Redis 中,字典是基礎結構,Redis 資料庫資料、過期時間、哈希型別都是把字典作為底層結構,
字典的結構
哈希表
哈希表的實作代碼在:dict.h/dictht ,Redis 的字典用哈希表的方式實作,
typedef struct dictht {
// 哈希表陣列,俗稱的哈希桶(bucket)
dictEntry **table;
// 哈希表的長度
unsigned long size;
// 哈希表的長度掩碼,用來計算索引值,保證不越界,總是 size - 1
// h = dictHashKey(ht, he->key) & n.sizemask;
unsigned long sizemask;
// 哈希表已經使用的節點數
unsigned long used;
} dictht;
table是一個哈希表陣列,每個節點的實作在dict.h/dictEntry,每個dictEntry保存一個鍵值對,size屬性記錄了向系統申請的哈希表的長度,不一定都用完,有預留空間的,sizemask屬性主要是用來計算索引值 = 哈希值 & sizemask,這個索引值決定了鍵值對放在table的哪個位置,它的值總是size - 1,其實我有點不明白為啥計算的時候不直接用size - 1,知道的大佬請明示,used屬性用來記錄已經使用的節點數,size-use就是未使用的節點啦,
下圖展示了一個大小為 4 的空哈希表結構,沒有任何鍵值對
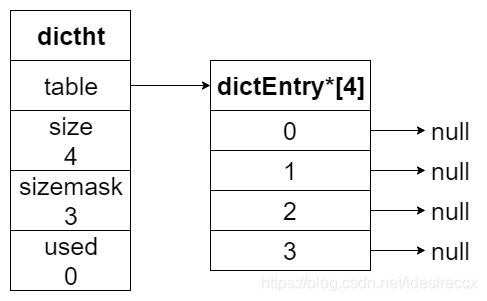
哈希節點
哈希表 dictht 的 table 的元素由哈希節點 dictEntry 組成,每一個 dictEntry 就是一個鍵值對
typedef struct dictEntry {
// 鍵
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// 下一個哈希節點,用于哈希沖突時拉鏈表用的
struct dictEntry *next;
} dictEntry;
next 指標是用于當哈希沖突的時候,可以形成鏈表用的,后續會將
字典
Redis 的字典實作在: dict.h/dict ,
typedef struct dict {
// 哈希演算法
dictType *type;
// 私有資料,用于不同型別的哈希演算法的引數
void *privdata;
// 兩個哈希表,用兩個的原因是 rehash 擴容縮容用的
dictht ht[2];
// rehash 進行到的索引值,當沒有在 rehash 的時候,為 -1
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 正在跑的迭代器
unsigned long iterators; /* number of iterators currently running */
} dict;
// dictType 實際上就是哈希演算法,不知道為啥名字叫 dictType
typedef struct dictType {
// hash方法,根據 key 計算哈希值
uint64_t (*hashFunction)(const void *key);
// 復制 key
void *(*keyDup)(void *privdata, const void *key);
// 復制 value
void *(*valDup)(void *privdata, const void *obj);
// key 比較
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 銷毀 key
void (*keyDestructor)(void *privdata, void *key);
// 銷毀 value
void (*valDestructor)(void *privdata, void *obj);
} dictType;
dictType 屬性表示字典型別,實際上這個字典型別就是一組操作鍵值對演算法,里面規定了很多函式,
privdata 則是為不同型別的 dictType 提供的可選引數,
如果有需要,在創建字典的時候,可以傳入dictType 和 privdata,
dict.c
// 創建字典,這里有 type 和 privdata 可以傳
dict *dictCreate(dictType *type, void *privDataPtr) {
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
}
// 初始化字典
int _dictInit(dict *d, dictType *type, void *privDataPtr) {
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
d->type = type;
d->privdata = https://www.cnblogs.com/chenchuxin/p/privDataPtr;
d->rehashidx = -1;
d->iterators = 0;
return DICT_OK;
}
下圖是比較完整的普通狀態下的 dict 的結構(沒有進行 rehash,也沒有迭代器的狀態):
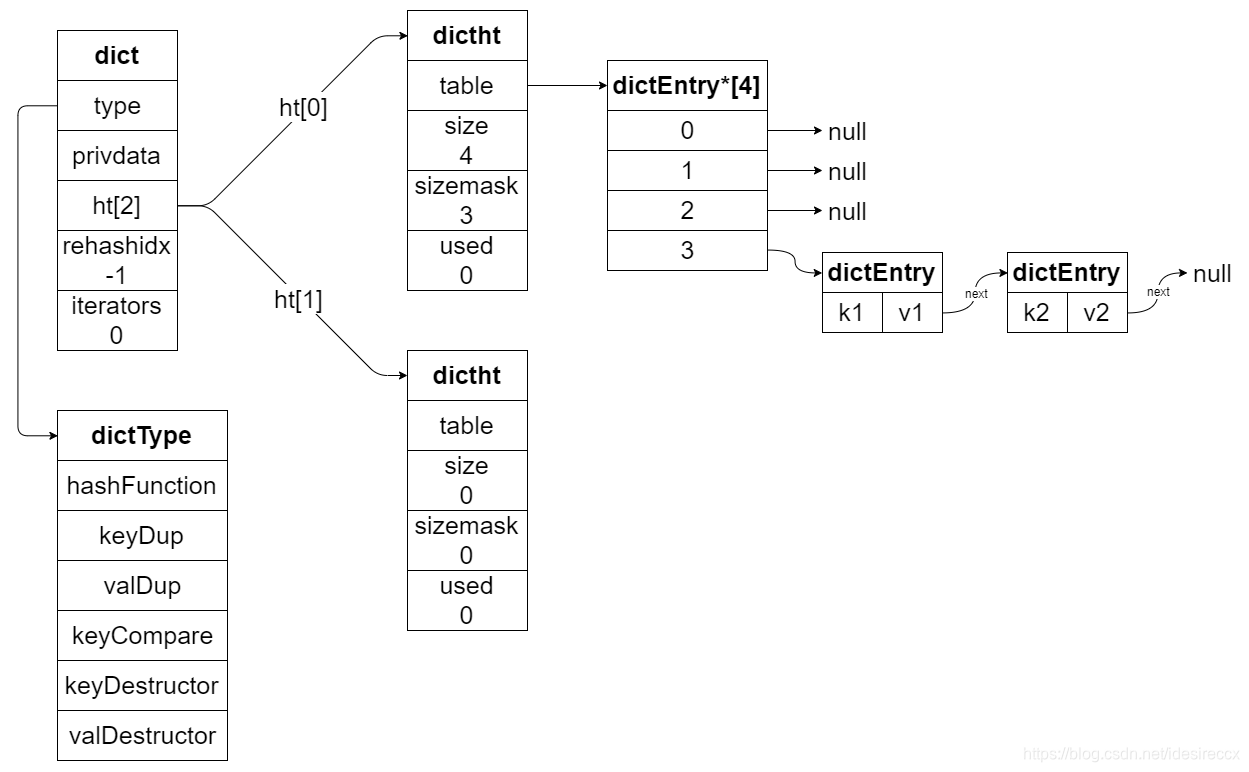 # 哈希演算法
# 哈希演算法
當字典中需要添加新的鍵值對時,需要先對鍵進行哈希,算出哈希值,然后在根據字典的長度,算出索引值,
// 使用哈希字典里面的哈希演算法,算出哈希值
hash = dict->type->hashFunction(key)
// 使用 sizemask 和 哈希值算出索引值
idx = hash & d->ht[table].sizemask;
// 通過索引值,定位哈希節點
he = d->ht[table].table[idx];
哈希沖突
哈希沖突指的是多個不同的 key,算出的索引值一樣,
Redis 解決哈希沖突的方法是:拉鏈法,就是每個哈希節點后面有個 next 指標,當發現計算出的索引值對應的位置有其他節點,那么直接加在前面節點后即可,這樣就形成了一個鏈表,
下圖展示了 {k1, v1} 和 {k2, v2} 哈希沖突的結構,
假設 k1 和 k2 算出的索引值都是 3,當 k2 發現 table[3] 已經有 dictEntry{k1,v1},那就 dictEntry{k1,v1}.next = dictEntry{k2,v2},
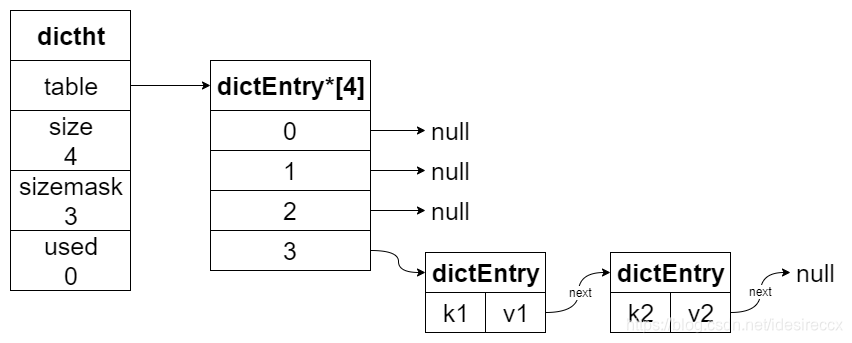
rehash
隨著操作的不斷進行,哈希表的長度會不斷增減,哈希表的長度太長會造成空間浪費,太短哈希沖突明顯導致性能下降,哈希表需要通過擴容或縮容,讓哈希表的長度保持在一個合理的范圍內,
Redis 通過 ht[0] 和 ht[1] 來完成 rehash 的操作,步驟如下:
- 為 ht[1] 分配空間,分配的空間長度有兩種情況:
- 擴容:第一個大于等于
ht[0].used * 2的 \(2^n\) 的數,例如 ht[0].used = 3,那么分配的是距離 6 最近的 \(2^3=8\) - 縮容:第一個大于等于
ht[0].used / 2的 \(2^n\) 的數,例如 ht[0].used = 6,那么分配的是距離 3 最近的 \(2^2=4\)
- 擴容:第一個大于等于
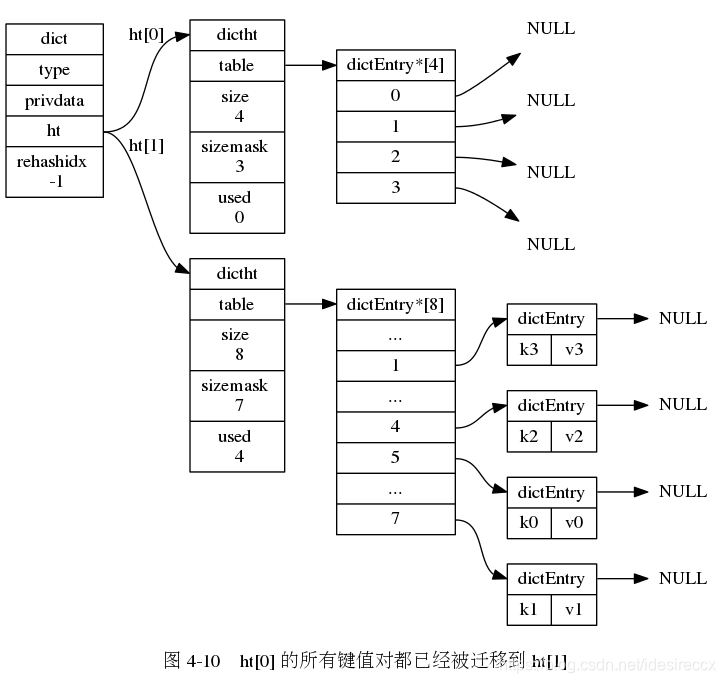
- 將 h[0] 上的鍵值對都遷移到 h[1],遷移的時候都是重新計算索引值的,由于 h[1] 的長度較長,之前在 h[0] 拉鏈的元素大概率會被分到不同的位置,
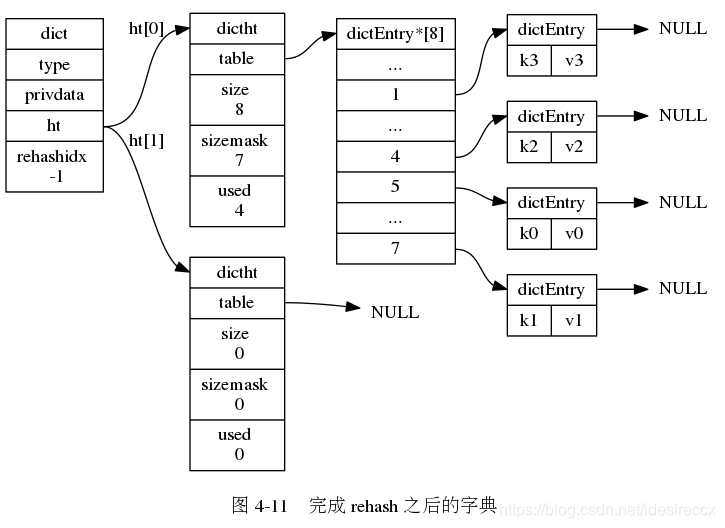
- ht[0] 所有的鍵值對遷移完之后,h[0] 釋放,然后
h[0] = h[1],并把 h[1] 清空,為下次 rehash 準備
漸進式 rehash
上面說的 rehash 中的第二步,遷移的程序不是一次完成的,如果哈希表的長度比較小,一次完成很快,但是如果哈希表很長,例如百萬千萬,那這個遷移的程序就沒有那么快了,會造成命令阻塞!
下面來說說,redis 是如何漸進式地將 h[0] 中的鍵值對遷移到 h[1] 中的:
- 為 h[1] 開辟空間,字典同時持有 h[0] 和 h[1]
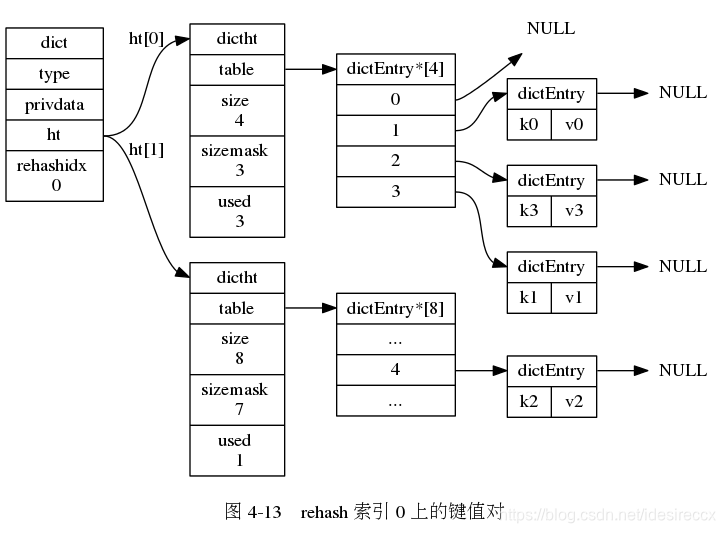
- 字典中的
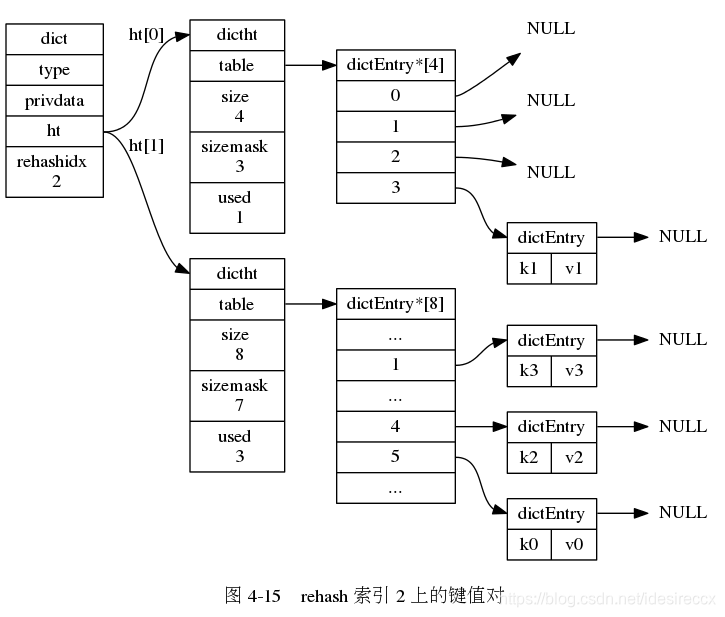
rehashidx維護了 rehash 的進度,設定為 0 的時候,開始 rehash - 字典每次增刪改查的時候,除了完成指定操作之外,還會順帶把
rehashidx上的整條鏈表遷移到h[1]中,遷移完之后rehashidx + 1 - 隨著字典的不斷讀取、操作,最終
h[0]上的所有鍵值對都會遷移到h[1]中,全部遷移完成之后rehashidx = -1
這種漸進式 rehash 的方式的好處在于,將龐大的遷移作業,分攤到每次的增刪改查中,避免了一次性操作帶來的性能的巨大損耗,
缺點就是遷移程序中 h[0] 和 h[1] 同時存在的時間比較長,空間利用率較低,
下面一系列的圖,演示了字典是如何漸進式地 rehash ( 圖片來自 《Redis 設計與實作》圖片集 )
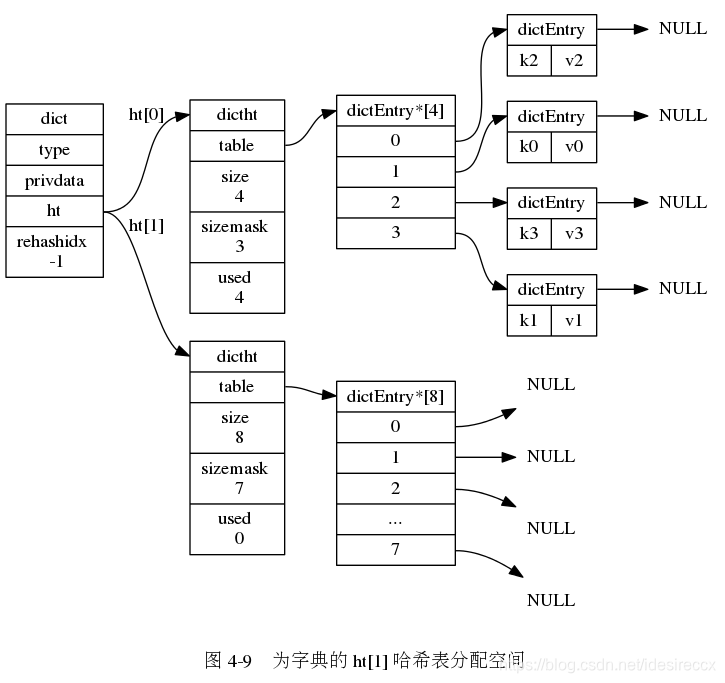





轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/240439.html
標籤:NoSQL
上一篇:Windows安裝MongoDB