作者的原文地址如下:
https://mp.weixin.qq.com/s?__biz=MzI4NTA1MDEwNg==&mid=2650769273&idx=1&sn=195b25c91f476aba7b7c6cbf1c902f2e&chksm=f3f932ecc48ebbfa7cf8742ede5956c19ab5ca0bad839fd00c4fcf73de3abf6bd8c7d2eb437b&scene=0#rd
參考了作者文中的一些圖片,著作權歸作者所有,
從互聯網上下載參考的圖片,也歸原作者所有,
1. 文章闡述的傳統 BI 架構,偏重于 Cube 的實作,
個人認為比較片面,作者所用圖例和資料倉庫圣經《Dimensional Modeling 》即中文版的《維度建模》相差太大,資料加載和資料轉換放在同一層,和 ETL 有些違和,ETL 的步驟是 Extract, Transform, Load, 所以放在同一層來講,不能很好的體現先后順序,容易讓剛開始實施資料倉庫建設的讀者引起迷糊,先轉換后裝載,或許之后還有第二層轉換,第三層轉換,這些步驟其實應該是作為交叉回圈進行的,
以下是作者的原圖:
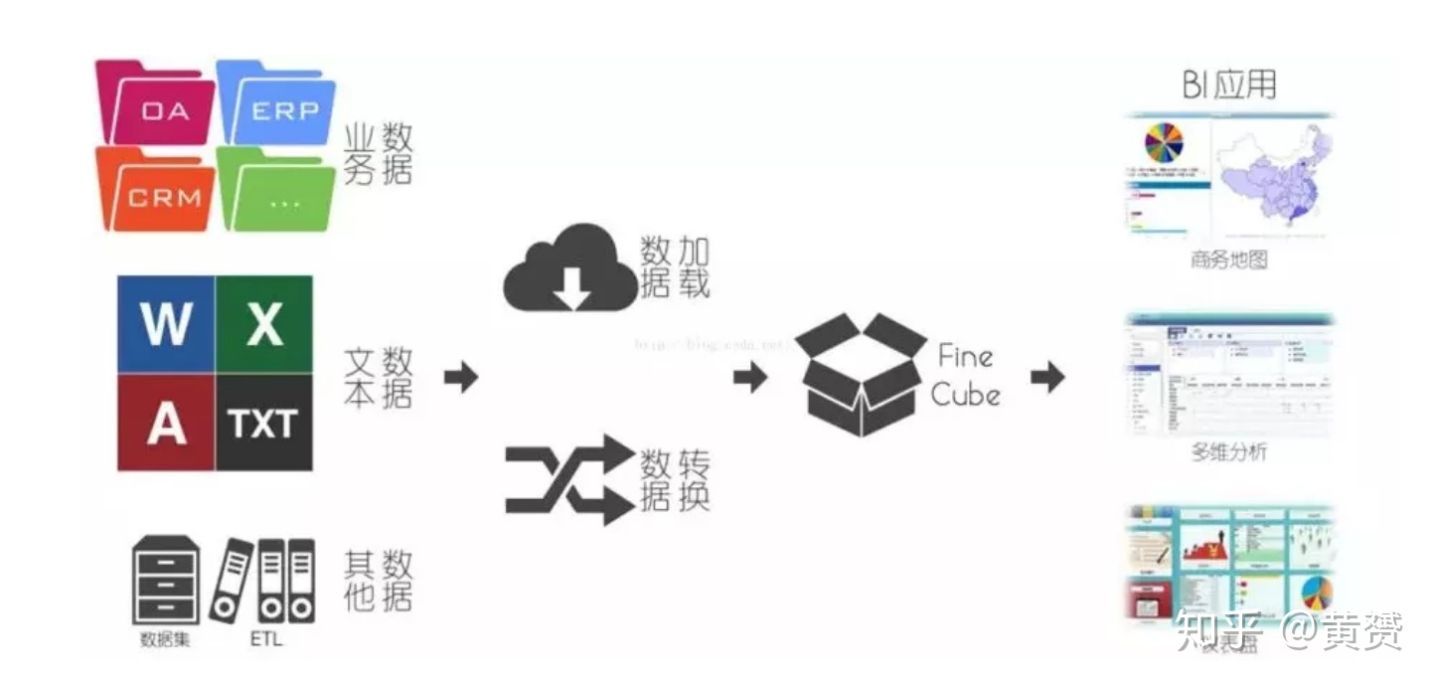
資料倉庫分兩種大架構, Inmon 的資料集市和 Kimball 提倡的集中式資料倉庫,資料集市是將資料分為各類主題,回流到各個業務部門,以提供資訊檢索,集中式資料倉庫則是將所有主題融合到一起,做出更多聯合性的分析,而在這前,通過資料操作層(OPDS)已經采用雪花模型將各個業務系統資料加載到緩沖層,業務系統可以在這里采集到聚合資訊,
作者的原圖沒有充分體現出 kimball 和 Inmon 兩大資料倉庫的特征,所以我重新在網上找了個圖,方便理解,其實 Cube 只是一種 MOLAP 的實作,屬于資料倉庫的一部分,
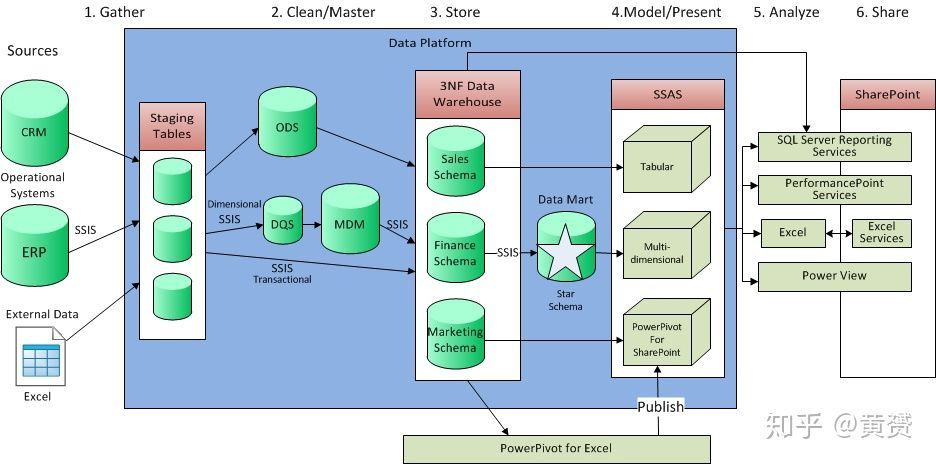
2. 以 Hadoop 為首的大資料平臺來替換傳統資料倉庫平臺
簡要的說下分布式計算平臺比傳統構建在商業資料庫平臺上的資料倉庫的優勢:
2.1 分布式計算:通過將資料計算分配到離資料最近的存盤節點上,使得并行計算成為可能,
2.2 分布式存盤:將大份資料,拆解為小份資料并分散存盤到不同的存盤節點,提供分布式計算的前提條件
2.3 資料路由:磁區分庫分表等分布式存盤操作之后,記錄這些結構資訊,并做高可用管理,提供給應用程式的是路由功能,使得應用系統進來的查詢請求得以分配到合理的資料節點上計算,
而這一切在 oracle, sql server, mysql, postgresql 上是很難快速得以部署的,小規模 5-10 臺還能接受,100臺以上集群,管理難度和成本會急劇加速,
我認為構建在商業資料庫平臺上的資料倉庫其實沒有必要重新推翻,用 Hadoop 來重新做一遍,這一點和作者想法不一致,
a) 資料倉庫完全可以做為資料源再丟到分布式系統中做計算
b) 分布式系統作為資料倉庫的計算引擎,提供算力即可,
c) 分布式系統將聚合資料/快速計算能力回流給資料倉庫
e) 根據需求再將其他主題相關建模以及計算,構建到新的分布式系統中
3. 以 Hadoop 為基礎的大資料架構
3.1 傳統大資料架構
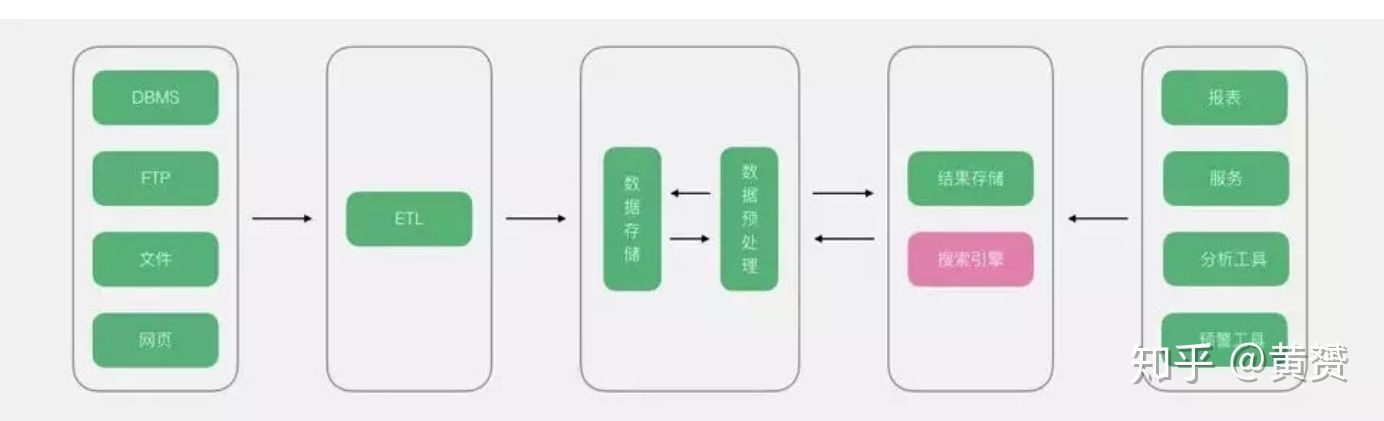
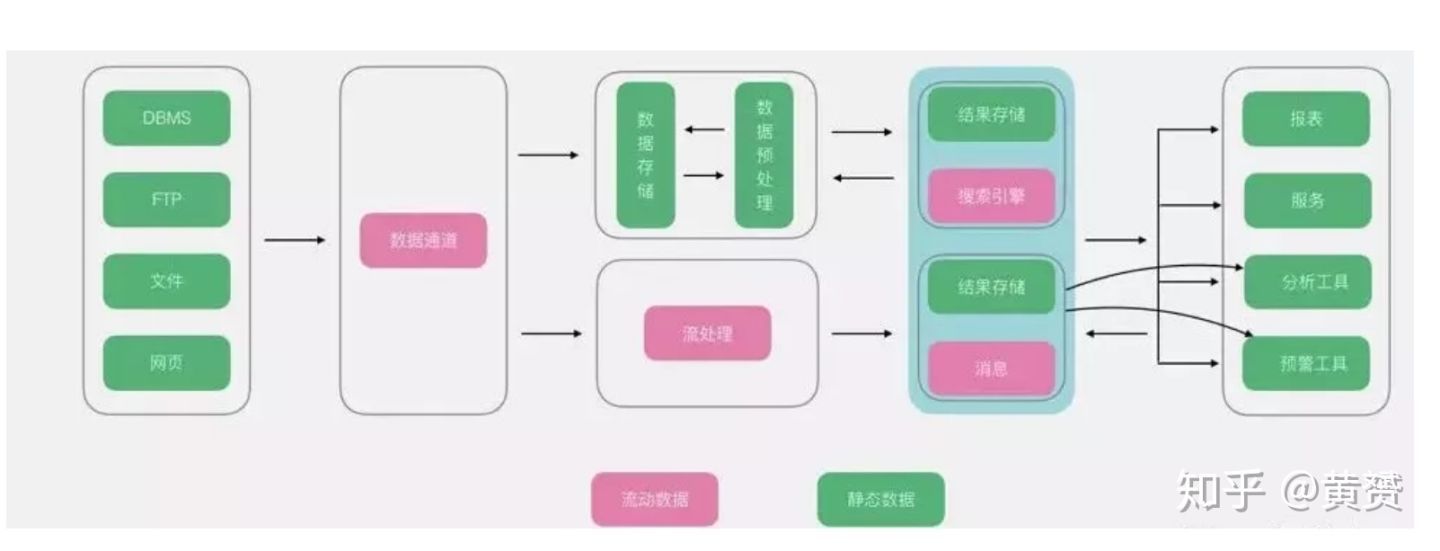
借用作者的圖,我們可以用 資料倉庫 + hadoop 分布式 實作 結果存盤+搜索引擎,資料倉庫和hadoop分布式之間用 sqoop 來做傳輸的通道,實作分布式算力的回流,而展現分析作業等依舊可以選擇鏈接 資料倉庫,一些即席分析(Ad Hoc Query) 需要大量的計算,那么可以直接鏈接 Hadoop 分布式系統
3.2 流式架構
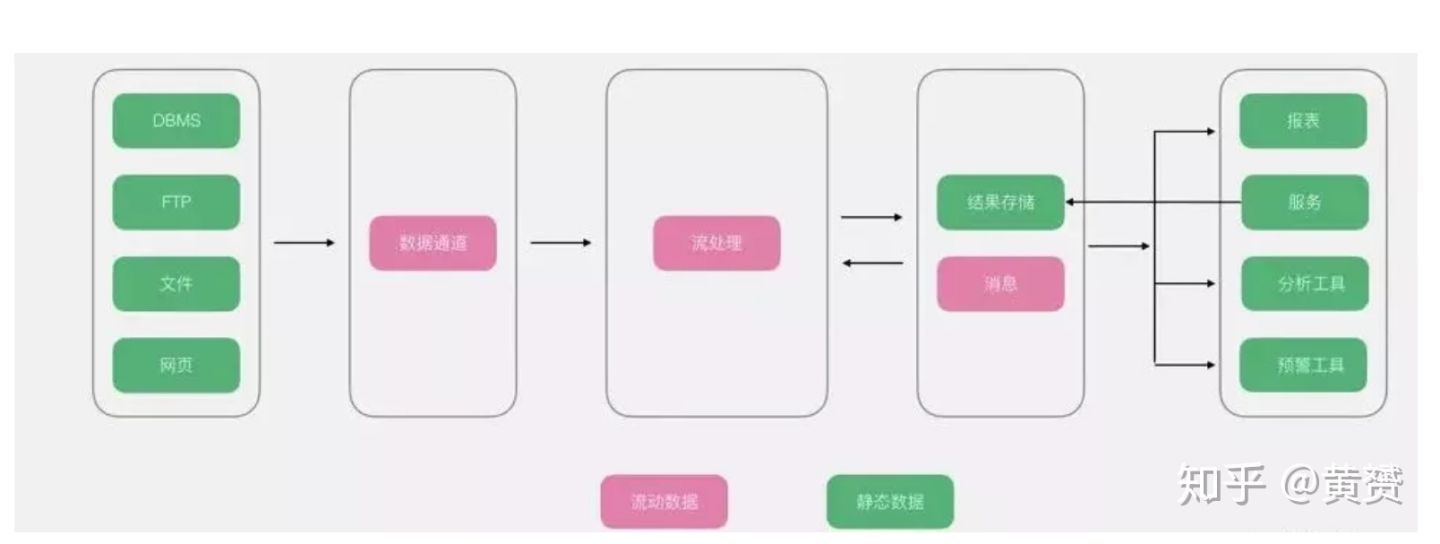
在原文中,作者是這樣描述的:
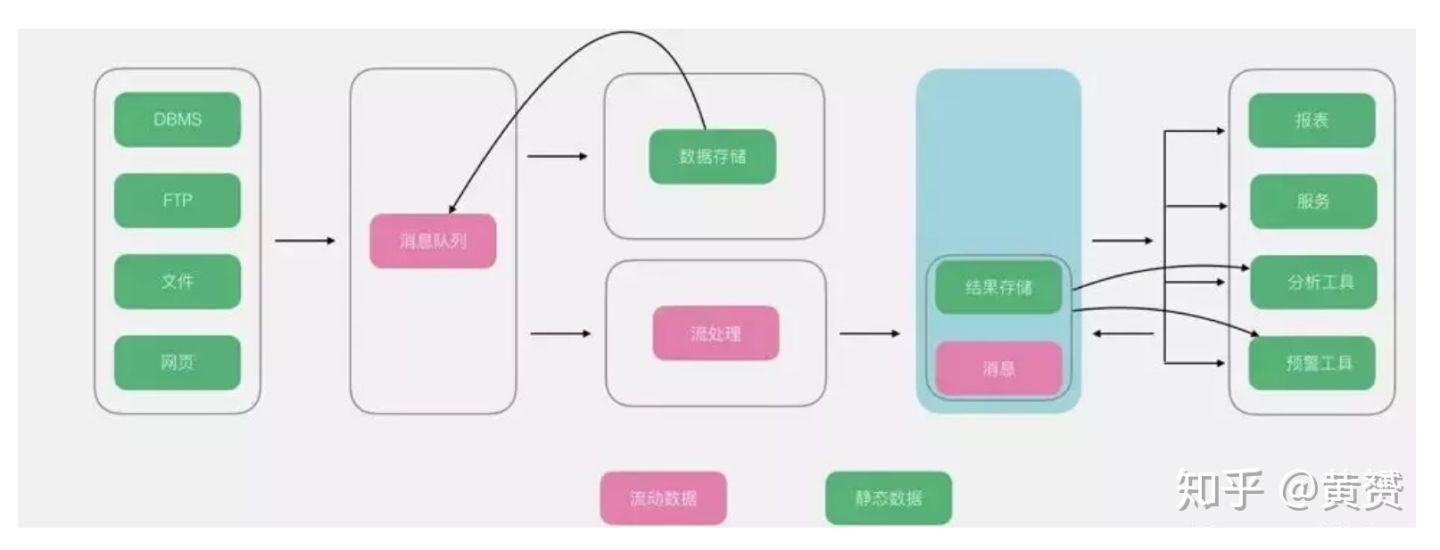
在傳統大資料架構的基礎上,流式架構非常激進,直接拔掉了批處理,資料全程以流的形式處理,所以在資料接入端沒有了ETL,轉而替換為資料通道,經過流處理加工后的資料,以訊息的形式直接推送給了消費者,雖然有一個存盤部分,但是該存盤更多以視窗的形式進行存盤,所以該存盤并非發生在資料湖,而是在外圍系統,
這里有“資料湖”(Data Lake)的概念,稍微介紹下:
A data lake is a system or repository of data stored in its natural format,usually object blobs or files. A data lake is usually a single store of all enterprise data including raw copies of source system data and transformed data used for tasks such as reporting, visualization, analytics and machine learning. A data lake can include structured data from relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails, documents, PDFs) and binary data (images, audio, video).
節選自維基百科 https://en.wikipedia.org/wiki/Data_lake
通常存盤原始格式資料,比如 blob 物件或檔案的系統,被稱為資料湖(Data Lake). 在這套系統里面,存盤了所有企業的資料,不僅僅是原始應用系統資料,還包括了用于報表,可視化分析和機器學習的轉化過后的資料,因此,它包含了各種資料格式,有關系型資料庫的結構化資料,有半結構化資料(比如 CSV, log, XML ,Json),還有非結構化資料(email, document, PDF )和二進制資料(圖片,音頻和視頻),
原文中作者對訊息的存盤,并沒有給出一個合理的解釋,并將訊息和資料湖區分開來,我認為是不妥的,從維基百科來的解釋,一切的資料存盤都是歸檔在資料湖里的,至少訊息我認為也應該算是資料湖的一部分,
3.3 Lambda 架構
上面的圖很難理解,而且對 Lambda Architecture 的三要素也沒有很好的展示,所以有必要解釋下 Lambda 的要素以及貼一下公認的 Lambda 架構圖
維基百科是這么定義 Lambda 架構的:
Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation. The rise of lambda architecture is correlated with the growth of big data, real-time analytics, and the drive to mitigate the latencies of map-reduce.
Lambda architecture depends on a data model with an append-only, immutable data source that serves as a system of record. It is intended for ingesting and processing timestamped events that are appended to existing events rather than overwriting them. State is determined from the natural time-based ordering of the data.
Lambda 是充分利用了 批次(batch) 處理和 流處理(stream-processing)各自強項的資料處理架構,它平衡了延遲,吞吐量和容錯,利用批次處理生成正確且深度聚合的資料視圖,同時借助流式處理方法提供在線資料分析,在展現資料之前,可以將兩者結果融合在一起,Lambda 的出現,與大資料,實時資料分析以及map-reduce 低延遲的推動是密不可分的,
Lambda 依賴于只增不改的資料源,歷史資料在這個模型中,就是穩定不變的歷史資料,變化著的資料永遠是最新進來的,并且不會重寫歷史資料,任何事件,物件等的狀態和屬性,都需要從有序的實踐中推斷出來,
因此在這套架構中,我們可以看到即時的資料,也可以看到歷史的聚合資料,
維基百科中對 Lambda 經典的三大元素做了描述:
Lambda architecture describes a system consisting of three layers: batch processing, speed (or real-time) processing, and a serving layer for responding to queries.[3]:13 The processing layers ingest from an immutable master copy of the entire data set.
Lambda 包含了三層:批次處理(batch), 高速處理也稱為實時處理(speed or real-time),和回應查詢的服務層(serving).
《主流大資料架構》中有一點特別之處在于,他將資料源描述的特別豐富,所以即使用傳統的商業資料庫也是可以實作 Lambda 架構的,Batch 用商業用的 ETL 工具,比如 SSIS, Informatic 等, Stream-Processing 用 Message Broker ,比如 RabbitMQ, ActiveMQ等,
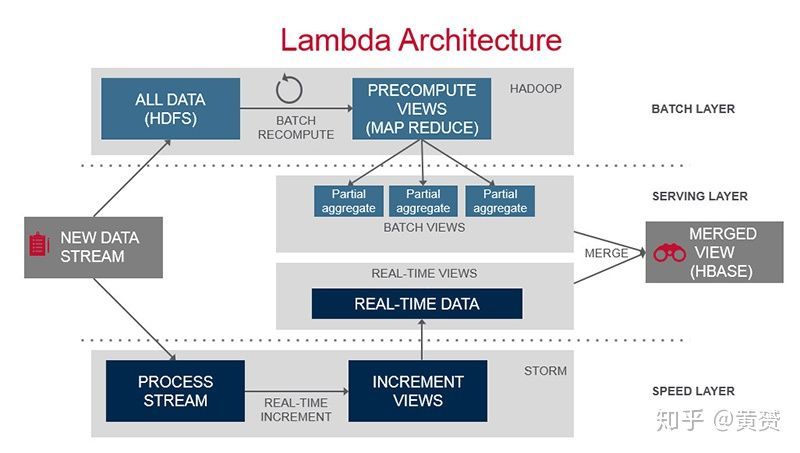
但維基百科上可不是這么認為的,以 Hadoop 為代表的分布式系統,才有資格稱得上是 Lambda 架構的組成,從它對三個元素的定義就可以看的出來:
Batch layer
The batch layer precomputes results using a distributed processing system that can handle very large quantities of data. The batch layer aims at perfect accuracy by being able to process all available data when generating views. This means it can fix any errors by recomputing based on the complete data set, then updating existing views. Output is typically stored in a read-only database, with updates completely replacing existing precomputed views.
Apache Hadoop is the de facto standard batch-processing system used in most high-throughput architectures
批次處理層,利用分布式系統的強大處理能力,提供了可靠準確無誤的資料視圖,一旦發現錯誤的資料,即可重新計算全部的資料來獲得最新的結果,Hadoop 被視為這類高吞吐架構的標準,
Speed layer
The speed layer processes data streams in real time and without the requirements of fix-ups or completeness. This layer sacrifices throughput as it aims to minimize latency by providing real-time views into the most recent data. Essentially, the speed layer is responsible for filling the "gap" caused by the batch layer's lag in providing views based on the most recent data. This layer's views may not be as accurate or complete as the ones eventually produced by the batch layer, but they are available almost immediately after data is received, and can be replaced when the batch layer's views for the same data become available.
Stream-processing technologies typically used in this layer include Apache Storm, SQLstream and Apache Spark. Output is typically stored on fast NoSQL databases
高速處理層,用實時計算的手段,將資料集成到存盤端,這部分處理雖然沒有最終的批次處理來的完整和精確,但彌補了批次處理的時效差的弱點,
通常使用 Apache Storm, SQLStream, Apache Spark 等,輸出一般是到NoSQL 資料庫
Serving layer
Output from the batch and speed layers are stored in the serving layer, which responds to ad-hoc queries by returning precomputed views or building views from the processed data.
Examples of technologies used in the serving layer include Druid, which provides a single cluster to handle output from both layers. Dedicated stores used in the serving layer include Apache Cassandra, Apache HBase, MongoDB, VoltDB or Elasticsearch for speed-layer output, and Elephant DB, Apache Impala or Apache Hive for batch-layer output.
這一層主要服務于終端資料消費者的即席查詢和分析,當最終計算結果存盤到本層的時候,就可以對外服務了,對于高速處理層來的結果,可以交由 Apache Cassandra, HBase, MongoDB, ElasticSearch 存盤;對于批次處理層來的結果,可以交由 Apache Impala, Hive 存盤,
ElasticSearch 提供全文索引, Impala 就是類似于 Cube 做分析應用的專案,因此《主流大資料架構》中提到 Cube 為數倉中心,其實不是很妥,依我看,更應該是各種資料衍生系統的大綜合,既有傳統意義上的資料倉庫(Dimension/Fact), 更要有全文索引,OLAP 應用等,
Lambda架構的一些應用:
Metamarkets, which provides analytics for companies in the programmatic advertising space, employs a version of the lambda architecture that uses Druid for storing and serving both the streamed and batch-processed data.
For running analytics on its advertising data warehouse, Yahoo has taken a similar approach, also using Apache Storm, Apache Hadoop, and Druid.
The Netflix Suro project has separate processing paths for data, but does not strictly follow lambda architecture since the paths may be intended to serve different purposes and not necessarily to provide the same type of views.https://en.wikipedia.org/wiki/Lambda_architecture#cite_note-netflix-10 Nevertheless, the overall idea is to make selected real-time event data available to queries with very low latency, while the entire data set is also processed via a batch pipeline. The latter is intended for applications that are less sensitive to latency and require a map-reduce type of processing.
Metamarkets, 一家從事計算廣告的公司,利用 Druid 列式存盤技術搭建了 Lambda 架構,同時支持資料的批次處理與實時處理
Yahoo 利用了相同技術堆疊, Storm, Hadoop, Druid 搭建了 Lambda
Netflix Suro 專案隔離了離線資料與在線資料的處理路徑,延遲要求不高的資料依然采用了 map-reduce 的處理型別,雖然沒有嚴格遵循 Lambda ,但本質上無異,
3.4 Kappa 架構
我在網上看到和作者差不多的圖,我覺得兩者都沒有將 Stream, Serving 層畫出來,而且對 messaging 到 Raw Data Reserved 沒有特別指出其資料流程序,很是費解,
我只能將他當成是訊息佇列的一個目標庫而已,
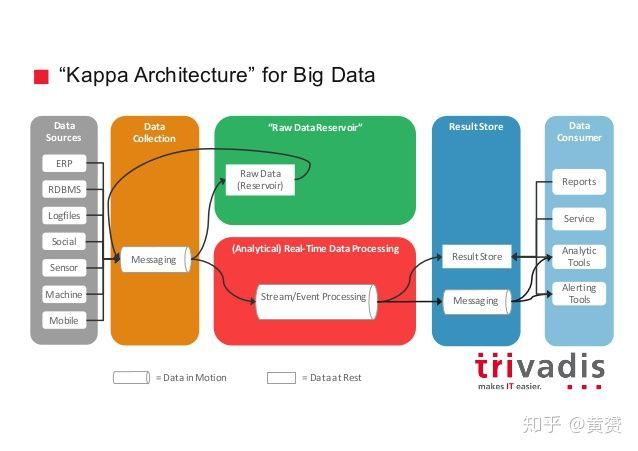
所有資料都走實時路線,一切都是流,并且以資料湖作為最終存盤目的地,事實上還是以 lambda為基礎,只是將批次處理層(Batch Layer ) 去掉,剩下 Streaming, Serving 層,
結合上面兩圖,再看下圖,可能會更清晰一些,
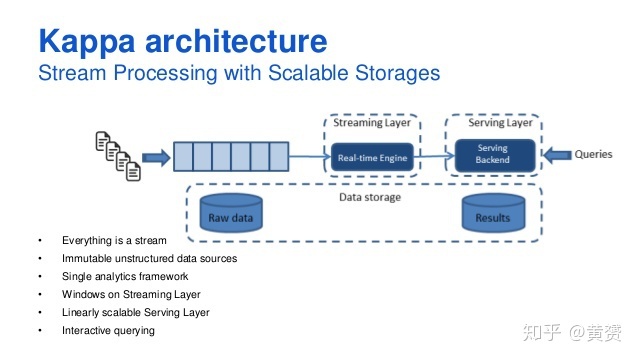
以下引自 https://towardsdatascience.com/a-brief-introduction-to-two-data-processing-architectures-lambda-and-kappa-for-big-data-4f35c28005bb
Some variants of social network applications, devices connected to a cloud based monitoring system, Internet of things (IoT) use an optimized version of Lambda architecture which mainly uses the services of speed layer combined with streaming layer to process the data over the data lake.
Kappa architecture can be deployed for those data processing enterprise models where:
Multiple data events or queries are logged in a queue to be catered against a distributed file system storage or history.
The order of the events and queries is not predetermined. Stream processing platforms can interact with database at any time.
It is resilient and highly available as handling Terabytes of storage is required for each node of the system to support replication.
The above mentioned data scenarios are handled by exhausting Apache Kafka which is extremely fast, fault tolerant and horizontally scalable. It allows a better mechanism for governing the data-streams. A balanced control on the stream processors and databases makes it possible for the applications to perform as per expectations. Kafka retains the ordered data for longer durations and caters the analogous queries by linking them to the appropriate position of the retained log. LinkedIn and some other applications use this flavor of big data processing and reap the benefit of retaining large amount of data to cater those queries that are mere replica of each other.
物聯網 (Internet of Things IoT) 對這種架構是毫無抵抗力的,因為闖紅燈這件事,事后去分析或者告警,已經沒有太大意義了,
Kafka 在這其中扮演了實時分發資料的角色,它的快速,容錯和水平擴展能力都表現非常出色,
3.5 Unifield
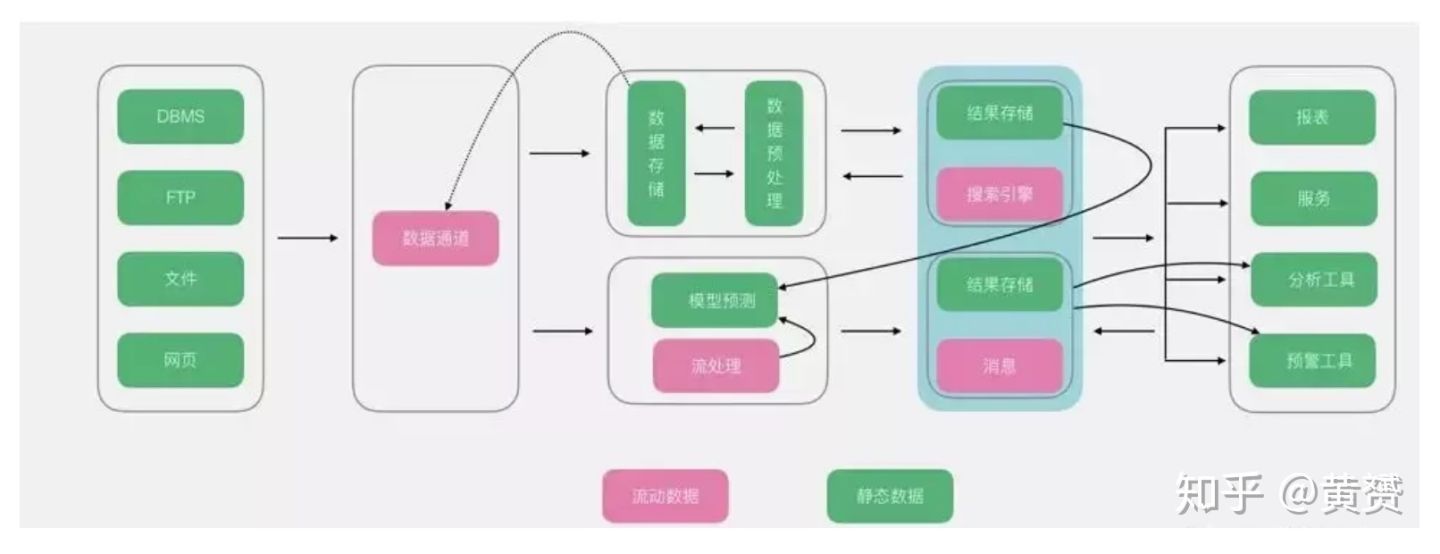
不得不說,《主流大資料架構》作者連 unified 都能寫成 unifield, 也不知道他本人是否熟知 unified 是什么意思
Unified Lambda 的概念
Lambda 與身俱來帶有很強的復雜性,為了克服這些復雜性,架構師們開始尋找各種各樣的替換方案,但始終逃不開這三樣:
1) 采用純粹的流式處理方法,同時使用靈巧的架構(比如 Apache Samza)完成某種意義上的批次處理,Apache Samza 依賴于 Kafka, 因此可以完成可回圈利用的磁區,達成批次處理;
2)采用另一種極端的方案,同時用微批次(micro batches)來完成準實時的資料處理,例如 Spark 就是這種方式,它的批次間隔可以達到 秒級,
3)Twitter 早在 2013年開源的 Summingbird 是一種同時支持批次處理與實時處理的框架,用 Scala API 封裝所有的 Batch, Speed Layer 操作,使得 Batch Layer 運行在 Hadoop 之上,而 Speed Layer 運行在 Storm 之上,而這一些都是封裝好的,Lambdoop 也是同樣的原理,同一個 API 封裝了實時處理與批次處理,很不幸的是后者在 2017年9月已經關閉了專案,
The downside of λ is its inherent complexity. Keeping in sync two already complex distributed systems is quite an implementation and maintenance challenge. People have started to look for simpler alternatives that would bring just about the same benefits and handle the full problem set. There are basically three approaches:
1) Adopt a pure streaming approach, and use a flexible framework such as Apache Samza to provide some type of batch processing. Although its distributed streaming layer is pluggable, Samza typically relies on Apache Kafka. Samza’s streams are replayable, ordered partitions. Samza can be configured for batching, i.e. consume several messages from the same stream partition in sequence.
2) Take the opposite approach, and choose a flexible Batch framework that would also allow micro-batches, small enough to be close to real-time, with Apache Spark/Spark Streaming or Storm’s Trident. Spark streaming is essentially a sequence of small batch processes that can reach latency as low as one second.Trident is a high-level abstraction on top of Storm that can process streams as small batches as well as do batch aggregation.
3) Use a technology stack already combining batch and real-time, such as Spring “XD”, Summingbird or Lambdoop. Summingbird (“Streaming MapReduce”) is a hybrid system where both batch/real-time workflows can be run at the same time and the results merged automatically.The Speed layer runs on Storm and the Batch layer on Hadoop, Lambdoop (Lambda-Hadoop, with HBase, Storm and Redis) also combines batch/real-time by offering a single API for both processing paradigms:
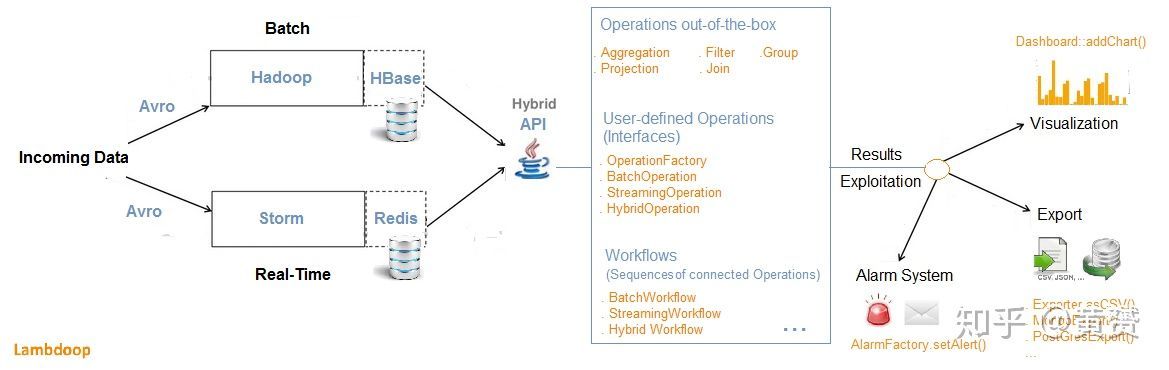
The integrated approach (unified λ) seeks to handle Big Data’s Volume and Velocity by featuring a hybrid computation model, where both batch and real-time data processing are combined transparently. And with a unified framework, there would be only one system to learn, and one system to maintain.
綜上,Lambda 架構是兼容了 batch layer, speed layer(real-time processing)的架構,Kappa 架構則是用 speed layer(real-time processing) 全程處理實時資料和歷史資料,Unified 架構則是利用統一的 Api 框架,兼容了 batch layer, speed layer, 并且在操作 2 層的資料結果的時候,使用的也是同一套 API 框架,
值得一提的是 butterfly architecture, 他采用的便是 Unified Architecture的原型, 在 http://ampool.io 公司的網站介紹上看到:
https://www.ampool.io/emerging-data-architectures-lambda-kappa-and-butterfly
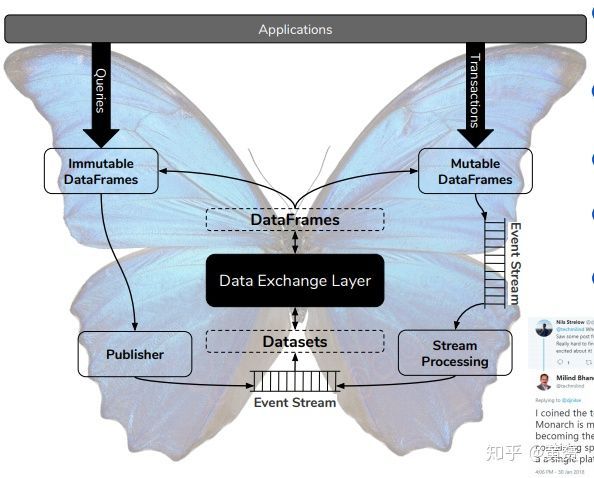
We note that the primary difficulty in implementing the speed, serving, and batch layers in the same unified architecture is due to the deficiencies of the distributed file system in the Hadoop ecosystem. If a storage component could replace or augment the HDFS to serve the speed and serving layers, while keeping data consistent with HDFS for batch processing, it could truly provide a unified data processing platform. This observation leads to the butterfly architecture.
在 Hadoop 生態圈系統中,由于分布式檔案系統缺失對 speed, batch, serving 層的一致性支持,所以想要基于 Hadoop 做統一存盤管理就比較困難,
The main differentiating characteristics of the butterfly architecture is the flexibility in computational paradigms on top of each of the above data abstractions. Thus a multitude of computational engines, such as MPP SQL-engines (Apache Impala, Apache Drill, or Apache HAWQ), MapReduce, Apache Spark, Apache Flink, Apache Hive, or Apache Tez can process various data abstractions, such as datasets, dataframes, and event streams. These computation steps can be strung together to form data pipelines, which are orchestrated by an external scheduler. A resource manager, associated with pluggable resource schedulers that are data aware, are a must for implementing the butterfly architecture. Both Apache YARN, and Apache Mesos, along with orchestration frameworks, such asKubernetes, or hybrid resource management frameworks, such as Apache Myriad, have emerged in the last few years to fulfill this role.
bufferfly architecture 的最大閃光點就是它能夠基于每一層的存盤做靈活的計算處理抽象,使得存和取都使用同一套軟體框架,如此多樣的計算引擎,比如 MPP SQL (Impala,Drill,HAWQ), MapReduce, Spark, Flink, Hive, Tez 可以同時訪問這些存盤抽象中的資料,比如 datasets, dataframes 和 event streams.
Datasets: partitioned collections, possibly distributed over multiple storage backends
DataFrames: structured datasets, similar to tables in RDBMS or NoSQL. Immutable dataframes are suited for analytical workloads, while mutable dataframes are suited for transactional CRUD workloads.
Event Steams: are unbounded dataframes, such as time series or sequences.
Datasets 就是分布式的資料集;DataFrames,是結構化的 DataSets, 與二維關系表或者NoSQL 的檔案等類似, 易變的DataFrame用來支持 OLTP 應用,而不易變的DataFrame則用來支持決策性應用;Event Stream 是DataSets 的源頭,也是 Publisher 與 Stream Processing 的下游,
以上參考這篇文章,我只是做了翻譯,并沒有親自實作過類似的架構
https://hpi.de/fileadmin/user_upload/fachgebiete/plattner/teaching/Ringvorlesung/Master_Nils_Strelow.pdf
問題重點在于,為什么有了 Kappa 架構還需要 Unified Lambda 架構呢?
1. Kappa 架構使用實時處理技術,既滿足了高速實時處理需求,還兼顧了批次處理的場景,在這種情況下, kappa 的缺陷是什么呢?
1.1 kappa 的批次處理能力不如 Lambda 架構下的 MapReduce ?
在 Lambda 架構下, MapReduce 的處理優勢體現在存盤和計算節點擴展容易,離線處理成功率高,而且每一步的 Map/Reduce 都有可靠的容錯能力,在失效場景下恢復資料處理夠快,而這一切對于實時處理程式 Storm/Flink/Spark 是不是就一定夠慢或者可靠性就差呢,其實不一定,關鍵看怎么配置和管理集群,
1.2 Kappa 的批次處理能力,需要配置的硬體成本可能比純粹的批次處理架構要高
這倒是可能的,基于記憶體計算的實時處理,占用的資源一定是比基于 Hadoop 的 Map/Reduce 模式要高,
2. Unified Lambda 架構可以提供一套統一的架構 API 來執行 Batch 和 Speed layer 的操作,
因此綜合了 Kappa 的優勢,即單一代碼庫,而且還克服了 Kappa 的劣勢,即流式處理容易出錯和高成本,
雖然 Unified Lambda (Hybrid Architecture )看上去面面俱到,但我還是看好Kappa, 且看微軟發布的兩張圖,一張是 Lambda, 一張是 Kappa, 最簡單的東西往往最高效!
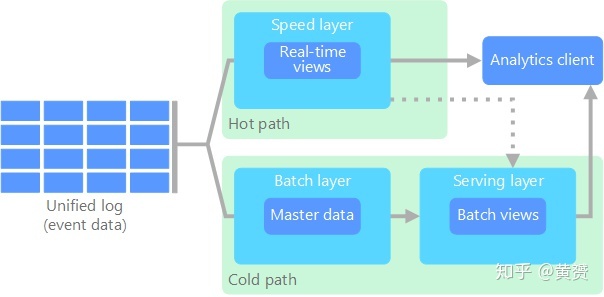
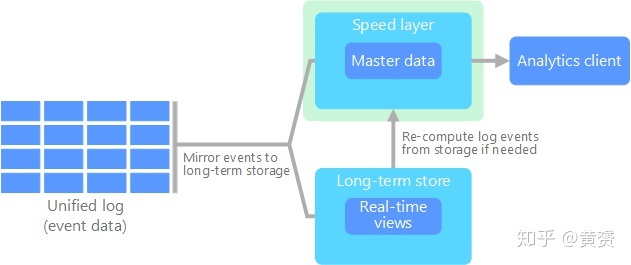
既然 Batch Layer 已經可以被 Speed Layer 給兼容實作了,那么 Kappa 就已經擁有了最簡單實用的核心,為什么還要費心去欄位外的那些作業呢?
本文轉載于:
解讀主流大資料架構 - 知乎
https://zhuanlan.zhihu.com/p/40996525
資料科學交流群,群號:189158789 ,歡迎各位對資料科學感興趣的小伙伴的加入!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/234809.html
標籤:其他