什么是MyCat
Mycat 是什么?從定義和分類來看,它是一個開源的分布式資料庫系統,是一個實作了MySQL 協議的的Server,前端用戶可以把它看作是一個資料庫代理,用MySQL 客戶端工具和命令列訪問,而其后端可以用MySQL 原生(Native)協議與多個MySQL 服務器通信,也可以用JDBC 協議與大多數主流資料庫服務器通信,其核心功能是分表分庫,即將一個大表水平分割為N 個小表,存盤在后端MySQL 服務器里或者其他資料庫里,
Mycat 發展到目前的版本,已經不是一個單純的MySQL 代理了,它的后端可以支持MySQL、SQLServer、Oracle、DB2、PostgreSQL 等主流資料庫,也支持MongoDB 這種新型NoSQL 方式的存盤,未來還會支持更多型別的存盤,而在最終用戶看來,無論是那種存盤方式,在Mycat 里,都是一個傳統的資料庫表,支持標準的SQL 陳述句進行資料的操作,這樣一來,對前端業務系統來說,可以大幅降低開發難度,提升開發速度,
核心實作原理
Mycat 的原理中最重要的一個動詞是“攔截”,它攔截了用戶發送過來的SQL 陳述句,首先對SQL 陳述句做了一些特定的分析:如分片分析、路由分析、讀寫分離分析、快取分析等,然后將此SQL 發往后端的真實資料庫,并將回傳的結果做適當的處理,最終再回傳給用戶,當Mycat 收到一個SQL 時,會先決議這個SQL,查找涉及到的表,然后看此表的定義,如果有分片規則,則獲取到SQL 里分片欄位的值,并匹配分片函式,得到該SQL 對應的分片串列,然后將SQL 發往這些分片去執行,最后收集和處理所有分片回傳的結果資料,并輸出到客戶端,
主體架構
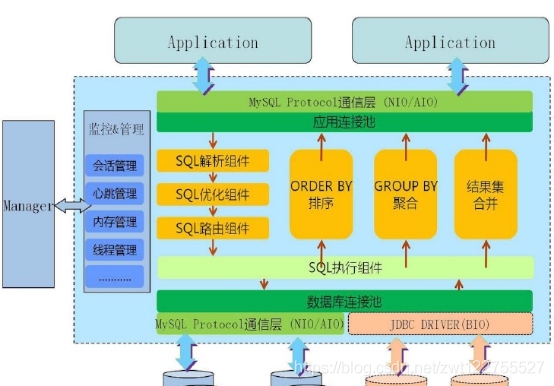
Mycat在邏率持上由幾個模塊組成:通信協議、路由決議、結果集處理、資料庫連接、監控等模塊,
- 通信協議模塊:底層的收發資料、執行緒回呼處理作業,主要采用 Reactor、 proactor模式來提高效率,目前, Mycat通信模塊默認釆用 Reactor模式,在協議層采用 MySQL協議,
- 路由決議模塊:對傳入的SL陳述句進行語法決議,決議從 MySQL協議中決議出來并進入該模塊的SQL陳述句的條件、陳述句型別、攜帶的關鍵字等,對符合要求的SQL陳述句進行相關優化,最后根據這些路由計算單元進行路由計算,
- 結果集處理模塊:對跨分片的結果進行匯聚、排序、截取等,由于資料存盤在不同的資料庫中,所以對跨分片的資料需要進行匯聚,
- 資料庫連接模塊:創建、管理、維護后端的連接池,為了誠少每次建立資料庫連接的開銷,資料庫使用連接池機制對連接生命周期進行管理
- 監控管理模塊:對 Mycat中的連接、記憶體等資源進行監控和管理,監控主要是通過管理命令實時地展現一些監控資料,例如連接數、快取命中數等;管理則主要通過輪詢事件來檢測和釋放不使用的資源,
- SQL執行模塊:從連接池中獲取相應的目標連接,對目標連接進行資訊同步后,再根據路由決議的結果,把SQL陳述句分發到相應的節點執行,
執行流程
主要流程:由通信協議模塊的讀寫事件通知發起,讀寫事件通知具體的回呼代碼進行這次讀寫事件的處理,管理模塊的執行流程由定時器事件進行資源檢查和資源釋放時發起,由客戶端發送過來的資料通過協議決議、路由決議等流程進入執行組件,通過執行組把資料發送到通信協議模塊,最終資料被寫入目標資料庫,由后端資料庫回傳資料,通過協議決議后發送至回呼模塊,如果是涉及多節點的資料,則執行流程將會先進入結果集匯聚、排序等模塊中,然后將處理后的資料通過通信協議模塊回傳到客戶端,如果有排序則是用的將結果集在mycat中進行了堆排序,
從原理上來看,可以把mycat 看成一個sql 轉發器,mycat 接收到前端發來的sql,然后轉發到后臺的mysql 服務器上去執行,但是后面有很多臺mysql 節點(如dn1,dn2,dn3),該轉發到哪些節點呢?這就是路由決議該做的事情了,路由能保證sql 轉發到正確的節點,轉發的范圍是剛剛好,不多發也不少發,在選型上,mycat使用的是druidparser,
核心概念
- 邏輯庫(schema):通常對實際應用來說,并不需要知道中間件的存在,業務開發人員只需要知道資料庫的概念,所以資料庫中間件可以被看做是一個或多個資料庫集群構成的邏輯庫,
- 邏輯表(table):既然有邏輯庫,那么就會有邏輯表,分布式資料庫中,對應用來說,讀寫資料的表就是邏輯表,邏輯表,可以是資料切分后,分布在一個或多個分片庫中,也可以不做資料切分,不分片,只有一個表構成,
- 分片表:分片表,是指那些原有的很大資料的表,需要切分到多個資料庫的表,這樣,每個分片都有一部分資料,所有分片構成了完整的資料,
- 非分片表:一個資料庫中并不是所有的表都很大,某些表是可以不用進行切分的,非分片是相對分片表來說的,就是那些不需要進行資料切分的表,
- ER 表:關系型資料庫是基于物體關系模型(Entity-Relationship Model)之上,通過其描述了真實世界中事物與關系,Mycat 中的ER 表即是來源于此,根據這一思路,提出了基于E-R 關系的資料分片策略,子表的記錄與所關聯的父表記錄存放在同一個資料分片上,即子表依賴于父表,通過表分組(Table Group)保證資料Join 不會跨庫操作,表分組(Table Group)是解決跨分片資料join 的一種很好的思路,也是資料切分規劃的重要一條規則,
- 全域表:一個真實的業務系統中,往往存在大量的類似字典表的表,這些表基本上很少變動, 對于這類的表,在分片的情況下,當業務表因為規模而進行分片以后,業務表與這些附屬的字典表之間的關聯,就成了比較棘手的問題,所以Mycat 中通過資料冗余來解決這類表的join,即所有的分片都有一份資料的拷貝,所有將字典表或者符合字典表特性的一些表定義為全域表,資料冗余是解決跨分片資料join 的一種很好的思路,也是資料切分規劃的另外一條重要規則,
- 分片節點(dataNode):資料切分后,一個大表被分到不同的分片資料庫上面,每個表分片所在的資料庫就是分片節點(dataNode),
- 節點主機(dataHost):資料切分后,每個分片節點(dataNode)不一定都會獨占一臺機器,同一機器上面可以有多個分片資料庫,這樣一個或多個分片節點(dataNode)所在的機器就是節點主機(dataHost),為了規避單節點主機并發數限制,盡量將讀寫壓力高的分片節點(dataNode)均衡的放在不同的節點主機(dataHost),
- 分片規則(rule):前面講了資料切分,一個大表被分成若干個分片表,就需要一定的規則,這樣按照某種業務規則把資料分到某個分片的規則就是分片規則,資料切分選擇合適的分片規則非常重要,將極大的避免后續資料處理的難度,
- 全域序列號(sequence):資料切分后,原有的關系資料庫中的主鍵約束在分布式條件下將無法使用,因此需要引入外部機制保證資料唯一性標識,這種保證全域性的資料唯一標識的機制就是全域序列號(sequence),
安裝與部署
MyCAT 是使用JAVA 語言進行撰寫開發,使用前需要先安裝JAVA 運行環境(JRE),由于MyCAT 中使用了JDK7 中的一些特性,所以要求必須在JDK7 以上的版本上運行,同時Mysql建議使用5.5以上版本,5.6為宜,進入https://github.com/MyCATApache/Mycat-download,在串列中選擇一個合適自己作業系統的包下載,然后解壓在某個目錄下,Mycat是個標準的Java程式,解壓后即可運行,Linux下執行 mycat ,windows下執行 startup_nowrap.bat,
其中 bin 程式目錄,存放了啟動腳本,除了提供封裝成服務的版本之外,也提供了nowrap 的腳本命令,conf 目錄下存放組態檔,server.xml 是Mycat 服務器引數調整和用戶授權的組態檔,schema.xml 是邏輯庫定義和表以及分片定義的組態檔,rule.xml 是分片規則的組態檔,分片規則的具體一些引數資訊單獨存放為檔案,也在這個目錄下,組態檔修改,需要重啟Mycat 或者通過9066 埠reload,lib 目錄下主要存放mycat 依賴的一些jar 檔案,日志存放在logs/mycat.log 中,每天一個檔案,日志的配置是在conf/log4j.xml 中,根據自己的需要,可以調整輸出級別為debug,debug 級別下,會輸出更多的資訊,方便排查問題,
配置詳解
主要組態檔為server.xml,schema.xml,rule.xml以及相應的分片規則,
server.xml
server.xml用于配置系統引數、用戶資訊、訪問權限及SQL防火墻和SQL攔截功能等,
system 標簽
配置 Mycat 的系統引數,
<system>
<property name="nonePasswordLogin">0</property> <!-- 0為需要密碼登陸、1為不需要密碼登陸 ,默認為0,設定為1則需要指定默認賬戶-->
<property name="useHandshakeV10">1</property>
<property name="useSqlStat">0</property> <!-- 1為開啟實時統計、0為關閉 -->
<property name="useGlobleTableCheck">0</property> <!-- 1為開啟全加班一致性檢測、0為關閉 -->
<property name="sequnceHandlerType">2</property>
<property name="subqueryRelationshipCheck">false</property> <!-- 子查詢中存在關聯查詢的情況下,檢查關聯欄位中是否有分片欄位 .默認 false -->
<!--默認為type 0: DirectByteBufferPool | type 1 ByteBufferArena | type 2 NettyBufferPool -->
<property name="processorBufferPoolType">0</property>
<!--分布式事務開關,0為不過濾分布式事務,1為過濾分布式事務(如果分布式事務內只涉及全域表,則不過濾),2為不過濾分布式事務,但是記錄分布式事務日志-->
<property name="handleDistributedTransactions">0</property>
<!-- off heap for merge/order/group/limit 1開啟 0關閉 -->
<property name="useOffHeapForMerge">1</property>
<property name="memoryPageSize">64k</property>
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper協調切換 -->
<property name="useZKSwitch">false</property>
<!-- XA Recovery Log日志路徑 -->
<!--<property name="XARecoveryLogBaseDir">./</property>-->
<!-- XA Recovery Log日志名稱 -->
<!--<property name="XARecoveryLogBaseName">tmlog</property>-->
</system>user 標簽
配置Mycat的訪問用戶及權限,
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">db1,db2</property>
<!-- 表級 DML 權限設定 -->
<!--
<privileges check="false">
<schema name="db1" dml="0110" >
<table name="demotb" dml="0000"></table>
</schema>
</privileges>
-->
</user>schema.xml
schema.xml用于配置邏輯庫及邏輯表,配置邏輯表所存盤的資料節點,配置資料節點所對應的物理資料庫服務器資訊,
dataHost 標簽
定義了具體的資料庫實體、讀寫分離配置和心跳陳述句,
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="0" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS1" url="localhost:3307" user="root" password="123456" />
</writeHost>
</dataHost>- heartbeat 標簽:內指明用于和后端資料庫進行心跳檢查的陳述句,例如,MySQL可以使用
select user(),Oracle可以使用select 1 from dual等, - writehost 、readHost標簽:這兩個標簽都用于配置一組主從資料庫的相關資訊,Mycat用這兩個標簽配置的連接資訊實體化后端連接池,唯一不同的是,
writeHost配置寫實體(master)、readHost配置讀實體(salve),并且readHost為writeHost的子標簽,通過這兩個標簽可以組合讀/寫實體以滿足系統的要求,在一個dataHost內可以定義多個writeHost和readHost,但是,如果writeHost指定的后端資料庫宕機,那么這個writeHost系結的所有readHost都將不可用,另一方面,當一個writeHost宕機時系統會自動檢測到,并切換到備用的writeHost上去,
dataNode 標簽
定義了 MyCat 中的資料節點,也就是我們通常說所的資料分片,一個 dataNode 標簽就是一個獨立的資料分片,
<dataNode name="dnUser1" dataHost="localhost1" database="user" />
<dataNode name="dnUser2" dataHost="localhost1" database="user01" />
<dataNode name="dnUser3" dataHost="localhost1" database="user02" />schema 標簽
定義 MyCat 實體中的邏輯庫,MyCat 可以有多個邏輯庫,每個邏輯庫都有自己的相關配置,可以使用 schema 標簽來劃分這些不同的邏輯庫,
<schema name="schema_db1" checkSQLschema="false" sqlMaxLimit="100"></schema>
<schema name="schema_db2" checkSQLschema="false" sqlMaxLimit="100"></schema>table 標簽
定義了 MyCat 中的邏輯表,所有需要拆分的表都需要在這個標簽中定義,其中 childTable 標簽用于定義 E-R 分片的子表,通過標簽上的屬性與父表進行關聯,
<schema name="USERDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="user" primaryKey="id" dataNode="dnUser1,dnUser2,dnUser3" rule="user-mod-long">
<childTable name="user_log" primaryKey="id" joinKey="user_id"
parentKey="id">
</childTable>
</table>
<table name="area" primaryKey="area_code" type="global" dataNode="dnUser1,dnUser2,dnUser3" />
</schema>| 屬性 | 說明 |
|---|---|
| name | 該屬性定義邏輯表的表名 |
| dataNode | 該屬性定義這個邏輯表所屬的 dataNode, 該屬性的值需要和 dataNode 標簽中 name 屬性的值相互對應, |
| rule | 該屬性用于指定邏輯表要使用的規則名字,規則名字在 rule.xml 中定義,必須與 tableRule 標簽中 name 屬性屬性值一一對應 |
| ruleRequired | 該屬性用于指定表是否系結分片規則,如果配置為 true,但沒有配置具體 rule 的話 ,程式會報錯, |
| primaryKey | 該邏輯表對應真實表的主鍵 |
| type | 該屬性定義了邏輯表的型別,目前邏輯表只有“全域表”和”普通表”兩種型別,全域表定義type=”global”,不定義的就是普通表, |
| autoIncrement | 主鍵是否自增長, |
| subTables | 分表,分表目前不支持Join, |
| needAddLimit | 是否自動添加limit,默認是開啟狀態, |
這里定義了一個邏輯表user表及其子表user_log,分片規則為user-mod-long,一個全域表area,
rule.xml
定義了我們對表進行拆分所涉及到的規則定義,
tableRule標簽
屬性 name指定唯一的名字,用于標識不同的表規則,內嵌的 rule 標簽則指定對物理表中的哪一列進行拆分和使用什么路由演算法,
<tableRule name="user-mod-long">
<rule>
<!-- 指定使用表中的哪個列進行分片 -->
<columns>id</columns>
<!-- 指定表的分片演算法,取值為<function>標簽的name屬性 -->
<algorithm>mod-long</algorithm>
</rule>
</tableRule>function標簽
定義了tableRule中使用的分片演算法,
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function> 常用的幾個分片演算法:
PartitionByMod:簡單取模,直接通過列值進行取模得出分片位置PartitionByHashMod:哈希取模,先將列值進行hash運算之后再取模得出分片位置PartitionByFileMap:分片列舉,根據列舉值對資料進行分片,例如在異地多活的場景中通過地區id進行資料分片的場景PartitionByPrefixPattern:字串范圍取模,根據長字串的前面幾位進行取模分片
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/247230.html
標籤:其他
上一篇:MySQL學習:操作資料庫陳述句