判斷某個面一條不合格的邏輯是
①頭或尾小于1 =不合格
②除去頭尾,中間任意兩個連續點小于1 =不合格
其他情況合格
判斷某個面合格的邏輯:
三條資料有兩潭訓兩條以上不合格就是不合格
create table #A(
id varchar(200), --面別
iid int, --面別的每一條
fz1 varchar(50),
fz2 varchar(50),
fz3 varchar(50),
fz4 varchar(50),
fz5 varchar(50),
fz6 varchar(50),
fz7 varchar(50),
fz8 varchar(50),
fz9 varchar(50),
fz10 varchar(50),
fz11 varchar(50),
fz12 varchar(50),
iidishg varchar(50),--每個面的每一條是否合格
idishg varchar(50)--整個面是否合格
)
insert into #A(id,iid,fz1,fz2,fz3,fz4,fz5,fz6,fz7,fz8,fz9,fz10,fz11,fz12,iidishg,idishg)
values
('反面', '1','4.53', '5.67', '5.08', '4.25', '3.7', '0.34', '', '','','','','','', ''),
('反面', '2','4.76', '5.67', '4.32', '4.06', '4.17', '4.8', '', '','','','','', '', ''),
('反面', '3','0.22', '4.6', '4.84', '4.33', '1.14', '5.6', '','','','','','','',''),
('正面', '1','6.67', '4.84', '6.22', '5.2', '4.14', '5.76', '5.8', '4.38', '0.55', '6.96', '5.44', '5.6', '', ''),
('正面', '2','6.18', '5.85', '4.13', '0.19', '4.25', '4.77', '5.03', '0.32', '4.47', '5.67', '5.64', '5.21', '', ''),
('正面', '3','6.41', '4.36', '0.22', '4.45', '4.06', '8.61', '5.42', '0.24', '0.29', '6.28', '4.38', '9.24', '','')
select * from #A
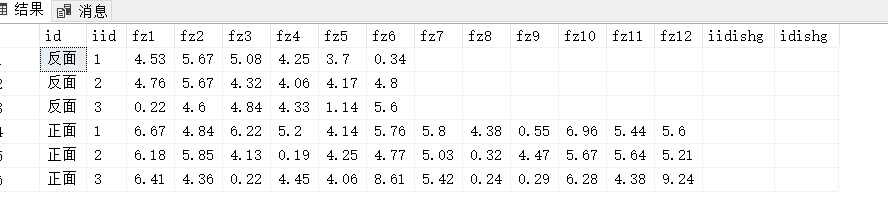
需要實作的效果:
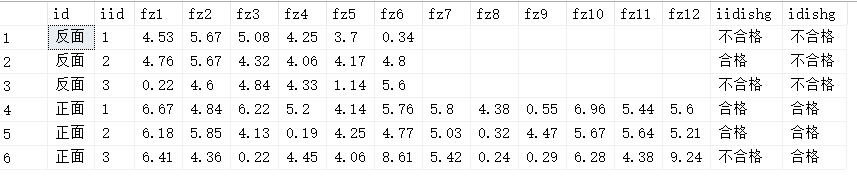
有沒有大佬知道怎么可以實作
uj5u.com熱心網友回復:
有沒有大佬有更簡單的方法,目前我的方法是
select id,iid,fz1,fz2,fz3,fz4,fz5,fz6,fz7,fz8,fz9,fz10,fz11,fz12,lv,REPLACE(lv,2,'') as ylv,left(REPLACE(lv,2,''),1) as head,right(REPLACE(lv,2,''),1) as tail,
right(left(REPLACE(lv,2,''),len(REPLACE(lv,2,''))-1),len(left(REPLACE(lv,2,''),len(REPLACE(lv,2,''))-1))-1) as middle,
case when left(REPLACE(lv,2,''),1) =1 or right(REPLACE(lv,2,''),1)=1 then '不合格'
when left(REPLACE(lv,2,''),1) =0 and right(REPLACE(lv,2,''),1)=0 and
right(left(REPLACE(lv,2,''),len(REPLACE(lv,2,''))-1),len(left(REPLACE(lv,2,''),len(REPLACE(lv,2,''))-1))-1) like '%11%' then '不合格'
else '合格' end as iidishg
into #B
from
(select *,lv=(case when cast(fz1 as float)<1 then '1' else '0' end)+
(case when fz2='' then '2' when cast(fz2 as float)<1 then '1' else '0' end)+
(case when fz3='' then '2' when cast(fz3 as float)<1 then '1' else '0' end)+
(case when fz4='' then '2' when cast(fz4 as float)<1 then '1' else '0' end)+
(case when fz5='' then '2' when cast(fz5 as float)<1 then '1' else '0' end)+
(case when fz6='' then '2' when cast(fz6 as float)<1 then '1' else '0' end)+
(case when fz7='' then '2' when cast(fz7 as float)<1 then '1' else '0' end)+
(case when fz8='' then '2' when cast(fz8 as float)<1 then '1' else '0' end)+
(case when fz9='' then '2' when cast(fz9 as float)<1 then '1' else '0' end)+
(case when fz10='' then '2' when cast(fz10 as float)<1 then '1' else '0' end)+
(case when fz11='' then '2' when cast(fz11 as float)<1 then '1' else '0' end)+
(case when fz12='' then '2' when cast(fz12 as float)<1 then '1' else '0' end) from #A
)t
select a.id,iid,fz1,fz2,fz3,fz4,fz5,fz6,fz7,fz8,fz9,fz10,fz11,fz12,iidishg,case when isnull(b.idishg,0)>=2 then '不合格' else '合格' end as isishg
from #B a
left join (select id,count(iidishg) as idishg from #B where iidishg='不合格' group by id) b on a.id=b.id
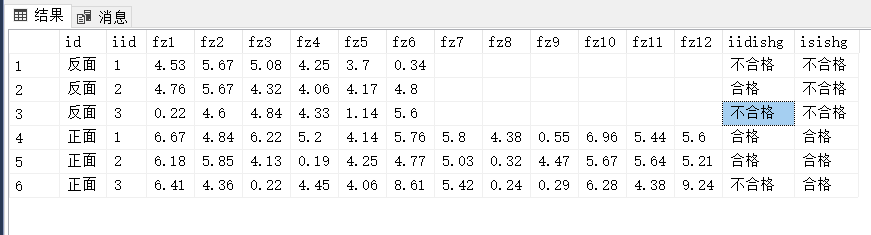
uj5u.com熱心網友回復:
/*
用你的資料
首先查詢把你的12列變成12行,并增加一個序號列(x,y)
然后計算值不為空的最大一個id(ma)
然后計算向前偏移一個的值,用來判斷相鄰的la
接著就是判斷得到結果rst
第一個( x=1 AND y<1.0)
最后一個( x=ma AND y<1.0)
相鄰的(y<1.0 AND la<1.0)
然后按id分組統計不合格的個數得到rst2
*/
SELECT *,IIF(SUM(IIF(rst='不合格',1,0)) OVER(PARTITION BY id) >= 2 ,'不合格','合格') AS rst2 FROM #A OUTER APPLY
(
SELECT MIN(IIF( ( x=1 AND y<1.0) OR ( x=ma AND y<1.0) OR (y<1.0 AND la<1.0) ,'不合格' ,'合格') ) AS rst
FROM
(
SELECT
x,
y,
MAX(x) OVER(PARTITION BY id,iid) AS ma,
LAG(y) OVER(PARTITION BY id,iid ORDER BY x) AS la
FROM (
VALUES
(1,fz1),(2,fz2),(3,fz3),(4,fz4),(5,fz5),(6,fz6),(7,fz7),(8,fz8),(9,fz9),(10,fz10),(11,fz11),(12,fz12)
) AS a(x,y)
WHERE y<>''
)a
) b
uj5u.com熱心網友回復:
貌似也挺復雜的
with cte_1
as
(select id,iid,cast(fz_value as decimal(12,2)) as fz_value,cast(replace(fz_seq,'fz','') as int) as fz_seq,
count(*) over (partition by id,iid) as fz_qty
from
(select id,iid,fz_value,fz_seq
from #A
unpivot (fz_value for fz_seq in ([fz1],[fz2],[fz3],[fz4],[fz5],[fz6],[fz7],[fz8],[fz9],[fz10],[fz11],[fz12])) B) as C
where fz_value<>''),
cte_2
as
(select *,count(*) over (partition by id) as side_qty
from
(select id,iid,'不合格' as line_result from cte_1
where (fz_seq=1 or fz_seq=fz_qty) and fz_value<1
union all
select id,iid,'不合格' from cte_1 as A
where fz_seq<>1 and fz_seq<>fz_qty
and fz_value<1
and exists (select 1 from cte_1 where id=A.id and iid=A.iid and fz_value<1 AND A.fz_seq=fz_seq-1 and fz_seq<>1 and fz_seq<>fz_qty)) as A)
select A.*,
isnull(B.line_result,'合格') as line_result,
case when C.side_qty>1 then '不合格' else '合格' end as side_result
from #A as A
left join cte_2 as B on A.id=B.id and A.iid=B.iid
left join (select distinct id,side_qty from cte_2) as C on A.id=C.id
uj5u.com熱心網友回復:
直接寫,雖然有點長,但邏輯也簡單
create table #A(
id varchar(200), --面別
iid int, --面別的每一條
fz1 varchar(50),
fz2 varchar(50),
fz3 varchar(50),
fz4 varchar(50),
fz5 varchar(50),
fz6 varchar(50),
fz7 varchar(50),
fz8 varchar(50),
fz9 varchar(50),
fz10 varchar(50),
fz11 varchar(50),
fz12 varchar(50),
iidishg varchar(50),--每個面的每一條是否合格
idishg varchar(50)--整個面是否合格
)
insert into #A(id,iid,fz1,fz2,fz3,fz4,fz5,fz6,fz7,fz8,fz9,fz10,fz11,fz12,iidishg,idishg)
values
('反面', '1','4.53', '5.67', '5.08', '4.25', '3.7', '0.34', NULL, null,null,null,null,null,null, null),
('反面', '2','4.76', '5.67', '4.32', '4.06', '4.17', '4.8', null, null,null,null,null,null, null, null),
('反面', '3','0.22', '4.6', '4.84', '4.33', '1.14', '5.6', null,null,null,null,null,null,null,null),
('正面', '1','6.67', '4.84', '6.22', '5.2', '4.14', '5.76', '5.8', '4.38', '0.55', '6.96', '5.44', '5.6', null, null),
('正面', '2','6.18', '5.85', '4.13', '0.19', '4.25', '4.77', '5.03', '0.32', '4.47', '5.67', '5.64', '5.21', null, null),
('正面', '3','6.41', '4.36', '0.22', '4.45', '4.06', '8.61', '5.42', '0.24', '0.29', '6.28', '4.38', '9.24', null,null)
;
WITH t AS (SELECT id, iid, fz1, fz2, fz3, fz4, fz5, fz6, fz7, fz8, fz9, fz10, fz11, fz12,
COALESCE(fz12, fz11, fz10, fz9, fz8, fz7, fz6, fz5, fz4, fz3, fz2, fz1) fzlast
FROM #A),
t2 AS (SELECT *,
CASE WHEN CAST(fz1 AS DECIMAL) < 1
OR CAST(t.fzlast AS DECIMAL) < 1
OR (CAST(fz1 AS DECIMAL) < 1 AND CAST(fz2 AS DECIMAL) < 1)
OR (CAST(fz2 AS DECIMAL) < 1 AND CAST(fz3 AS DECIMAL) < 1)
OR (CAST(fz3 AS DECIMAL) < 1 AND CAST(fz4 AS DECIMAL) < 1)
OR (CAST(fz4 AS DECIMAL) < 1 AND CAST(fz5 AS DECIMAL) < 1)
OR (CAST(fz5 AS DECIMAL) < 1 AND CAST(fz6 AS DECIMAL) < 1)
OR (CAST(fz6 AS DECIMAL) < 1 AND CAST(fz7 AS DECIMAL) < 1)
OR (CAST(fz7 AS DECIMAL) < 1 AND CAST(fz8 AS DECIMAL) < 1)
OR (CAST(fz8 AS DECIMAL) < 1 AND CAST(fz9 AS DECIMAL) < 1)
OR (CAST(fz9 AS DECIMAL) < 1 AND CAST(fz10 AS DECIMAL) < 1)
OR (CAST(fz10 AS DECIMAL) < 1 AND CAST(fz11 AS DECIMAL) < 1)
OR (CAST(fz11 AS DECIMAL) < 1 AND CAST(fz12 AS DECIMAL) < 1) THEN '不合格'
ELSE '合格'
END iidishg
FROM t)
SELECT *,
CASE WHEN (SELECT COUNT(*)FROM t2 b WHERE a.id = b.id AND b.iidishg = '不合格') > 1 THEN '不合格'
ELSE '合格'
END idishg
FROM t2 a;
DROP TABLE #A
uj5u.com熱心網友回復:

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/251175.html
標籤:疑難問題