有序集合 sorted set (下面我們叫zset 吧) 有兩種編碼方式:壓縮串列 ziplist 和跳表 skiplist,
編碼一:ziplist
zset 在 ziplist 中,成員(member)和分數(score)是挨在一起的,元素按照分數從小到大存盤,
舉個例子,我們用以下命令創建一個zset:
redis> ZADD key 26.1 z 1 a 2 b
(integer) 3
那么這個zset的結構大致如下:
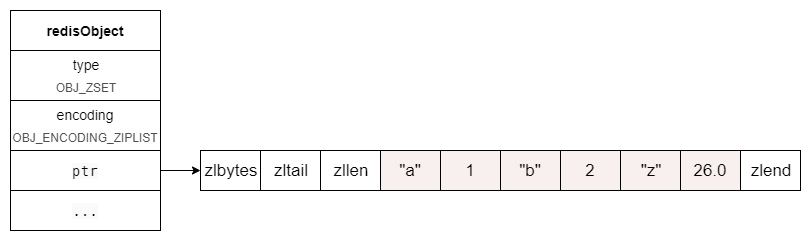
下面我們來分析一下 zscore 命令的原始碼,進一步了解 zset 是如何利用 ziplist 存盤的
int zsetScore(robj *zobj, sds member, double *score) {
// ...
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
if (zzlFind(zobj->ptr, member, score) == NULL) return C_ERR;
}
// ...
return C_OK;
}
unsigned char *zzlFind(unsigned char *zl, sds ele, double *score) {
// eptr 是 member 的指標,sptr 是 score 的指標
unsigned char *eptr = ziplistIndex(zl,0), *sptr;
// 遍歷 ziplist
while (eptr != NULL) {
// 因為 member 和 score 是挨著存盤的,所以獲取 member 的下一個節點就是 score 啦
sptr = ziplistNext(zl,eptr);
serverAssert(sptr != NULL);
// 對比當前的 member 和要查詢的 member 是否相等
if (ziplistCompare(eptr,(unsigned char*)ele,sdslen(ele))) {
// 如果相等,則獲取分數
if (score != NULL) *score = zzlGetScore(sptr);
return eptr;
}
// 不相等則繼續往下遍歷
eptr = ziplistNext(zl,sptr);
}
return NULL;
}
// 獲取分數
double zzlGetScore(unsigned char *sptr) {
unsigned char *vstr;
unsigned int vlen;
long long vlong;
char buf[128];
double score;
serverAssert(sptr != NULL);
// ziplistGet 通過 sptr 指標獲取值,根據節點的編碼(前文有說到ziplist節點的編碼) 對引數賦值
// 如果是字串,則賦值到 vstr; 如果是整數,則賦值到 vlong,
serverAssert(ziplistGet(sptr,&vstr,&vlen,&vlong));
if (vstr) {
// 如果是字串,那么存的就是浮點數
memcpy(buf,vstr,vlen);
buf[vlen] = '\0';
// 字串轉換成浮點數
score = strtod(buf,NULL);
} else {
// 整數型別就直接賦值
score = vlong;
}
return score;
}
編碼二:skiplist
跳表的實作
skiplist 編碼的底層實作是跳表,
下面是跳表的結構圖 (圖片來自 《Redis 設計與實作》圖片集 )
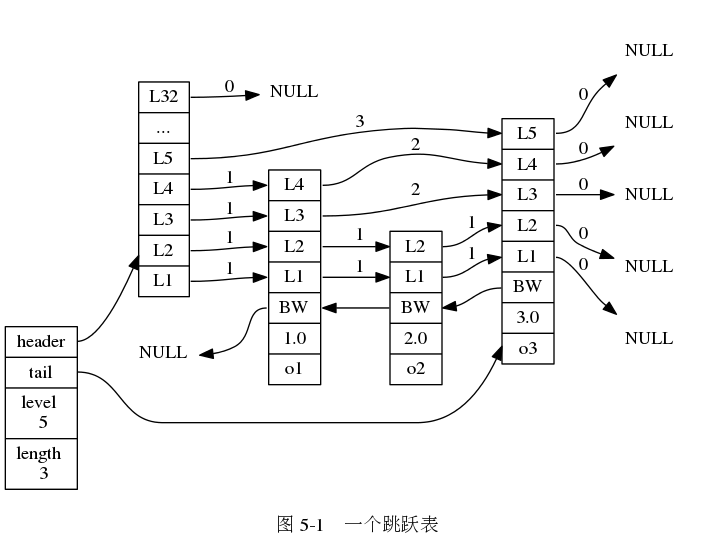
- 圖中最左部分就是
zskiplist結構,其代碼實作如下(server.h):
typedef struct zskiplist {
// 頭指標和尾指標,指向頭尾節點
struct zskiplistNode *header, *tail;
// 跳表的節點數(不包含頭結點,空跳表也會包含頭結點)
unsigned long length;
// 所有節點中,最大的層數
int level;
} zskiplist;
- 圖中右邊的四個節點,就是跳表節點
zskiplistNode,其代碼實作如下(server.h):
typedef struct zskiplistNode {
// 成員
sds ele;
// 分數
double score;
// 后退指標,指向前一個節點
struct zskiplistNode *backward;
// 層,每個節點可能有很多層,每個層可能指向不同的節點
struct zskiplistLevel {
// 前進指標,指向下一個節點
struct zskiplistNode *forward;
// 跟下一個節點之間的跨度
unsigned long span;
} level[];
} zskiplistNode;
跳表最重要的一個地方就是層 level,為什么這么說呢?
假設zset 用鏈表有序存盤,如果我們要查找資料,只能從頭到尾遍歷,時間復雜度是 \(O(n)\),效率很低,

有什么辦法提高效率呢?我們可以在上面添加一層索引,
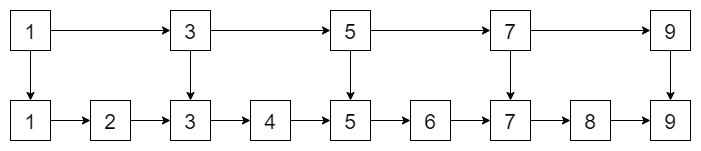
可以看出,我們遍歷的性能變高了,例如我們想找到 6,先遍歷第一層,5 到 7 之間,再往下探,就能找到 6 了!
有讀者就發現了,如果資料量很大,那找起來也很慢,
是的,那么怎么解決呢?再往上加索引唄!
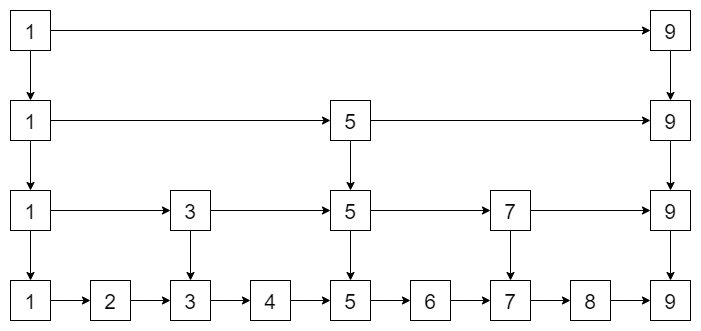
這不,鏈表就變成了跳表了!而上面說的層,就是這些索引啦!最終跳表的查找時間復雜度是 \(O(logn)\)
我們來看看 zrange 命令的核心實作,來感受一下跳表的遍歷吧
zskiplistNode* zslGetElementByRank(zskiplist *zsl, unsigned long rank) {
zskiplistNode *x;
unsigned long traversed = 0;
int i;
// 層頭結點開始
x = zsl->header;
// 層從高到低
for (i = zsl->level-1; i >= 0; i--) {
// 只要遍歷的數沒有達到 rank,就一直遍歷
while (x->level[i].forward && (traversed + x->level[i].span) <= rank)
{
// 每次加上層的跨度
traversed += x->level[i].span;
// 往前走
x = x->level[i].forward;
}
// 如果這一層走完還沒到 rank,那就往下層走,如果還是找不到就繼續走,直到走到最底層
if (traversed == rank) {
return x;
}
}
return NULL;
}
zset 的結構
skiplist 編碼的 zset 的結構定義如下:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
結構中包含了一個字典和一個跳表,為什么用了跳表還需要字典呢?
命令zscore這種單找一個值的,如果只用跳表的話,那么查找的時間復雜度是 \(O(logn)\),加上一個字典可以把時間復雜度縮減為 \(O(n)\),
那么肯定有同學就會說,加一個字典會浪費了很多空間,
的確,多加一個字典肯定會多占用一定的空間,空間換時間是一種常見的做法,不過字典的值指向的物件跟跳表的物件是共用的,
下圖是一個 zset 的示例,為了方便,把他們指向的字串物件都分別畫出來了,實際上是共享的,(圖片來自 《Redis 設計與實作》圖片集 )
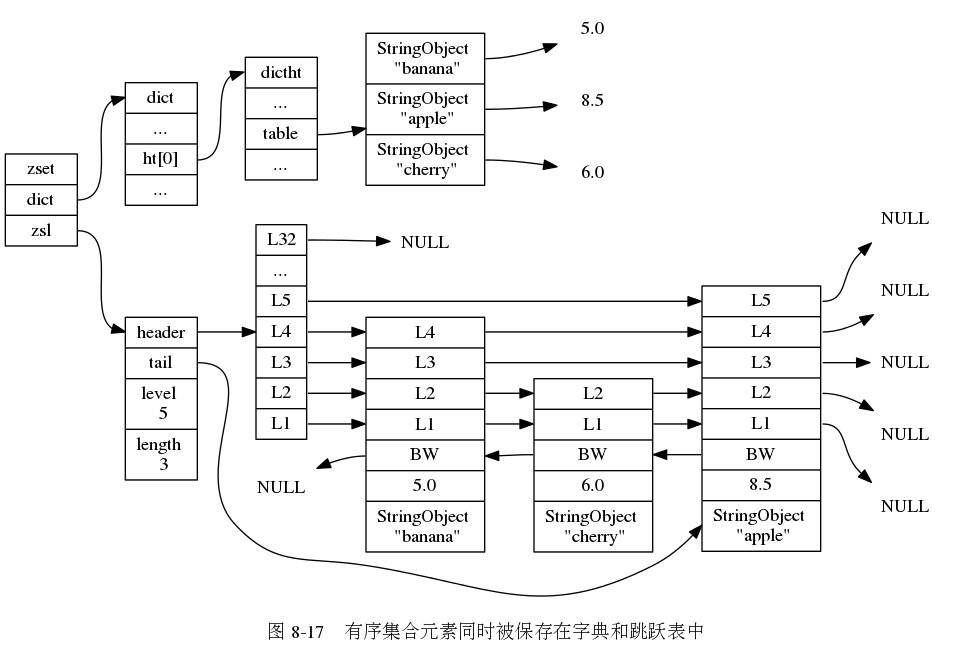
原始碼分析
我們來看看 skiplist 編碼下的 zscore 如何實作吧,
int zsetScore(robj *zobj, sds member, double *score) {
// 前面其他 ziplist 編碼的就省略了...
// if ...
else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
// 直接通過 dict 查找,時間復雜度復雜度 O(1)
dictEntry *de = dictFind(zs->dict, member);
if (de == NULL) return C_ERR;
*score = *(double*)dictGetVal(de);
}
// ...
return C_OK;
}
編碼轉換
當有序集合物件可以同時滿足以下兩個條件時,物件使用 ziplist 編碼:
- 有序集合保存的元素數量小于128個(可通過
zset-max-ziplist-entries修改配置); - 有序集合保存的所有元素成員的長度都小于64位元組(可通過
zset-max-ziplist-value修改配置);
不能滿足以上兩個條件的有序集合物件將使用 skiplist 編碼,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/249420.html
標籤:其他
下一篇:Redis-第三章節-安裝和配置