本文原始碼:GitHub || GitEE
一、Hive基礎簡介
1、基礎描述
Hive是基于Hadoop的一個資料倉庫工具,用來進行資料提取、轉化、加載,是一個可以對Hadoop中的大規模存盤的資料進行查詢和分析存盤的組件,Hive資料倉庫工具能將結構化的資料檔案映射為一張資料庫表,并提供SQL查詢功能,能將SQL陳述句轉變成MapReduce任務來執行,使用成本低,可以通過類似SQL陳述句實作快速MapReduce統計,使MapReduce變得更加簡單,而不必開發專門的MapReduce應用程式,hive十分適合對資料倉庫進行統計分析,
2、組成與架構
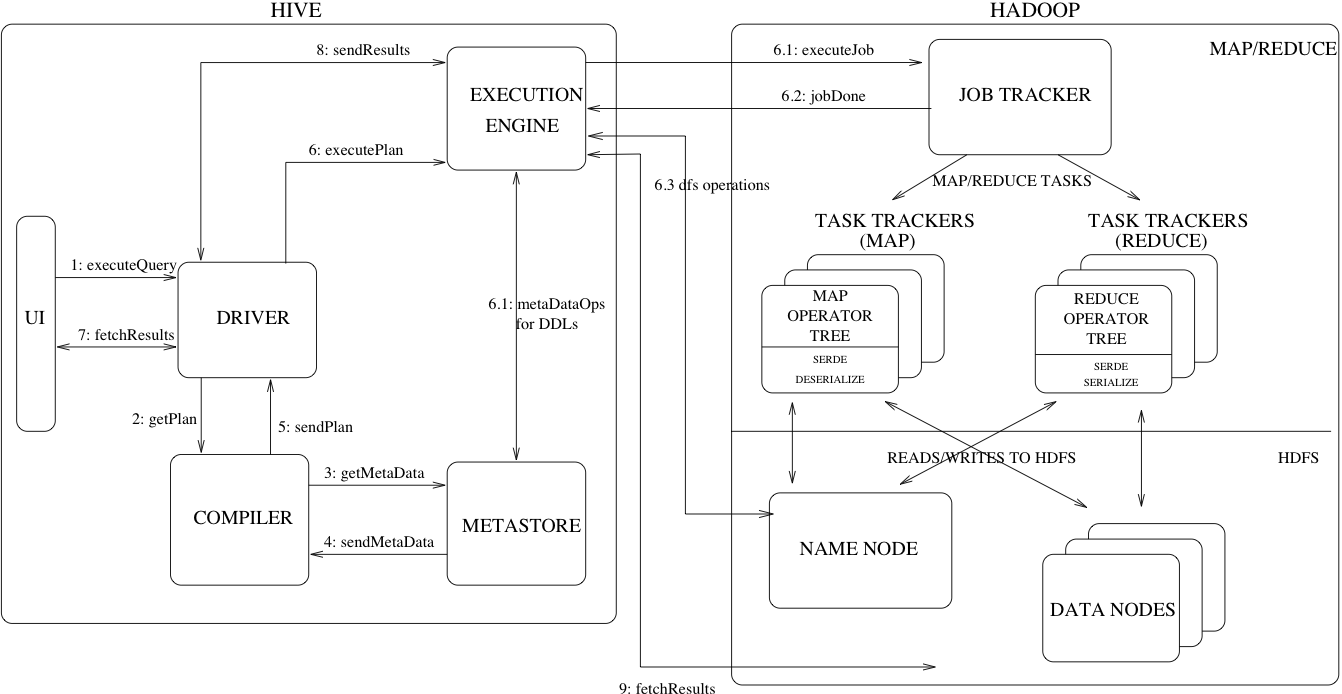
用戶介面:ClientCLI、JDBC訪問Hive、WEBUI瀏覽器訪問Hive,
元資料:Hive將元資料存盤在資料庫中,如mysql、derby,Hive中的元資料包括表的名字,表的列和磁區以及屬性,表的屬性(是否為外部表等),表的資料所在目錄等,
驅動器:基于解釋器、編輯器、優化器完成HQL查詢陳述句從詞法分析、語法分析、編譯、優化以及查詢計劃的生成,
執行器引擎:ExecutionEngine把邏輯執行計劃轉換成可以運行的物理計劃,
Hadoop底層:基于HDFS進行存盤,使用MapReduce進行計算,基于Yarn的調度機制,
Hive收到給客戶端發送的互動請求,接收到操作指令(SQL),并將指令翻譯成MapReduce,提交到Hadoop中執行,最后將執行結果輸出到客戶端,
二、Hive環境安裝
1、準備安裝包
hive-1.2,依賴Hadoop集群環境,位置放在hop01服務上,
2、解壓重命名
tar -zxvf apache-hive-1.2.1-bin.tar.gz
mv apache-hive-1.2.1-bin/ hive1.2
3、修改組態檔
創建組態檔
[root@hop01 conf]# pwd
/opt/hive1.2/conf
[root@hop01 conf]# mv hive-env.sh.template hive-env.sh
添加內容
[root@hop01 conf]# vim hive-env.sh
export HADOOP_HOME=/opt/hadoop2.7
export HIVE_CONF_DIR=/opt/hive1.2/conf
配置內容一個是Hadoop路徑,和hive組態檔路徑,
4、Hadoop配置
首先啟動hdfs和yarn;然后在HDFS上創建/tmp和/user/hive/warehouse兩個目錄并修改賦予權限,
bin/hadoop fs -mkdir /tmp
bin/hadoop fs -mkdir -p /user/hive/warehouse
bin/hadoop fs -chmod g+w /tmp
bin/hadoop fs -chmod g+w /user/hive/warehouse
5、啟動Hive
[root@hop01 hive1.2]# bin/hive
6、基礎操作
查看資料庫
hive> show databases ;
選擇資料庫
hive> use default;
查看資料表
hive> show tables;
創建資料庫使用
hive> create database mytestdb;
hive> show databases ;
default
mytestdb
hive> use mytestdb;
創建表
create table hv_user (id int, name string, age int);
查看表結構
hive> desc hv_user;
id int
name string
age int
添加表資料
insert into hv_user values (1, "test-user", 23);
查詢表資料
hive> select * from hv_user ;
注意:這里通過對查詢日志的觀察,明顯看出Hive執行的流程,
洗掉表
hive> drop table hv_user ;
退出Hive
hive> quit;
查看Hadoop目錄
# hadoop fs -ls /user/hive/warehouse
/user/hive/warehouse/mytestdb.db
通過Hive創建的資料庫和資料存盤在HDFS上,
三、整合MySQL5.7環境
這里默認安裝好MySQL5.7的版本,并配置好相關登錄賬號,配置root用戶的Host為%模式,
1、上傳MySQL驅動包
將MySQL驅動依賴包上傳到hive安裝目錄的lib目錄下,
[root@hop01 lib]# pwd
/opt/hive1.2/lib
[root@hop01 lib]# ll
mysql-connector-java-5.1.27-bin.jar
2、創建hive-site配置
[root@hop01 conf]# pwd
/opt/hive1.2/conf
[root@hop01 conf]# touch hive-site.xml
[root@hop01 conf]# vim hive-site.xml
3、配置MySQL存盤
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="https://www.cnblogs.com/cicada-smile/archive/2021/01/04/configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hop01:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
</configuration>
配置完成后,依次重啟MySQL、hadoop、hive環境,查看MySQL資料庫資訊,多了metastore資料庫和相關表,
4、后臺啟動hiveserver2
[root@hop01 hive1.2]# bin/hiveserver2 &
5、Jdbc連接測驗
[root@hop01 hive1.2]# bin/beeline
Beeline version 1.2.1 by Apache Hive
beeline> !connect jdbc:hive2://hop01:10000
Connecting to jdbc:hive2://hop01:10000
Enter username for jdbc:hive2://hop01:10000: hiveroot (賬戶回車)
Enter password for jdbc:hive2://hop01:10000: ****** (密碼123456回車)
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
0: jdbc:hive2://hop01:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| default |
+----------------+--+
四、高級查詢語法
1、基礎函式
select count(*) count_user from hv_user;
select sum(age) sum_age from hv_user;
select min(age) min_age,max(age) max_age from hv_user;
+----------+----------+--+
| min_age | max_age |
+----------+----------+--+
| 23 | 25 |
+----------+----------+--+
2、條件查詢陳述句
select * from hv_user where name='test-user' limit 1;
+-------------+---------------+--------------+--+
| hv_user.id | hv_user.name | hv_user.age |
+-------------+---------------+--------------+--+
| 1 | test-user | 23 |
+-------------+---------------+--------------+--+
select * from hv_user where id>1 AND name like 'dev%';
+-------------+---------------+--------------+--+
| hv_user.id | hv_user.name | hv_user.age |
+-------------+---------------+--------------+--+
| 2 | dev-user | 25 |
+-------------+---------------+--------------+--+
select count(*) count_name,name from hv_user group by name;
+-------------+------------+--+
| count_name | name |
+-------------+------------+--+
| 1 | dev-user |
| 1 | test-user |
+-------------+------------+--+
3、連接查詢
select t1.*,t2.* from hv_user t1 join hv_dept t2 on t1.id=t2.dp_id;
+--------+------------+---------+-----------+-------------+--+
| t1.id | t1.name | t1.age | t2.dp_id | t2.dp_name |
+--------+------------+---------+-----------+-------------+--+
| 1 | test-user | 23 | 1 | 技術部 |
+--------+------------+---------+-----------+-------------+--+
五、源代碼地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent
推薦閱讀:編程體系整理
| 序號 | 專案名稱 | GitHub地址 | GitEE地址 | 推薦指數 |
|---|---|---|---|---|
| 01 | Java描述設計模式,演算法,資料結構 | GitHub·點這里 | GitEE·點這里 | ☆☆☆☆☆ |
| 02 | Java基礎、并發、面向物件、Web開發 | GitHub·點這里 | GitEE·點這里 | ☆☆☆☆ |
| 03 | SpringCloud微服務基礎組件案例詳解 | GitHub·點這里 | GitEE·點這里 | ☆☆☆ |
| 04 | SpringCloud微服務架構實戰綜合案例 | GitHub·點這里 | GitEE·點這里 | ☆☆☆☆☆ |
| 05 | SpringBoot框架基礎應用入門到進階 | GitHub·點這里 | GitEE·點這里 | ☆☆☆☆ |
| 06 | SpringBoot框架整合開發常用中間件 | GitHub·點這里 | GitEE·點這里 | ☆☆☆☆☆ |
| 07 | 資料管理、分布式、架構設計基礎案例 | GitHub·點這里 | GitEE·點這里 | ☆☆☆☆☆ |
| 08 | 大資料系列、存盤、組件、計算等框架 | GitHub·點這里 | GitEE·點這里 | ☆☆☆☆☆ |
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/244661.html
標籤:其他