這段時間一直在處理資料采集的問題,目前平臺資料采集趨于穩定,可以抽出時間來整理一下近期的成果,順便介紹一些近期用到的技術,本篇文章偏向技術,需要讀者有一定的技識訓礎,主要介紹資料采集程序中用到的神器mitmproxy,以及平臺的一些技術設計,以下是資料采集整體的設計,左邊是客戶機,在里面放置了不同的采集器,采集器發起請求之后,通過mitmproxy訪問抖音,等資料回傳之后,通過中間的決議器對資料進行決議,最后分門別類的存盤到資料庫中,為了提升性能,在中間加入了快取,把采集器和決議器分隔開,兩個模塊之間作業互不影響,可以最大限度的把資料入庫,下圖為第一代架構設計,后續會有一篇文章介紹平臺架構設計的三代演化史,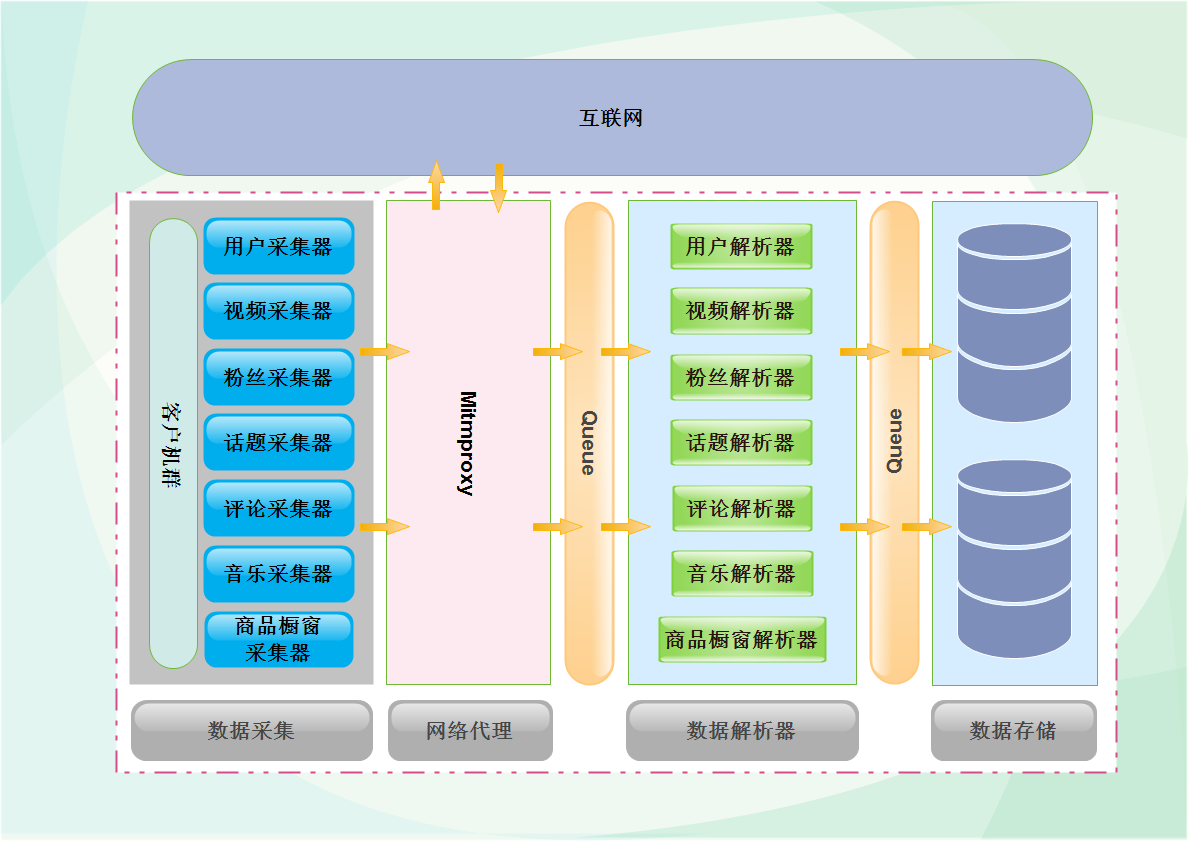
準備作業
開始進入資料采集的準備作業,第一步自然是環境搭建,本次我們在windows環境下,采用python3.6.6環境,抓包和代理工具是mitmproxy,也可以使用Fiddler抓包,采用夜神模擬器來模擬安卓運行環境(也可以用真機),這次主要通過手動滑動app來抓取資料,下次介紹采用Appium自動化工具,實作資料采集的全自動(解放雙手),
1、安裝python3.6.6環境,安裝程序可自行百度,需要注意的是,centos7自帶的是python2.7,需要升級到python3.6.6環境,升級之前主要先安裝ssl模塊,否則升級好的版本無法訪問https的請求,
2、安裝mitmproxy,安裝好python環境后,在命令列執行pip install mitmproxy安裝mitmproxy,注:windows下只有mitmdump和mitmweb可以使用,安裝好后在命令列輸入mitmdump即可啟動,默認啟動的代理埠為8080,
3、安裝夜神模擬器,可以在官網下載安裝包,安裝教程自行百度即可,基本都是下一步,安裝好夜神模擬器之后,需要對夜神模擬器進行配置,首先需要設定模擬器的網路為手動代理,IP地址為windows的IP,埠為mitmproxy的代理埠,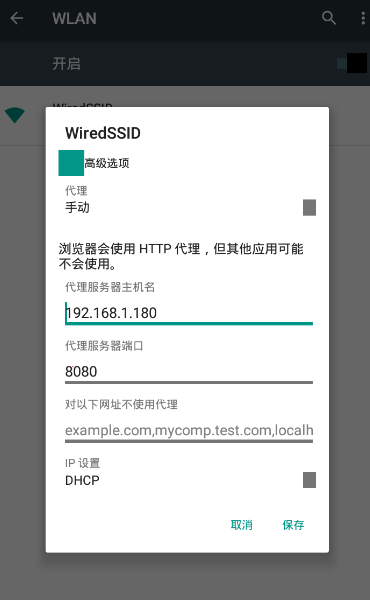
4、接下來是證書的安裝,打開模擬器中的瀏覽器,輸入地址mitm.it,選擇對應版本的證書,安裝好后,就可以進行抓包了,
5、安裝app,app安裝包可以到官網下載,然后通過拖拽進模擬器就可以安裝,或者在應用市場進行安裝,
至此,本次資料采集環境就全部搭建完成,
資料介面分析 抓包
搭建好環境之后就開始對抖音app進行資料抓包,分析出每個功能所使用的介面,本次以采集視頻資料介面為例介紹,
關閉之前打開的mitmdump,重新打開mitmweb工具,mitmweb是一個圖形化的版本,就不用對著黑框框找了,如下圖:
啟動之后打開模擬器的抖音app,可以看到已經有資料包決議出來了,然后進入用戶主頁,開始下滑視頻,在資料包串列中可以找到請求視頻資料的介面https://aweme.snssdk.com/aweme/v1/aweme/post/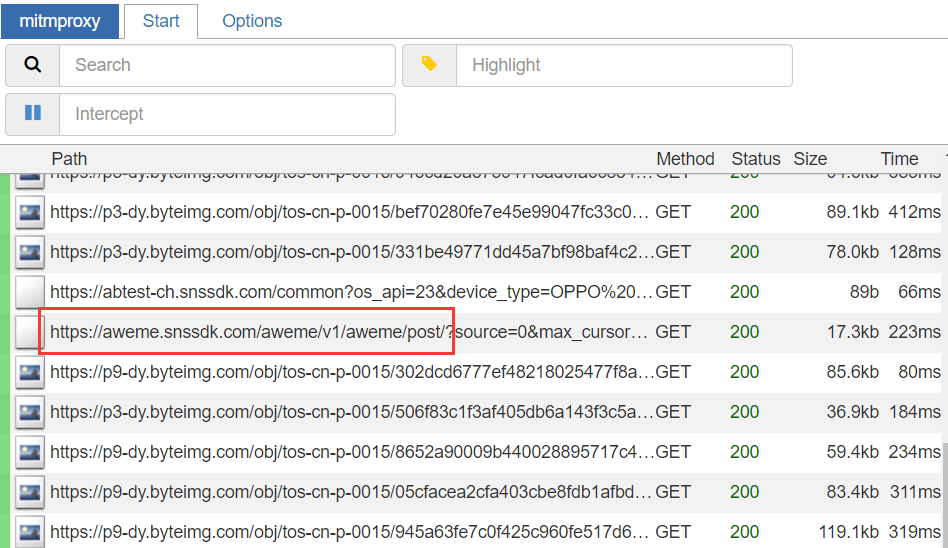
可以在右邊看到介面的請求資料和回應資料,我們將回應資料復制出來,進入下一步決議,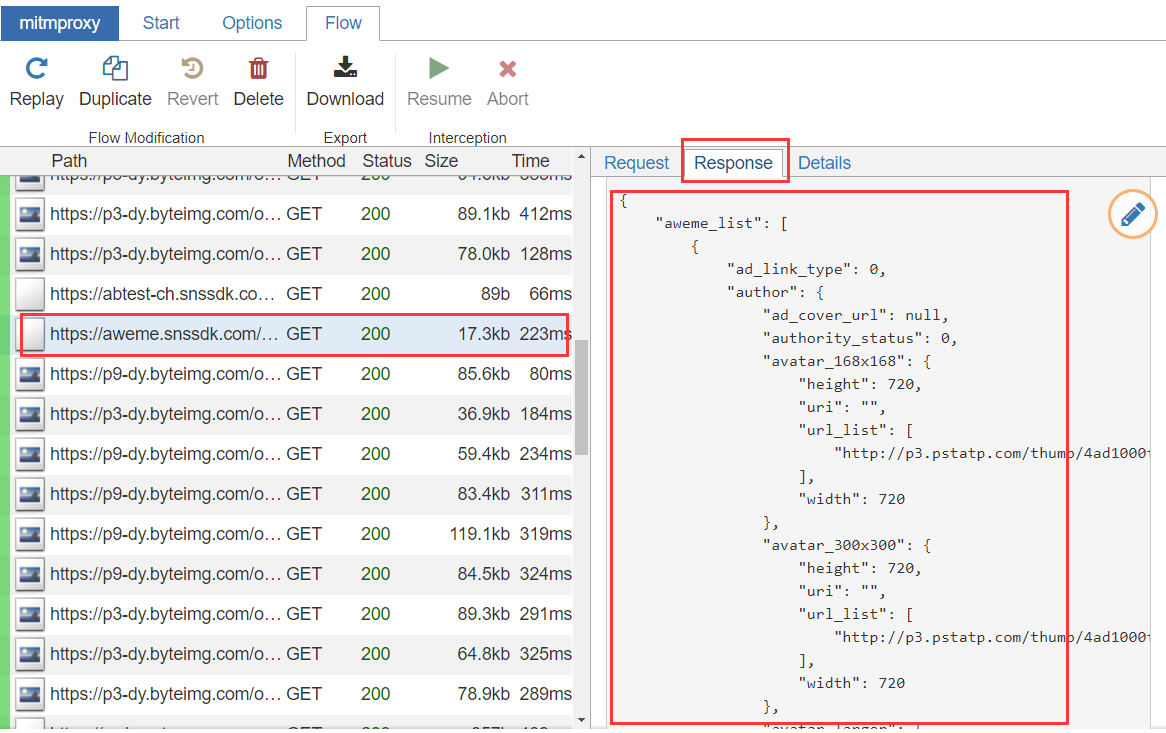
資料決議
通過mitmproxy和python代碼的結合,我們就可以在代碼中獲取到mitmproxy中的資料包,進而可以按照需求來處理,新建一個test.py檔案,里面放兩個方法:
def request(flow):
pass
def response(flow):
pass
見名知意,這兩個方法,一個是在請求的時候執行的,一個是在回應的時候執行,而資料包則存在于flow當中,通過flow.request.url可以獲取到請求url,flow.request.headers可以獲取到請求頭資訊,flow.response.text中的就是回應的資料了,
def response(flow):
if str(flow.request.url).startswith("https://aweme.snssdk.com/aweme/v1/aweme/post/"):
index_response_dict = json.loads(flow.response.text)
aweme_list = index_response_dict.get('aweme_list')
if aweme_list:
for aweme in aweme_list:
print(aweme)
這個aweme就是一個完整的視頻資料了,可以根據需要提取里面的資訊,這里提取部分資訊做介紹,
"statistics":{
"aweme_id":"6765058962225204493",
"comment_count":24,
"digg_count":1465,
"download_count":1,
"play_count":0,
"share_count":3,
"forward_count":0,
"lose_count":0,
"lose_comment_count":0
}
statistics資訊就是這個視頻的點贊,評論,下載,轉發的資料,
share_url為視頻的分享地址,通過這個地址,可以在PC端觀看抖音分享的視頻,也可以通過這個鏈接決議到無水印視頻,
play_addr為視頻的播放資訊,其中的url_list即為無水印地址,不過目前官方做了處理,這個地址無法直接播放,也有時間限制,超時之后鏈接就失效了,
有了這個aweme,就可以把里面的資訊決議出來,保存到自己的資料庫,或者下載無水印視頻,保存到自己電腦了,
寫好代碼之后,保存test.py檔案,cmd進入命令列,進入到保存test.py檔案目錄下,在命令列輸入mitmdump -s test.py,mitmdump就啟動了,此時打開app,開始滑動模擬器,進入用戶主頁:
開始不斷下滑,test.py檔案就可以把抓取到的視頻資料全部決議出來了,以下是我截取的部分資料資訊:
視頻資訊: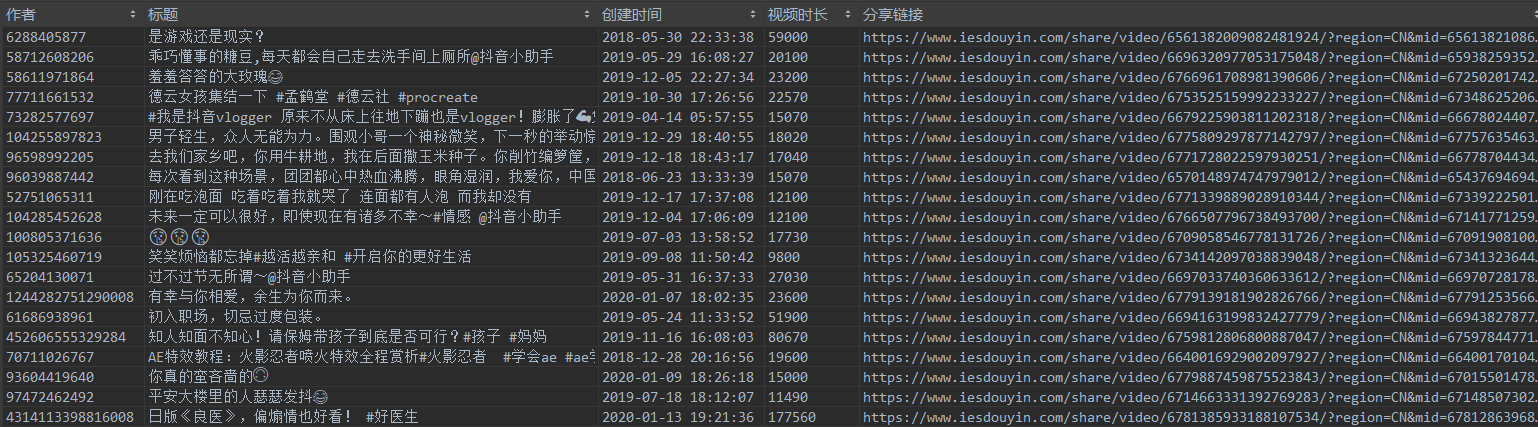
視頻統計資料: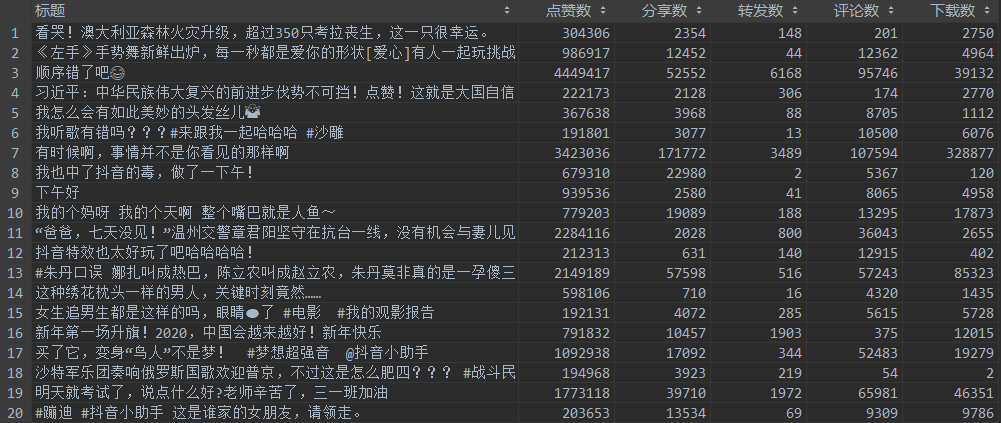
視頻評論資料: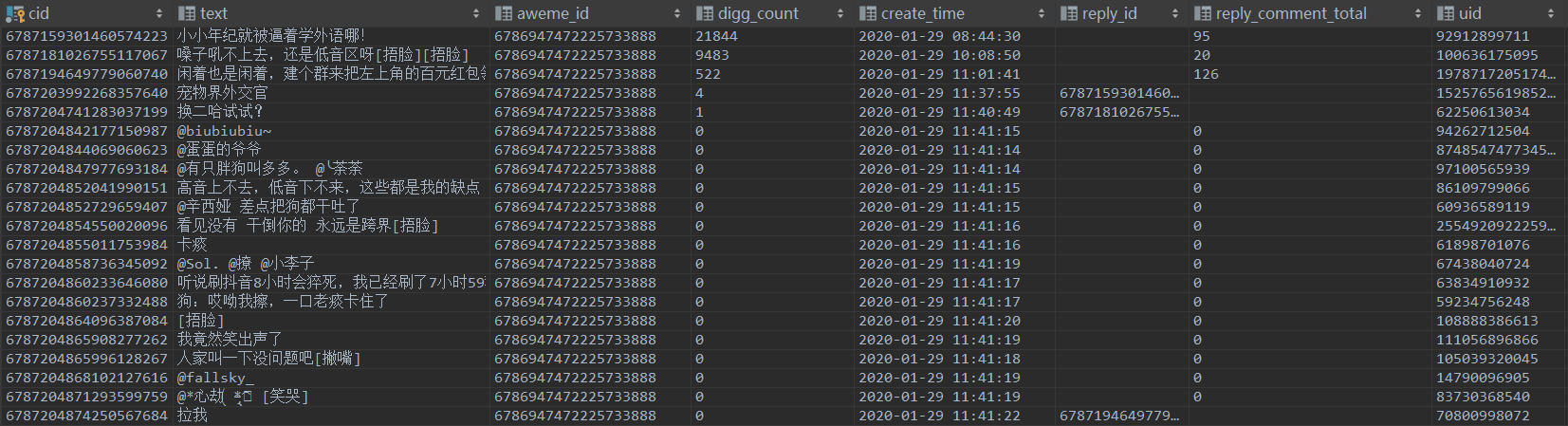
無水印視頻下載: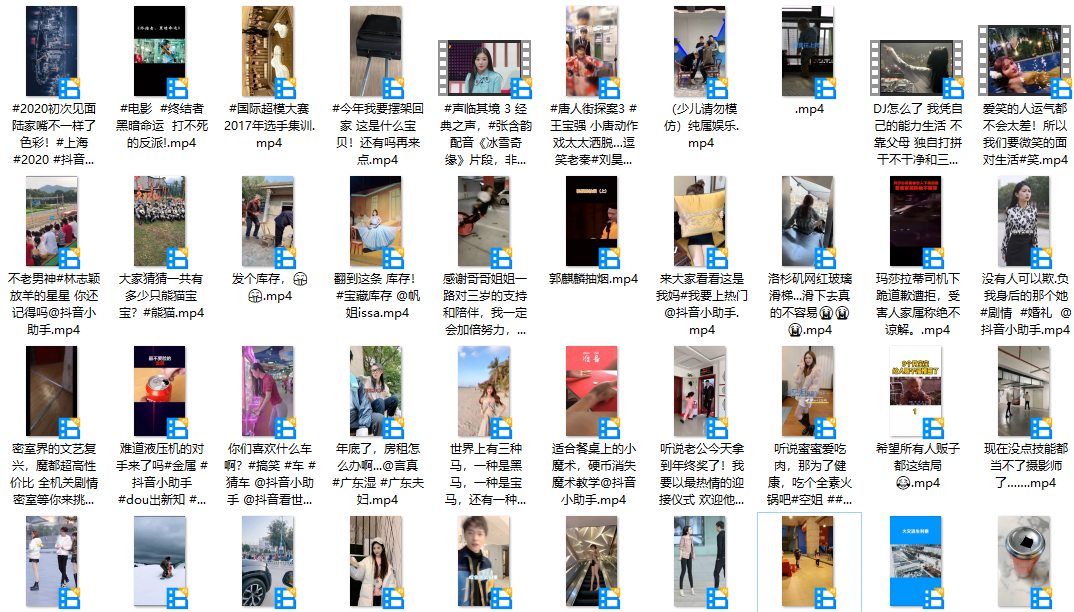
本次介紹就到這里結束了,主要是運用mitmdump配合python代碼來決議資料,下次講講怎么運用appium,怎么實作自動化滑動模擬器,實作這個程式的全自動抓取視頻資料,以及把采集下來的資料進行處理之后,得到的一些成果展示,
更多抖音,快手,小紅書資料實時采集介面,請查看檔案: TiToData
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/235394.html
標籤:其他
上一篇:業務場景下資料采集機制和策略
下一篇:抖音資料采集教程,高級版