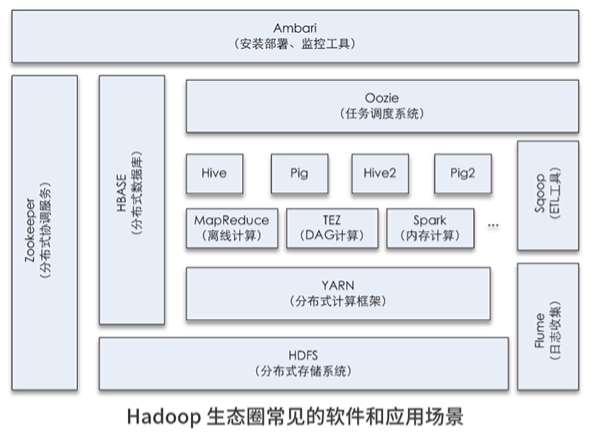
概論
Hadoop是Apache下的開源專案
資料存盤:
HDFS 分布式檔案系統,負責存盤資料,資料分散存盤
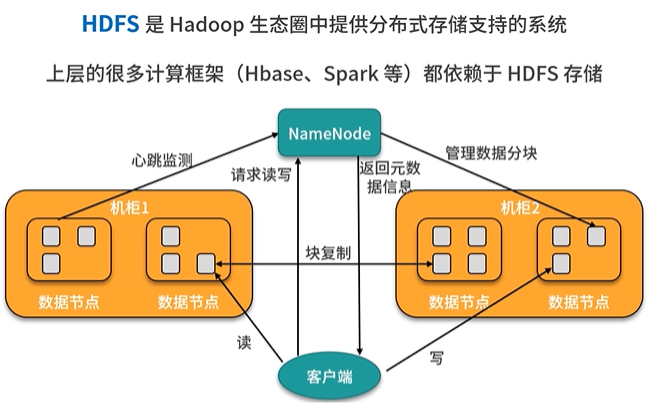
NameNode
管理節點,存盤元資料(檔案對應的資料塊位置、檔案大小、檔案權限等資訊)
同時負責讀寫調度和存盤分配
DataNode
資料存盤節點,每個資料塊會根據設定的副本數進行分級復制,保證同一個檔案的每個資料塊副本都在不同機器上
資料分析:MapReduce計算引擎
離線計算(非實時計算)
MapRedue(一代)
分布式計算(多臺運算加速)
Map階段
多臺機器同時讀取這個檔案內容的一個部分
Reducer階段
將Map階段輸出結果整合輸出
Tez、Spark(二代)
Yarn(分布式資源管理器)
解決Hadoop擴展性
支持CPU和記憶體兩種資源管理
資源管理由ResourceManager(RM)、ApplicationMaster(AM)和NodeManager(NM)完成
RM負責對各個NM上的資源進行統一管理和調度
NM負責對資源供給和隔離
當用戶提交一個應用程式時,會創建一個用以跟蹤和管理這個程式的AM,它負責向RM申請資源,并要求NM啟動指定資源的任務,這就是YARN的基本運行機制,
Yarn 作為一個通用的分布式資源管理器,它可以管理多種計算模型,如 Spark、Storm、MapReduce 、Flink 等都可以放到 Yarn 下進行統一管理,
Spark(記憶體計算)
Spark 提供了記憶體中的分布式計算能力,相比傳統的MapReduce 大資料分析效率更高、運行速度更快,總結一句話:以記憶體換效率,
傳統的MapReduce 計算程序的每一個操作步驟發生在記憶體中,但產生的中間結果會儲存在磁盤里,下一步操作時又會將這個中間結果呼叫到記憶體中,如此回圈,直到分析任務最終完成,這就會產生讀取成本,造成效率低下,
而Spark 在執行分析任務中,每個步驟也是發生在記憶體之中,但中間結果會直接進入下一個步驟,直到所有步驟完成之后才會將最終結果寫入磁盤,也就是說Spark 任務在執行程序中,中間結果不會“落地”,這就節省了大量的時間,
少量資料看不出來效率差別
HBase(分布式列存盤資料庫)
基于面向列存盤(又叫非關系型資料庫、NoSQL)基于HDFS
實作了資料即是索引,因此,它的最大優點是查詢速度快,這對資料完整性要求不高的大資料處理領域,比如互聯網
Hbase繼承了列存盤的特性,它非常適合需對資料進行隨機讀、寫操作、比如每秒對PB級資料進行幾千次讀、寫訪問是非常簡單的操作,其次,Hbase構建在HDFS之上,其內部管理的檔案全部存盤在HDFS中,這使它具有高度容錯性和可擴展性,并支持Hadoop mapreduce程式設計模型,
大資料適用于列存盤
Hive(資料倉庫)
Hive 定義了一種類似SQL 的查詢語言(HQL),它可以將SQL 轉化為MapReduce 任務在Hadoop 上執行,這樣,小李就可以用更簡單、更直觀的語言去寫程式了,
Oozie(作業流調度器)
針對多個作業查詢腳本任務調度
Oozie 是一個基于作業流引擎的調度器,它其實就是一個運行在Java Servlet 容器(如Tomcat)中的Javas Web 應用,你可以在它上面運行Hadoop 的Map Reduce 和Pig 等任務,
對于Oozie 來說,作業流就是一系列的操作(如Hadoop 的MR,Pig 的任務、Shell 任務等),通過Oozie 可以實作多個任務的依賴性,也就是說,一個操作的輸入依賴于前一個任務的輸出,只有前一個操作完全完成后,才能開始第二個,
Oozie 作業流通過hPDL 定義(hPDL 是一種XML 的流程定義語言),作業流操作通過遠程系統啟動任務,當任務完成后,遠程系統會進行回呼來通知任務已經結束,然后再開始下一個操作,
Sqoop 與Pig
把原來存盤在MySQL 中的資料匯入Hadoop 的HDFS 上,是否能實作呢?這當然可以,通過Sqoop(SQL-to-Hadoop)就能實作,它主要用于傳統資料庫和Hadoop 之間傳輸資料,資料的匯入和匯出本質上是MapreDuce 程式,充分利用了MR 的并行化和容錯性,

通過Hive 可以把腳本和SQL 語言翻譯成MapReduce 程式,扔給計算引擎去計算,Pig 與Hive 類似,它定義了一種資料流語言,即Pig Latin,它是MapReduce 編程的復雜性的抽象,Pig Latin 可以完成排序、過濾、求和、關聯等操作,支持自定義函式,Pig 自動把Pig Latin 映射為MapReduce 作業,上傳到集群運行,減少用戶撰寫Java 程式的苦惱,
Flume(日志收集工具)

- Flume 資料流提供對日志資料進行簡單處理的能力,如過濾、格式轉換等,
- Flume 還具有能夠將日志寫往各種資料目標(檔案、HDFS、網路)的能力,
在Hadoop 平臺,我們主要使用的是通過Flume 將資料從源服務器寫入Hadoop 的HDFS 上,
Kafka(分布式訊息佇列)
類似生產者、消費者問題
可以實時的處理大量資料以滿足各種需求場景:比如基于 Hadoop 平臺的資料分析、低時延的實時系統、Storm/Spark 流式處理引擎等,
ZooKeeper(分布式協作服務)
雙機熱備架構來說,雙機熱備主要用來解決單點故障問題,傳統的方式是采用一個備用節點,這個備用節點定期向主節點發送ping 包,主節點收到ping 包以后向備用節點發送回復資訊,當備用節點收到回復的時候就會認為當前主節點運行正常,讓它繼續提供服務,而當主節點故障時,備用節點就無法收到回復資訊了,此時,備用節點就認為主節點宕機,然后接替它成為新的主節點繼續提供服務,
這種傳統解決單點故障的方法,雖然在一定程度上解決了問題,但是有一個隱患,就是網路問題,可能會存在這樣一種情況:主節點并沒有出現故障,只是在回復回應的時候網路發生了故障,這樣備用節點就無法收到回復,那么它就會認為主節點出現了故障;接著,備用節點將接管主節點的服務,并成為新的主節點,此時,集群系統中就出現了兩個主節點(雙Master 節點)的情況,雙Master 節點的出現,會導致集群系統的服務發生混亂,這樣的話,整個集群系統將變得不可用,為了防止出現這種情況,就需要引入ZooKeeper 來解決這種問題,
ZooKeeper 是如何來解決這個問題的呢,這里以配置兩個節點為例,假定它們是“節點A”和“節點B”,當兩個節點都啟動后,它們都會向ZooKeeper 中注冊節點資訊,我們假設“節點A”鎖注冊的節點資訊是“master00001”,“節點B”注冊的節點資訊是“master00002”,注冊完以后會進行選舉,選舉有多種演算法,這里以編號最小作為選舉演算法,那么編號最小的節點將在選舉中獲勝并獲得鎖成為主節點,也就是“節點A”將會獲得鎖成為主節點,然后“節點B”將被阻塞成為一個備用節點,這樣,通過這種方式ZooKeeper 就完成了對兩個Master 行程的調度,完成了主、備節點的分配和協作,
如果“節點A”發生了故障,這時候它在ZooKeeper 所注冊的節點資訊會被自動洗掉,而ZooKeeper 會自動感知節點的變化,發現“節點A”故障后,會再次發出選舉,這時候“節點B”將在選舉中獲勝,替代“節點A”成為新的主節點,這樣就完成了主、被節點的重新選舉,
如果“節點A”恢復了,它會再次向ZooKeeper 注冊自身的節點資訊,只不過這時候它注冊的節點資訊將會變成“master00003”,而不是原來的資訊,ZooKeeper 會感知節點的變化再次發動選舉,這時候“節點B”在選舉中會再次獲勝繼續擔任“主節點”,“節點A”會擔任備用節點,
通俗的講,ZooKeeper相當于一個和事佬的角色,如果兩人之間發生了一些矛盾或者沖突,無法自行解決的話,這個時候就需要ZooKeeper 這個和事佬從中進行調解,而和事佬調解的方式是站在第三方客觀的角度,根據一些規則(如道德規則、法律規則),客觀的對沖突雙方做出合理、合規的判決,
Ambari(大資料運維工具)
Ambari 是一個大資料基礎運維平臺,它實作了Hadoop 生態圈各種組件的自動化部署、服務管理和監控告警,Ambari 通過puppet 實作自動化安裝和配置,通過Ganglia 收集監控度量指標,用Nagios 實作故障報警,目前Ambari 已支持大多數Hadoop 組件,包括HDFS、MapReduce、Oozie、Hive、Pig、Hbase、ZooKeeper、Sqoop、Kafka、Spark、Druid、Storm 等幾十個常用的Hadoop 組件,
作為大資料運維人員,通過Ambari 可以實作統一部署、統一管理、統一監控,可極大提高運維作業效率,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/251611.html
標籤:大數據