好像涉及到了磁盤順序讀和隨機讀的問題,但一直沒太理解透,有哪個大佬能給小白講講嗎[face]monkey2:053.png[/face][face]monkey2:053.png[/face][face]monkey2:053.png[/face]
uj5u.com熱心網友回復:
select val_1, avg(val_2)
from big_table
where val_3 =1
group by val_1
big_table有幾千萬條資料,沒加索引之前查詢速度4s多,但加了索引后:
create index i_2 on big_table(val_3,val_1);
查詢速度降到了9s多。。。。
這到底是為什么呀。。。
uj5u.com熱心網友回復:
執行計劃↓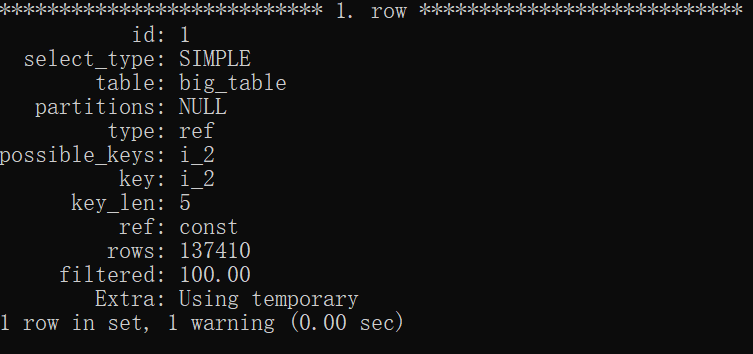
uj5u.com熱心網友回復:
幾千萬資料,如果 val_3 =1 的占比很大, 那這個索引是不值得的。反而不如建立索引之前的表掃描。
uj5u.com熱心網友回復:
數字都是隨機生成的,所以占比應該也沒有很大,幾百分之一吧。。。。
uj5u.com熱心網友回復:
不用應該,把 占比 貼出來看一下吧uj5u.com熱心網友回復:

占比也就0.5%耶
uj5u.com熱心網友回復:
emmm我改了下索引之后現在跑得賊快create index i_2 on big_table(val_3,val_1,val_2);運行時間0.03s
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/238826.html
標籤:疑難問題