前言
本文從HBase的記憶體布局說起,先充分了解HBase的記憶體區的使用與分配,隨后給出了不同業務場景下的讀寫記憶體分配規劃,并指導如何分析業務的記憶體使用情況,以及在使用當中寫記憶體Memstore及讀記憶體擴展bucketcache的一些注意事項,最后為了保障群集的穩定性減少和降低GC對于集群穩定性的影響,研究及分享了一些關于HBase JVM配置的一些關鍵引數機器作用和范例,希望這些不斷充實的經驗能確保HBase集群的穩定性能更上一個臺階,大家有任何的想法和建議也歡迎一起討論,
HBase的記憶體布局
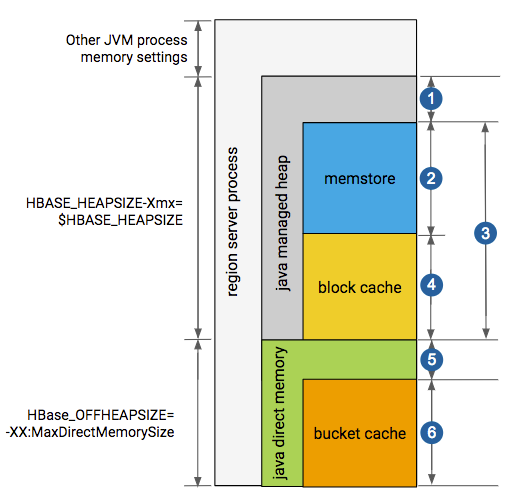
一臺region server的記憶體使用(如下圖所示)主要分成兩部分:
1.JVM記憶體即我們通常俗稱的堆內記憶體,這塊記憶體區域的大小分配在HBase的環境腳本中設定,在堆內記憶體中主要有三塊記憶體區域,
- 20%分配給hbase regionserver rpc請求佇列及一些其他操作
- 80%分配給memstore + blockcache
2.java direct memory即堆外記憶體,
- 其中一部分記憶體用于HDFS SCR/NIO操作
- 另一部分用于堆外記憶體bucket cache,其記憶體大小的分配同樣在hbase的環境變數腳本中實作
讀寫記憶體規劃
- 寫多讀少型規劃
在詳細說明具體的容量規劃前,首先要明確on heap模式下的記憶體分布圖,如下圖所示:
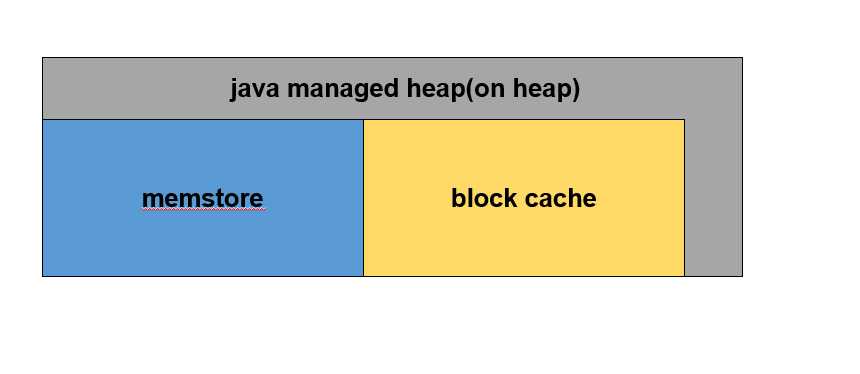
如圖,整個RegionServer記憶體就是JVM所管理的記憶體,BlockCache用于讀快取;MemStore用于寫流程,快取用戶寫入KeyValue資料;還有部分用于RegionServer正常RPC請求運行所必須的記憶體;
| 步驟 | 原理 | 計算 | 值 |
|---|---|---|---|
| jvm_heap | 系統總記憶體的 2/3 | 128G/3*2 | 80G |
| blockcache | 讀快取 | 80G*30% | 24G |
| memstore | 寫快取 | 80G*45% | 36G |
hbase-site.xmll
<property>
<name>hbase.regionserver.global.memstore.size</name>
<value>0.45</value>
</property>
<property>
<name>hfile.block.cache.size</name>
<value>0.3</value>
</property>
- 讀多寫少型規劃
與 on heap模式相比,讀多寫少型需要更多的讀快取,在對讀請求回應時間沒有太嚴苛的情況下,會開啟off heap即啟用堆外記憶體的中的bucket cache作為讀快取的補充,如下圖所示
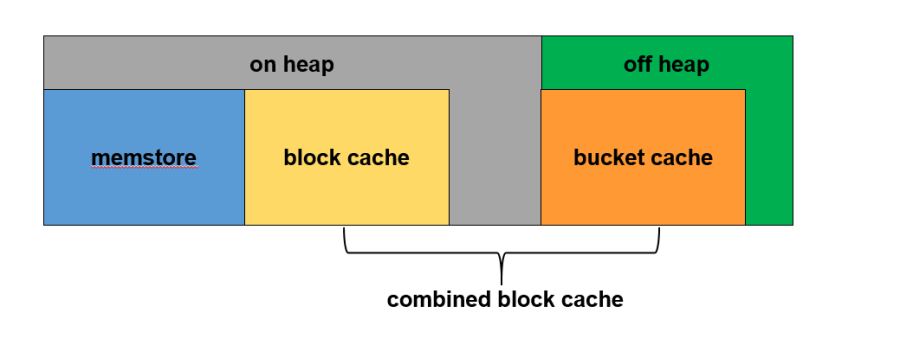
整個RegionServer記憶體分為兩部分:JVM記憶體和堆外記憶體,其中JVM記憶體中BlockCache和堆外記憶體BucketCache一起構成了讀快取CombinedBlockCache,用于快取讀到的Block資料,其中BlockCache用于快取Index Block和Bloom Block,BucketCache用于快取實際用戶資料Data Block
| 步驟 | 原理 | 計算 | 值 |
|---|---|---|---|
| RS總記憶體 | 系統總記憶體的 2/3 | 128G/3*2 | 80G |
| combinedBlockCache | 讀快取設定為整個RS記憶體的70% | 80G*70% | 56G |
| blockcache | 主要快取資料塊元資料,資料量相對較小,設定為整個讀快取的10% | 56G*10% | 6G |
| bucketcache | 主要快取用戶資料塊,資料量相對較大,設定為整個讀快取的90% | 56G*90% | 50G |
| memstore | 寫快取設定為jvm_heap的60% | 30G*60% | 18G |
| jvm_heap | rs總記憶體-堆外記憶體 | 80G-50G | 30G |
引數詳解
| Property | Default | Description |
|---|---|---|
| hbase.bucketcache.combinedcache.enabled | true | When BucketCache is enabled, use it as a L2 cache for LruBlockCache. If set to true, indexes and Bloom filters are kept in the LruBlockCache and the data blocks are kept in the BucketCache. |
| hbase.bucketcache.ioengine | none | Where to store the contents of the BucketCache. Its value can be offheap、heap、file |
| hfile.block.cache.size | 0.4 | A float between 0.0 and 1.0. This factor multiplied by the Java heap size is the size of the L1 cache. In other words, the percentage of the Java heap to use for the L1 cache. |
| hbase.bucketcache.size | not set | When using BucketCache, this is a float that represents one of two different values, depending on whether it is a floating-point decimal less than 1.0 or an integer greater than 1.0. |
| -XX:MaxDirectMemorySize | MaxDirectMemorySize = BucketCache + 1 | A JVM option to configure the maximum amount of direct memory available for the JVM. It is automatically calculated and configured based on the following formula: MaxDirectMemorySize = BucketCache size + 1 GB for other features using direct memory, such as DFSClient. For example, if the BucketCache size is 8 GB, it will be -XX:MaxDirectMemorySize=9G. |
hbase-site.xml
<property>
<name>hbase.bucketcache.combinedcache.enabled</name>
<value>true</value>
</property>
<property>
<name>hbase.bucketcache.ioengine</name>
<value>offheap</value> #同時作為master的rs要用heap
</property>
<property>
<name>hbase.bucketcache.size</name>
<value>50176</value> #單位MB,這個值至少要比bucketcache小1G,作為master的rs用heap,那么這里要填<1的值作為從heap中分配給bucketcache的百分比
</property>
<property>
<name>hbase.regionserver.global.memstore.size</name>
<value>0.60</value> #heap減小了,那么heap中用于memstore的百分比要增大才能保證用于memstore的記憶體和原來一樣
</property>
<property>
<name>hfile.block.cache.size</nname>
<value>0.20</value> #使用了bucketcache作為blockcache的一部分,那么heap中用于blockcache的百分比可以減小
</property>
hbase-env.sh
export HBASE_REGIONSERVER_OPTS="-XX:+UseG1GC
-Xms30g –Xmx30g -XX:MaxDirectMemorySize=50g
讀寫記憶體的使用情況
知己知彼方能百戰不殆,在HBase群集的運行程序中,我們需要了解HBase實際情況下的讀寫記憶體使用,才能最大化的對配置做出最加的調整,接下來說下如何查詢HBase運行中讀寫記憶體使用情況
Jmx查詢
http://xxxxxxxx.hadoop.db.com:11111/jmx?qry=Hadoop:service=HBase,name=RegionServer,sub=Server
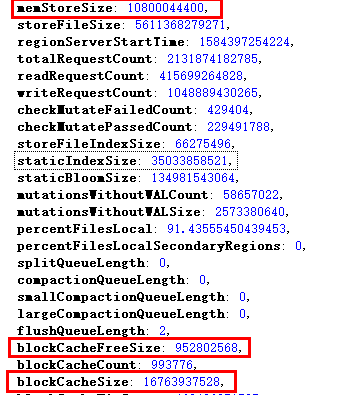
memStoreSize代表RegionServer中所有HRegion中的memstore大小的總和,單位是Byte,該值的變化,可以反應出一個RegionServer上寫請求的負載狀況,可以觀察memstoreSize的變化率,如果在單位時間內變化比較抖動,可以近似認為寫操作頻繁,
blockCacheFree代表block cache中空閑的記憶體大小,計算方法為:getMaxSize() – getCurrentSize(),單位是Byte,該值反映出當前BlockCache中還有多少空間可以被利用,
blockCacheSize代表當前使用的blockCache的大小,BlockCache. getCurrentSize(),單位是Byte,該值反映出BlockCache的使用狀況,
以單臺region server配置為例
| 配置項 | 配置值 | 記憶體分配值 | 實際使用量 |
|---|---|---|---|
| HBASE_REGIONSERVER_OPTS | -Xms75g –Xmx75g | 75g | 75g |
| hbase.regionserver.global.memstore.size | 0.22 | 80g*0.22 = 17.6g | 10800044400/1024/1024/1024 ≈ 10G |
| hfile.block.cache.size | 0.22 | 80g*0.22 = 17.6g | 16763937528 /1024/1024/1024 ≈ 15.6G 952802568 /1024/1024/1024 ≈ 0.9G |
結合單臺regionserver 的配置來看,讀寫快取都有一定空閑空間,這種情況下可以降低heap size來減少gc的次數和時長,然后我們還需要以群集所有region server的資料來判斷該集群的配置是否合理,如果存在讀寫不均衡和熱點情況都會影響不同region間的快取大小,
Memstore 深度決議
- Memstore簡介
一張資料表由一個或者多個region 組成,在單個region中每個columnfamily組成一個store,在每個store中由一個memstore和多個storefile組成,如下圖所示
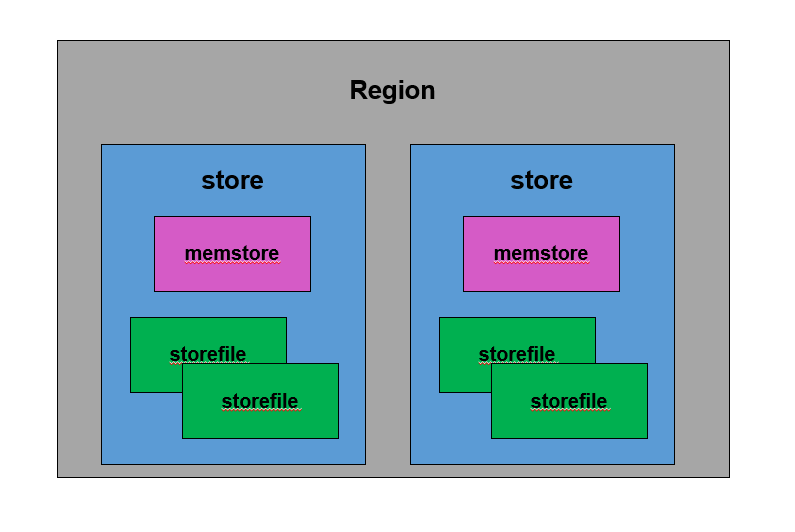
HBase是基于LSM-Tree資料結構的,為了提升寫入性能,所有資料寫入操作都會先寫入memstore中(同時會順序寫入WAL),達到指定大小后會對memstore中的資料做次排序后在批量flush磁盤中,此外新寫入的資料有較大概率被讀取到,因此HBase在讀取資料時首先檢查memstore中是否有資料快取,未命中的情況下再去找讀快取,可見memstore無論對于HBase的寫入和讀取性能都至關重要,而其中memstore flush操作又是memstore最核心的操作,
- Memstore Flush操作
| 操作級別 | 觸發條件 | 影響度 |
|---|---|---|
| memstore級別 | 當region中任意一個memstore的大小達到了上限 即>hbase.hregion.memstore.flush.size = 256mb |
小,短暫阻塞寫 |
| region級別 | 當region中所有的memstore的大小達到了上限 即>hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size = 8 * 256mb |
小,短暫阻塞寫 |
| regionserver級別 | 當一個regionserver中所有memstore的大小達到了上限 即> hbase.regionserver.global.memstore.size * heap_size = 0.22*75g |
大,阻塞regionserver上的所有寫請求且時間較長 |
| regionserver中WAL Log數量達到上限 | > hbase.regionserver.maxlogs = 256 系統會選取最早的一個 WAL Log對應的一個或多個region進行flush |
小,短暫阻塞寫 |
| 定期重繪 | > hbase.regionserver.optionalcacheflushinterval = 3600000 | 小,短暫阻塞寫 |
| 手動重繪 | 用戶可以通過shell命令flush table 或者flush region name分別對一個表或者一個region進行flush | 小,短暫阻塞寫 |
- Memstore設定總結
從memstore flush的動作來看,對業務影響最大是regionserver級別的flush操作,假設每個memstore大小為256mb,每個region有兩個cf,整個regionserver上有100個region,根據計算可知,總消耗記憶體 = 256mb2100 = 51.2g >> 0.40*80g = 32g ,很顯然這樣的設定情況下,很容易觸發region server級別的flush操作,對用戶影響較大,
根據如上分析,memstore的設定大小不僅取決于讀寫的比例,也要根據業務的region數量合理分配memstore大小,同樣的我們對每臺regionserver上region的數量及每張表cf的數量上的控制也能達到理想的效果,
堆外記憶體注意事項
Bucketcache的三種作業模式
- heap
heap模式分配記憶體會呼叫byteBuffer.allocate方法,從JVM提供的heap區分配,
記憶體分配時heap模式需要首先從作業系統分配記憶體再拷貝到JVM heap,相比offheap直接從作業系統分配記憶體更耗時,但反之讀取快取時heap模式可以從JVM heap中直接讀取比較快,
- offheap
offheap模式會呼叫byteBuffer.allocateDirect方法,直接從作業系統分配,因為記憶體屬于作業系統,所以基本不會產生CMS GC,也就在任何情況下都不會因為記憶體碎片導致觸發Full GC,
記憶體分配時offheap直接從作業系統分配記憶體比較快,但反之讀取時offheap模式需要首先從作業系統拷貝到JVM heap再讀取,比較費時,
- file
file使用Fussion-IO或者SSD等作為存盤介質,相比昂貴的記憶體,這樣可以提供更大的存盤容量,
堆外記憶體的優勢
使用堆外記憶體,可以將大部分BlockCache讀快取遷入BucketCache,減少jvm heap的size,可以減少GC發生的頻次及每次GC時的耗時
BucketCache沒有使用JVM 記憶體管理演算法來管理快取,而是自己對記憶體進行管理,因此其本身不會因為出現大量碎片導致Full GC的情況發生,
堆外記憶體的缺陷
讀取data block時,需要將off heap的記憶體塊拷貝到jvm heap在讀取,比較費時,對讀性能敏感用戶不太合適,
堆外記憶體使用總結
對于讀多寫少且對讀性能要求不高的業務場景,offheap模式能夠有效的減少gc帶來的影響,線上的vac集群在開啟offheap模式后,GC頻次和耗時都能有效降低,但是因為bucketcache 讀的性能的問題達不到要求而回退到heap模式,
JVM的配置優化及詳解
Hbase服務是基于JVM的,其中對服務可用性最大的挑戰是jvm執行full gc操作,此時會導致jvm暫停服務,這個時候,hbase上面所有的讀寫操作將會被客戶端歸入佇列中排隊,一直等到jvm完成gc操作, 服務在遇到full gc操作時會有如下影響
- hbase服務長時間暫停會導致客戶端操作超時,操作請求處理例外,
- 服務端超時會導致region資訊上報例外丟失心跳,會被zk標記為宕機,導致regionserver即便回應恢復之后,也會因為查詢zk上自己的狀態后自殺,此時hmaster 會將該regionserver上的所有region移動到其他regionserver上
如何避免和預防GC超時的不良影響,我們需要對JVM的引數進行優化
hbase-env.sh
| 配置項 | 重要引數詳解 |
|---|---|
| export HBASE_HEAPSIZE=4096 | HBase 所有實體包括Master和RegionServer占用記憶體的大小,不過一般用Master和RegionServer專有引數來分別設定他們的記憶體大小,推薦值給到4096 |
| export HBASE_MASTER_OPTS=" -Xms8g -Xmx8g -Xmn1g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70" |
Master專有的啟動引數,Xms、Xmx、Xmn分別對應初始堆、最大堆及新生代大小 Master小堆,新生代用并行回收器、老年代用并發回收器,另外配置了CMSInitiatingOccupancyFraction,當老年代記憶體使用率超過70%就開始執行CMS GC,減少GC時間,Master任務比較輕,一般設定4g、8g左右,具體按照群集大小評估 |
| export HBASE_REGIONSERVER_OPTS="-XX:+UseG1GC -Xms75g –Xmx75g -XX:InitiatingHeapOccupancyPercent=83 -XX:G1HeapRegionSize=32M -XX:ParallelGCThreads=28 -XX:ConcGCThreads=20 -XX:+UnlockExperimentalVMOptions -XX:G1NewSizePercent=8 -XX:G1HeapWastePercent=10 -XX:MaxGCPauseMillis=80 -XX:G1MixedGCCountTarget=16 -XX:MaxTenuringThreshold=1 -XX:G1OldCSetRegionThresholdPercent=8 -XX:+ParallelRefProcEnabled -XX:-ResizePLAB -XX:+PerfDisableSharedMem -XX:-OmitStackTraceInFastThrow -XX:+PrintFlagsFinal -verbose:gc -XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintAdaptiveSizePolicy -XX:+PrintGCDetails -XX:+PrintGCApplicationStoppedTime -XX:+PrintTenuringDistribution -XX:+PrintReferenceGC -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=100M Xloggc:${HBASE_LOG_DIR}/gc-regionserver$(hostname)-`date +'%Y%m%d%H%M'`.log -Dcom.sun.management.jmxremote.port=10102 $HBASE_JMX_BASE" |
RegionServer專有的啟動引數,RegionServer大堆,采用G1回收器,G1會把堆記憶體劃分為多個Region,對各個Region進行單獨的GC,最大限度避免Full GC及其影響 初始堆及最大堆設定為最大物理記憶體的2/3,128G/3*2 ≈80G,在某些度寫快取比較小的集群,可以近一步縮小, InitiatingHeapOccupancyPercent代表了堆占用了多少比例的時候觸發MixGC,默認占用率是整個 Java 堆的45%,改引數的設定取決于IHOP > MemstoreSize%+WriteCache%+10~20%,避免過早的MixedGC中,有大量資料進來導致Full GC G1HeapRegionSize 堆中每個region的大小,取值范圍【1M..32M】2^n,目標是根據最小的 Java 堆大小劃分出約 2048 個區域,即heap size / G1HeapRegionSize = 2048 regions ParallelGCThreads設定垃圾收集器并行階段的執行緒數量,STW階段作業的GC執行緒數,8+(logical processors-8)(5/8) ConcGCThreads并發垃圾收集器使用的執行緒數量,非STW期間的GC執行緒數,可以嘗試調大些,能更快的完成GC,避免進入STW階段,但是這也使應用所占的執行緒數減少,會對吞吐量有一定影響 G1NewSizePercent新生代占堆的最小比例,增加新生代大小會增加GC次數,但是會減少GC的時間,建議設定5/8對應負載normal/heavy集群 G1HeapWastePercent觸發Mixed GC的堆垃圾占比,默認值5 G1MixedGCCountTarget一個周期內觸發Mixed GC最大次數,默認值8 這兩個引數互為增加到10/16,可以有效的減少1S+ Mixed GC STW times MaxGCPauseMillis 垃圾回收的最長暫停時間,默認200ms,如果GC時間超長,那么會逐漸減少GC時回收的區域,以此來靠近此閾值,一般來說,按照群集的重要性 50/80/200來設定 verbose:gc在日志中輸出GC情況 |
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/242791.html
標籤:其他
下一篇:SQL 排序檢索資料