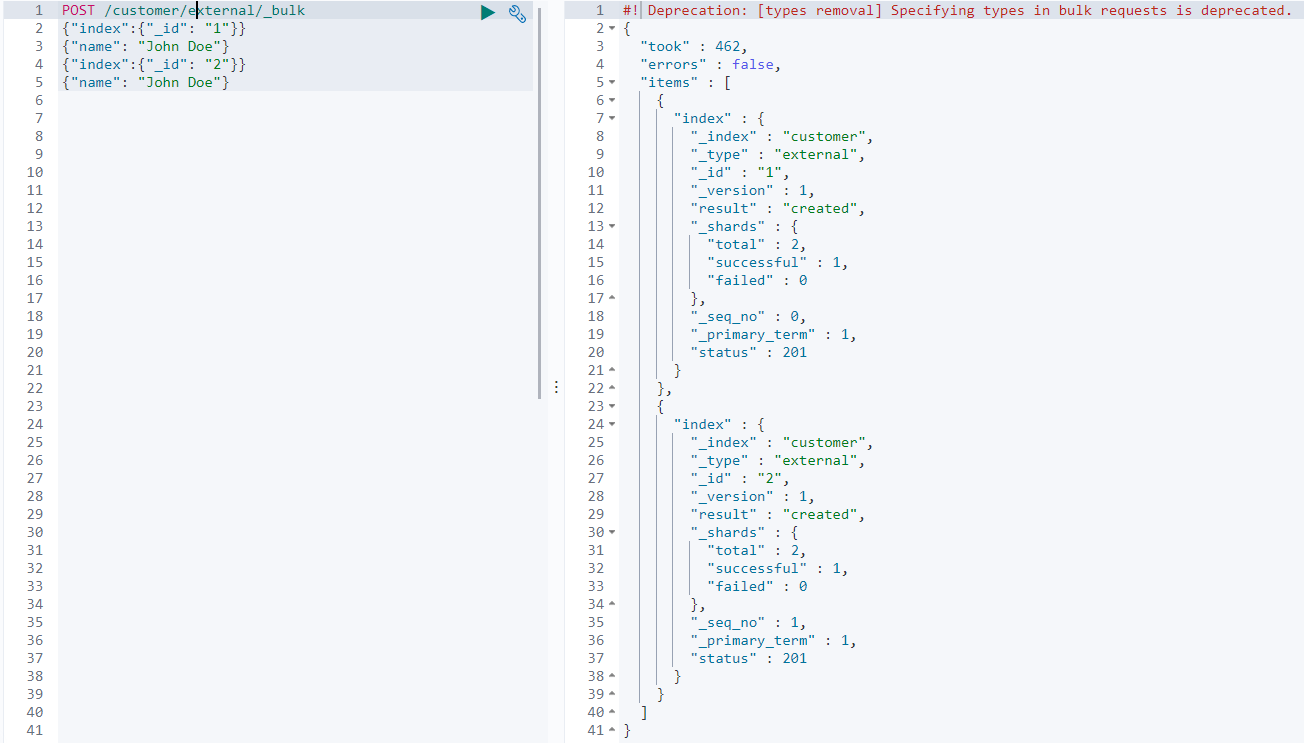
took :執行所花費的時間 errors : 是否有錯誤
items :獨立統計每條命令的執行結果,如果中間有某條命令執行失敗,后面的命令也不會受到影響,且命令執行失敗的時候,不會跟MySQL一樣,回滾
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/234191.html
標籤:NoSQL