目錄
- 簡述
- 第N高薪水(連續排名,同薪同名)
- 單表查詢
- 子查詢方式1
- 子查詢方式2
- 自連接
- 笛卡爾積
- 自定義變數
- 開窗函式
- 部門前n高薪水(連續排名,同薪同名)
- 子查詢方式
- 連接查詢
- 自定義變數
- 開窗函式
- 第N高薪水(連續排名,同薪同名)
簡述
最近在刷題和作業中總會遇到前n高,第n高的問題,匯總一下以便日后查看,
排名3種場景(以薪水為例):
- 連續排名,同薪不同名,3000、2000、2000、1000的排名為1-2-3-4
- 不連續排名,同薪同名,3000、2000、2000、1000的排名為1-2-2-4
- 連續排名,同薪同名,3000、2000、2000、1000的排名為1-2-2-3
下面的兩個例子都以連續排名,同薪同名的情況舉例
第N高薪水(連續排名,同薪同名)

如表中所示,如果存在第N高的薪水則回傳Salary,如果不存在那么查詢應該回傳NULL,
單表查詢
- 解題思路
全域排名,不分組,所以我們可以用ORDER BY排序加LIMIT N,M限制(M表示在限制條數之后的offset記錄,LIMIT M OFFSET N),排名第N高意思是LIMIT N-1,1,但是LIMIT后面只接受正整數或者單一變數,不能用運算式,所以在函式中需要先SET N = N - 1
同薪同名且連續排名,意味著需要去重,我們可以用GROUP BY按薪水分組后再ORDER BY或者DISTINCT去重,
MySQL中的LIMIT用法詳解
- 基本語法:
SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset- LIMIT子句用于select中,對輸出結果集的行數進行約束,LIMIT接受一個或兩個數字引數,引數必須是一個整數常量,offset表示偏移量(指向資料記錄的游標),rows表示查詢限定回傳的最大記錄數,當offset引數省略時,默認為0,即LIMIT 3 等同于LIMIT 0,3,
SELECT * FROM table LIMIT 3, 4;回傳第4-7行SELECT * FROM table LIMIT 3;回傳前3行
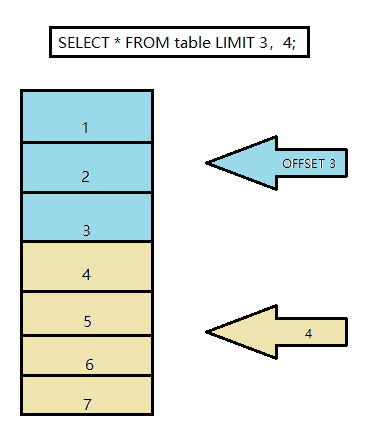
- 代碼片段
CREATE FUNCTION getNHighestSalary(N INT) RETURNS INT
BEGIN
SET N := N-1;
IF (N < 0) THEN
RETURN NULL;
ELSE
RETURN (
SELECT DISTINCT salary FROM employee
-- GROUP BY salary
ORDER BY salary DESC
LIMIT N, 1
);
END IF;
END
子查詢方式1
- 解題思路
先查出前n高的薪水,再從中查詢最低的薪水(即第n高的薪水),并用COUNT(1)累加用來判斷是否有第n高的薪水 ,考慮會有相等的薪水所以第一重查詢用DISTINCT去重, - 代碼片段
CREATE FUNCTION getNHighestSalary(N INT) RETURNS INT
BEGIN
RETURN(
SELECT IF(count < N, NULL, min) AS Salary
FROM
(
SELECT MIN(Salary) AS min, COUNT(1) AS count
FROM
(
SELECT DISTINCT Salary
FROM Employee ORDER BY Salary DESC LIMIT N
) a
) b
);
END
子查詢方式2
- 解題思路
排名第N高意味著表中存在N-1個比其更高的薪水(去重前提下),
聯表查詢出比當前薪水高的有幾個,如果這個數量等于N-1,那么回傳該薪水, - 代碼片段
CREATE FUNCTION getNHighestSalary(N INT) RETURNS INT
BEGIN
RETURN(
SELECT DISTINCT(e.salary)
FROM Employee e
WHERE (
SELECT
COUNT(DISTINCT salary)
FROM Employee e1 WHERE e1.salary > e.salary
) = N - 1
);
END
自連接
- 解題思路
自連接條件為表1的Salary小于表2的Salary,以表1的Salary分組,統計表2的Salary的去重個數
考慮到第一名的表2的Salary為空,所以采用LEFT JOIN,當去重個數等于N-1時就是要輸出的排名(也可以用JOIN,連接條件為<=,COUNT(DISTINCT e2.Salary) = N) - 代碼片段
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
SELECT
e1.salary
FROM
employee e1 LEFT JOIN employee e2 ON e1.salary < e2.salary
GROUP BY
e1.salary
HAVING
count(DISTINCT e2.salary) = N - 1
);
END
笛卡爾積
- 解題思路
跟子查詢方式2相似,不再贅述, - 代碼片段
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
SELECT
e1.salary
FROM
employee e1, employee e2
WHERE
e1.salary <= e2.salary
GROUP BY
e1.salary
HAVING
count(DISTINCT e2.salary) = N
);
END
自定義變數
- 解題思路
自定義兩個變數,@s存盤工資,@r存盤排名,先按工資排序,查詢時更新變數值,當工資相等時排名不變,不相等則排名加一 - 代碼片段
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
SELECT
DISTINCT salary
FROM
(SELECT
salary, @r:=IF(@s=salary, @r, @r+1) AS rnk, @s:= salary
FROM
employee, (SELECT @r:=0, @s:=NULL)init
ORDER BY
salary DESC) tmp
WHERE rnk = N
);
END
開窗函式
- 解題思路
mysql8.0以上版本可以用開窗函式,效率是最好的,常用的三種排名函式如下:
ROW_NUMBER():連續排名,同薪不同名,3000、2000、2000、1000的排名為1-2-3-4RANK():不連續排名,同薪同名,3000、2000、2000、1000的排名為1-2-2-4DESENSE_RANK():連續排名,同薪同名,3000、2000、2000、1000的排名為1-2-2-3
這三個函式要和OVER()一起使用,OVER()中的引數通常是PARTITION BY和ORDER BY,例題情況是第三種,所以采用DENSE_RANK(),
- 代碼示例
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
SELECT
DISTINCT salary
FROM
(SELECT
salary, dense_rank() over(ORDER BY salary DESC) AS rnk
FROM
employee) tmp
WHERE rnk = N
);
END
部門前n高薪水(連續排名,同薪同名)


如表中所示,如果存在部門前N高的薪水則回傳DepartmentId + Salary,如果不存在那么查詢應該回傳NULL,因為只考慮部門和薪水,所以還是連續排名,同薪同名,
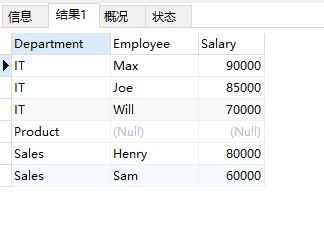
子查詢方式
- 解題思路(和第N高薪水的子查詢方式2類似)
工資前N高意味著:有不超過N-1個人的工資比查詢結果的工資高,例如求前三高的工資,即有不超過2個人(查詢子條件為<=2或<3)的工資比查詢結果的工資高(有0個人比第一高工資高;有1個人比第二高工資高;有2個人比第三高工資高) - 代碼示例
SELECT
d.Name AS 'Department', e1.Name AS 'Employee', e1.Salary
FROM Employee e1
RIGHT JOIN Department d ON e1.DepartmentId = d.Id
WHERE
3 > (SELECT COUNT(DISTINCT e2.Salary)
FROM Employee e2
WHERE e2.Salary > e1.Salary
AND e1.DepartmentId = e2.DepartmentId
)
GROUP BY e1.Salary
ORDER BY d.`Name`, e1.Salary DESC
;
連接查詢
- 解題思路
能用子查詢解決的問題一般都能用連接來解決 - 代碼示例
SELECT
d.name as department, e1.name as employee, e1.salary as salary
FROM
Department d LEFT JOIN Employee e1 on d.id = e1.departmentid
LEFT JOIN Employee e2 on e1.departmentid = e2.departmentid and e1.salary<=e2.salary
GROUP BY
d.name, e1.Salary
HAVING
count(distinct e2.salary)<4
ORDER BY
d.name, e1.salary DESC
自定義變數
- 解題思路
自定義三個變數,@s存盤工資,@r存盤排名,@d存盤部門ID,先按部門和工資排序,查詢時更新變數值,
(1)當前部門ID與@d相同(@d=DepartmentId),則代表是在同一部門中進行的排名,當工資相等(@s=Salary)時排名不變(@r:=@r),不相等則排名加一(@r:=@r+1);
(2)當前部門ID與@d不相同(@d!=DepartmentId),則說明@d需重新賦值(@d=DepartmentId),排名也要重新開始,即@r:=1, - 代碼示例
SELECT
d. NAME department,
t. NAME employee,
salary
FROM
(
SELECT
*, @r :=IF (DepartmentId = @d, IF (Salary = @s, @r, @r + 1), 1) AS rnk,
@d := DepartmentId,
@s := Salary
FROM employee, (SELECT @s := NULL,@d := NULL, @r := 0 ) init
ORDER BY DepartmentId, Salary DESC
) t
RIGHT JOIN department d ON t.DepartmentId = d.Id
WHERE t.rnk <= N OR t.rnk IS NULL
GROUP BY d.`Name`, salary
ORDER BY DepartmentId, Salary DESC
開窗函式
- 解題思路
又到了快樂的開窗函式,因為是同薪同名,連續排名,所以還是用DENSE_RANK(),因為求的是部門前N高薪水,所以按部門分組再按薪水排序,那么開窗函式的使用就是:DENSE_RANK() OVER(PARTITION BY departmentid ORDER BY salary DESC), - 代碼示例
SELECT
d.`Name`, tmp.`Name`, tmp.Salary
FROM(
SELECT
e1.DepartmentId, e1.`Name`, e1.Salary,
DENSE_RANK() OVER(PARTITION BY e1.DepartmentId ORDER BY e1.Salary DESC) rnk
FROM employee e1 ) tmp
RIGHT JOIN department d
ON d.Id = tmp.DepartmentId
WHERE rnk <= N OR t.rnk IS NULL
GROUP BY d.name, tmp.Salary
;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/250581.html
標籤:MySQL
下一篇:實用sql整理