為什么要寫這篇筆記?
TiDB自3.0.8版本開始默認使用悲觀事務模型(只限新建集群,從之前的版本升級上來的默認還是使用樂觀事務模式),
事務模型影響著資料庫高并發場景下的寫入性能并且關系到資料的完整性,如果不了解其中的差異那么在面對事務沖突引發的問題時就會比較盲目,
很多新人(包括我在內)在學習TiDB的最初階段對于TiDB的事務模型不甚了解,官方檔案的解釋雖精辟但并不很人性化,這篇筆記從最初的悲觀和樂觀模式的概念出發來探究樂觀模式與悲觀模式的差異,以及優劣,
為了解決什么問題?
精通TiDB的事務模型可以幫助了解日常生產遇到的寫沖突例外,并可以幫助決定是使用悲觀鎖還是樂觀鎖模式,
筆記正文:
TiDB 樂觀事務模型 | PingCAP Docs
TiDB 悲觀事務模型 | PingCAP Docs
完整的官網檔案見上述鏈接,一些FAQ和具體細節就不復制粘貼了,本文主要通過一些描述來幫助理解這兩種事務模型,
一、廣義概念的悲觀鎖和樂觀鎖
樂觀鎖:并發場景下,資料庫認為并發會話之間并不會互相影響,因此在事務的記憶體讀寫階段不對資料加鎖,只在事務提交時進行寫沖突檢測(例如資料版本是否過期,被洗掉等等),
悲觀鎖:并發場景下,資料庫認為并發會話之間的資料寫入是有沖突的,因此在事務做更改的初始階段就會對要修改的資料加鎖,直到事務結束,
樂觀鎖與悲觀鎖模式的主要差異在于:到底是事務提交階段加鎖來檢測事務沖突?還是在事務開始階段就直接對資料加鎖來阻塞其他寫操作?
可以看到,樂觀鎖模式下,只有在事務提交階段才會檢測寫入沖突,而悲觀模式全程加鎖,所以相對而言樂觀模式的并發量會高于悲觀鎖模式,但是其資料一致性性卻比悲觀鎖差,并且事務失敗時需要依賴應用層進行重試,
主流的關系型資料庫例如oracle、sqlserver、mysql等,大多采用悲觀事務模型以保證高并發場景下事務的一致性,
但是這里要強調一下,主流關系型資料庫在事務模型的處理上多采用悲觀事務模型以保證資料一致性,但并不是所有場景都使用悲觀模型,例如mysql的commit和鎖獲取階段都是樂觀事務模型,只有在針對資料的獲取方面采用悲觀模型,而且在RDBMS系統中也鮮少會有產品在所有場景中都采用悲觀模式,因為代價太大,且誰都不能確保自己的網路、硬體等永遠不出問題,
此外這里推幾篇鏈接幫助理解樂觀/悲觀鎖模式:
pessimistic locking vs optimistic locking - Ask TOM (oracle.com)
sql server - Optimistic vs. Pessimistic locking - Stack Overflow
Concurrency Control - SQL Server | Microsoft Docs
二、TiDB的樂觀事務模型
這里可以直接用一幅圖來描述TiDB的樂觀事務模型:
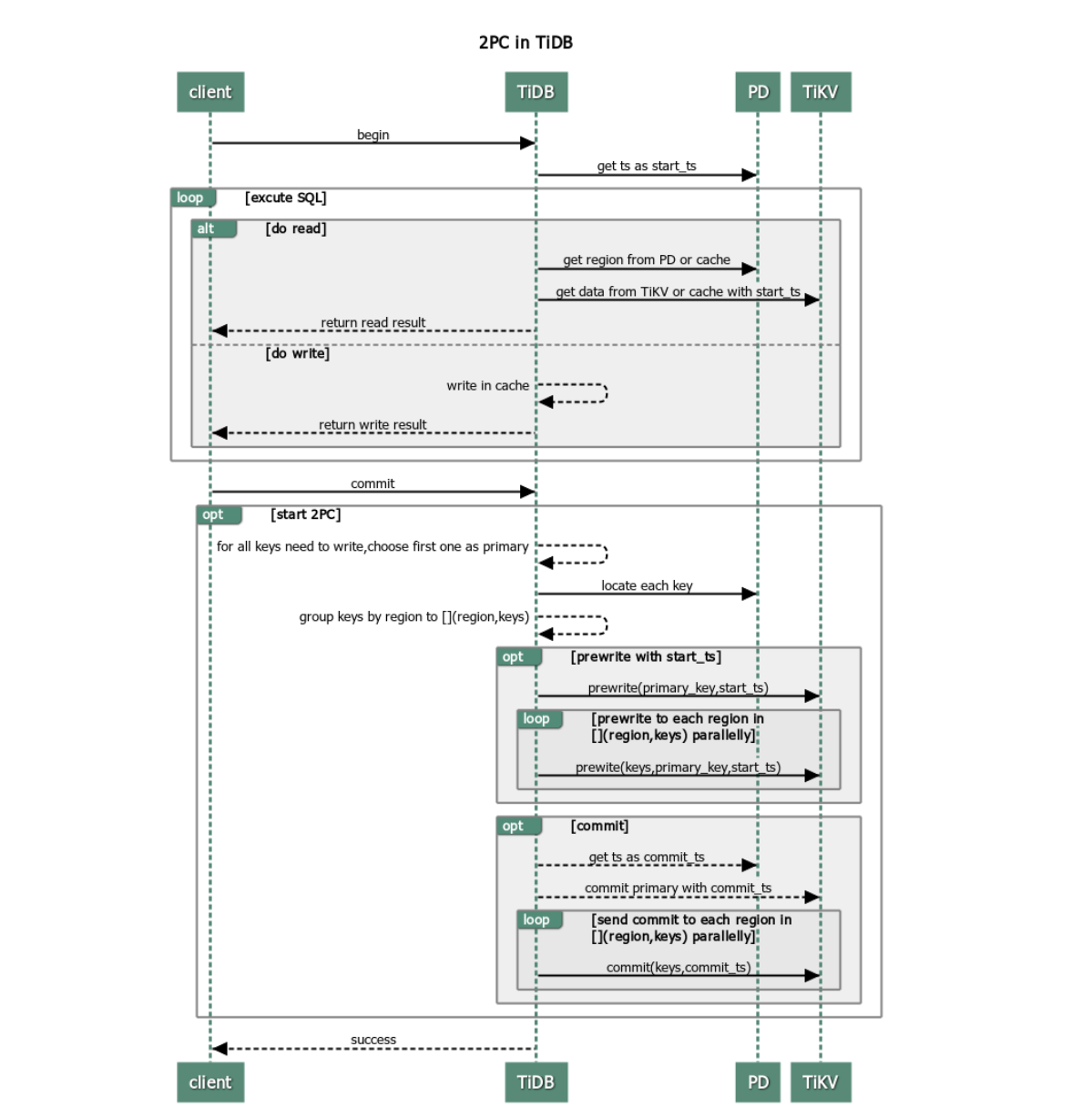
略微決議一下上述的流程,這幅圖需要按從左往右,從上往下順序來看,其主要步驟為(詳細解釋參考官網鏈接):
1.客戶端開啟事務后,tidb向pd獲取一個tso作為事務的start_ts, 理解為start timestamp即可,以下同理,
2.tidb從pd獲取讀取資料的路由(既資料存在哪些tikv節點上),然后從tikv讀取資料,讀取小于此start_ms的最新資料版本,
3.資料在tidb的記憶體中完成修改,
4.客戶端發起commit操作,接下來就是TiDB的兩階段提交流程:
5.第一階段(prewrite階段,也可以叫做加鎖階段):
,tidb將要寫入的資料按照key分類,然后從pd獲取資料的寫入路由(既資料應該寫入到哪些tikv節點),
,tidb并發的向所有涉及的tikv發起請求,tikv收到請求后檢查對應記錄是否過期或者存在版本沖突,正常的話會加鎖,
,tidb收到所有prewrite成功的相應,至此第一階段完成,
6.第二階段(正式提交階段)
,tidb向pd獲取一個tso作為commit_ts
,tidb向tikv發起第二階段的提交請求,tikv進行資料寫入,然后清理第一階段的鎖,
,tidb收到兩階段提交成功的資訊,客戶端收到tidb反饋的事務成功的資訊,
7.最后tidb異步的清理本次事務遺留的鎖資訊,
樂觀事務的優點和缺陷:
樂觀事務的優點在于無需在事務執行階段加鎖,減少了鎖獲取的消耗,這樣可以略微增加并發的性能,但前提是并發之間不會互相影響,
樂觀事務最大的缺陷在于出現寫入沖突時,只有一個會話可以成功,其他的都只能失敗,套用Tom Kyte的一句話就是:
“我特么花了那么多時間來更新資料,結果到提交的時候你告訴我說:對不起你更改的資料已被其他會話變更,請重新開始???”
這就是傳統RDBMS事務中使用悲觀事務模型的原因,因為可以避免此類寫沖突問題,且實際上有很多方法來極大減小悲觀鎖模型下的獲取鎖的消耗,
樂觀事務下的重試機制:
從上邊的描述我們知道,樂觀鎖模型下會出現寫失敗,全部依賴程式解決有點不現實,所以tidb內部增加了重試機制,
重試就相當于重新執行了事務,這樣破壞了原本的事務一致性,可能產生更新丟失,不過一般情況下高并發時的更新丟失不會對業務造成什么影響,更新實際并未丟失,只是先后提交的問題,
以下兩個引數控制重試的行為:
# 設定是否禁用自動重試,默認為 “on”,即不重試,
tidb_disable_txn_auto_retry = OFF
# 控制重試次數,默認為 “10”,只有自動重試啟用時該引數才會生效,
# 當 “tidb_retry_limit= 0” 時,也會禁用自動重試,
tidb_retry_limit = 10
# 上述兩個引數可以session或者global設定
三、TiDB的悲觀事務模型
TiDB如何開啟悲觀事務模式:
SET GLOBAL tidb_txn_mode = 'pessimistic';
# 或者執行以下 SQL 陳述句顯式地開啟悲觀事務:
BEGIN PESSIMISTIC;
在了解了樂觀事務之后,我們再理解悲觀事務就很簡單了,樂觀事務不是在提交階段才加鎖嗎,悲觀事務就是事務的起始階段就加鎖,
以上邊樂觀事務的圖為例,加鎖就發生在get data from TiKV or cache with start_ts階段,如果事務中包含select陳述句(不帶for update的)那么會在執行首個DML陳述句時加鎖,
另外悲觀模式下由于阻塞獲取鎖失敗也有次數限制,默認256次,可以通過pessimistic-txn.max-retry-limit修改,
悲觀事務下可以解決樂觀事務模型下寫入沖突的問題嗎?
想啥呢......當然不可以,悲觀事務模式下同一時刻依然只能有一個會話執行成功,但是其他會話并不是直接失敗,而是被阻塞直到可以獲取鎖,這種模式更接近innodb的悲觀鎖模式,可以避免程式進行寫沖突處理,或者避免事務重試時造成的更新丟失,
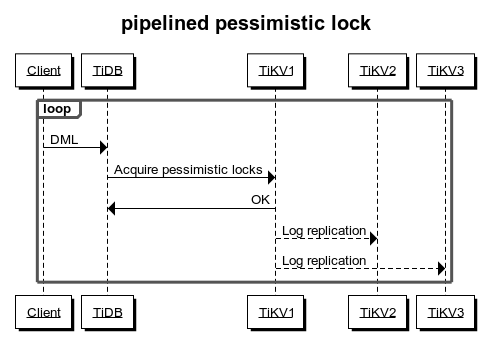
Pipelined加鎖流程(默認關閉的):
悲觀事務模型下事務加鎖需要向tikv寫入資料,經過raft提交ingapply之后才會回傳,這樣開銷比較大,所以TiDB通過pipelined機制降低加鎖消耗:
當資料滿足加鎖要求時,TiKV 立刻通知 TiDB 執行后面的請求,并異步寫入悲觀鎖,從而降低大部分延遲,顯著提升悲觀事務的性能,但當 TiKV 出現網路隔離或者節點宕機時,悲觀鎖異步寫入有可能失敗,從而產生以下影響:
無法阻塞修改相同資料的其他事務,如果業務邏輯依賴加鎖或等鎖機制,業務邏輯的正確性將受到影響,
有較低概率導致事務提交失敗,但不會影響事務正確性,
如果業務邏輯依賴加鎖或等鎖機制,或者即使在集群例外情況下也要盡可能保證事務提交的成功率,應關閉 pipelined 加鎖功能,
四、為什么我們應該使用樂觀/悲觀事務模型?
回到最核心最迫切的問題上,我們的TiDB應該使用哪種事務模型?悲觀or樂觀?
官方的回答如下:
樂觀事務模型下,將修改沖突視為事務提交的一部分,因此并發事務不常修改同一行時,可以跳過獲取行鎖的程序進而提升性能,但是并發事務頻繁修改同一行(沖突)時,樂觀事務的性能可能低于悲觀事務,
啟用樂觀事務前,請確保應用程式可正確處理 commit陳述句可能回傳的錯誤,如果不確定應用程式將會如何處理,建議改為使用悲觀事務,
我的回答如下:
用悲觀事務模型就好了,不要為了一丁點虛無縹緲的性能提升采用樂觀事務模型,而且悲觀事務模型下使用mysql driver訪問tidb的BUG更少,行為更加貼近訪問mysql本身,從我個人的觀測看來,悲觀事務下集群性能相比樂觀事務模型并無下降,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/251634.html
標籤:其它