2年前寫的一篇舊文,文中的分析,以及探討的問題和觀點,至今仍有意義,
本文將以阿里云在GIAC的分享《云原生InfluxDB高可用架構設計》為例,剖析阿里云的自研InfluxDB集群方案的當前實作,在分析中會盡量聚焦的相對確定的技術、架構等,考慮到非一線資訊,在個別細節上難免存在理解偏差,歡迎私聊討論:
微信公眾號:influxdb-dev
FreeTSDB技術交流群(QQ):663274123
0x0 初步結論
目前是一個過渡性質的公測方案,具備資料一致性,但接入性能有限,缺乏水平擴展能力,缺乏自定義副本數和水平擴展等能力,通過Raft或Anti-entroy提升了資料的可靠性,但受限于節點和副本的強映射,集群接入性能有限,約等同于單機接入性能,另外,基于時序分片和分布式迭代器等核心功能未提及,可能仍在預研中,
0x1 集群方案剖析
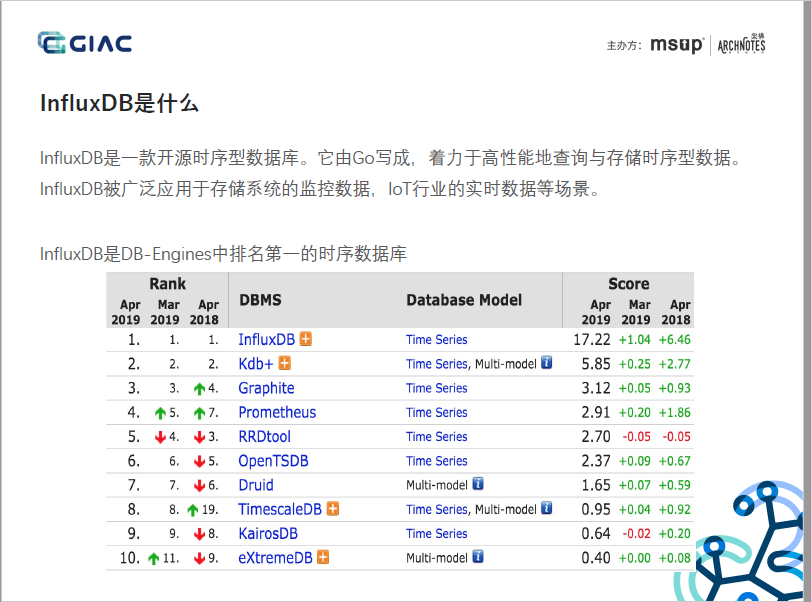
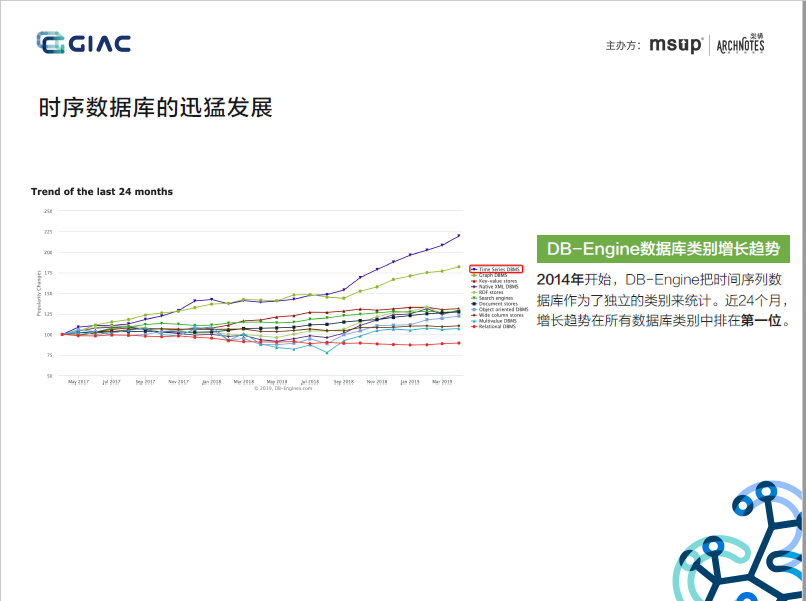
1. 背景補充:InfluxDB是DB-Engines上排名第一的TSDB,針對時序資料多寫、少讀、成本敏感等特點而設計的TSDB,并做了多輪架構迭代和優化,是一款實時、高性能、水平擴展(InfluxDB Enterprise)、具有成本優勢的TSDB,但在2016年,Paul Dix基于商業化和持久運營的考慮,尚未成熟的集群能力在v0.11.1版后,選擇閉源,推出了收費版的InfluxDB Enterprise和InfluxDB Cloud,
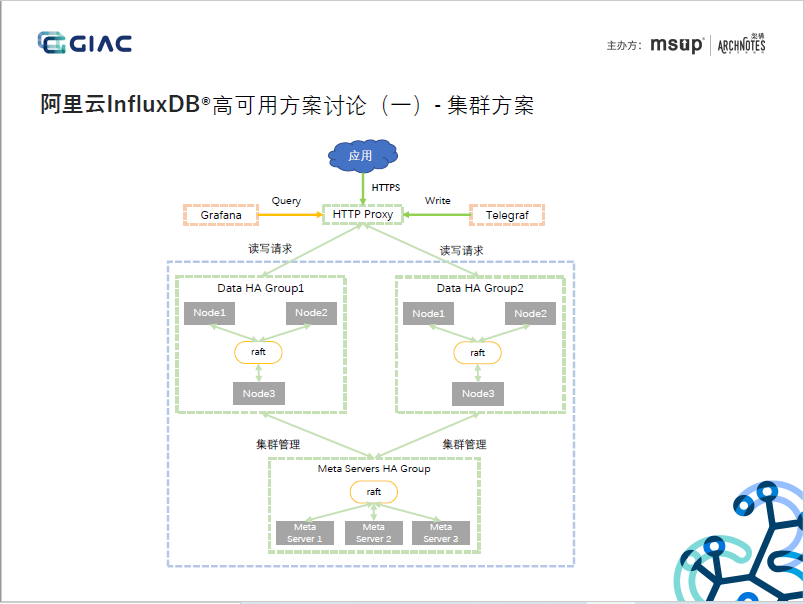
2. 通過Raft協議實作Meta節點的資料一致性,考慮到Meta節點存放的是Database/Rention Policy/Shard Group/Shard Info等元資訊,這些資訊敏感,是系統穩定運行的的關鍵,CP的分布式架構,合適,
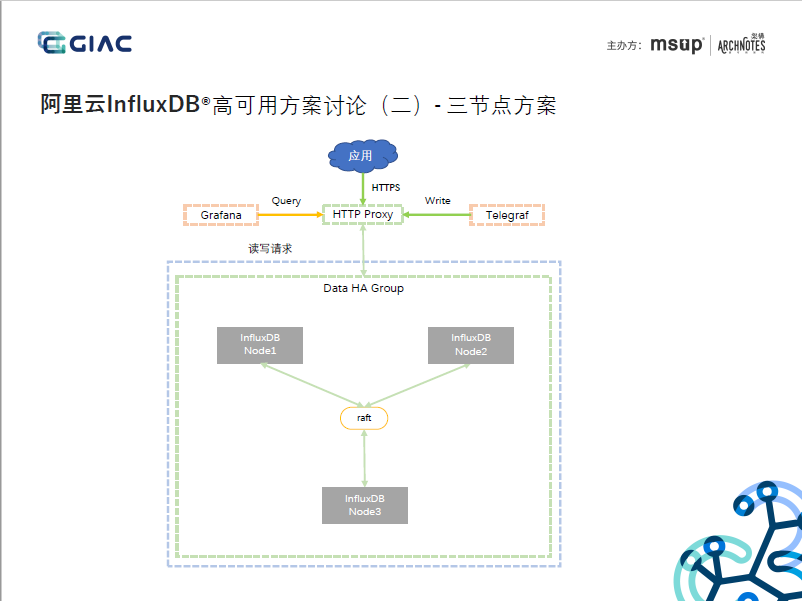
3. 通過Raft協議實作Data節點的資料一致性,考慮到Data節點存盤的是具體的時序資料,性能和水平擴展性是挑戰,對一致性性要求不高(PPT中亦提到這一點),采用CP的分布式架構,節點和副本強映射,不僅對實時性有影響,集群接入性能亦有限,約等同于單機接入性能,不能很好的支持海量資料的實時接入的時序需求,
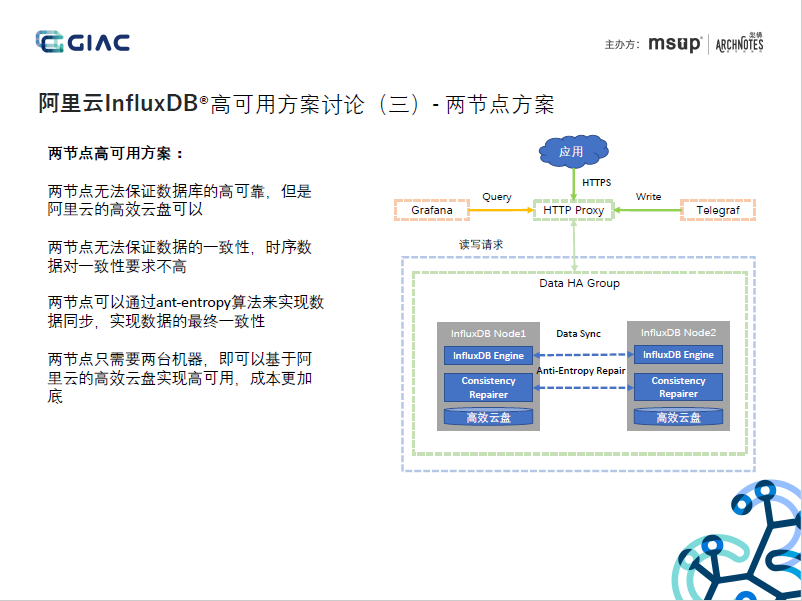
4. 2節點集群方案,通過Anti-entroy實作Data節點的資料一致性,應該還實作了Hinted-handoff能力,AP的分布式架構,但節點和副本還是強映射,未見提及基于時序分配、自定義副本數、分布式迭代器等能力,暫無法水平擴展,
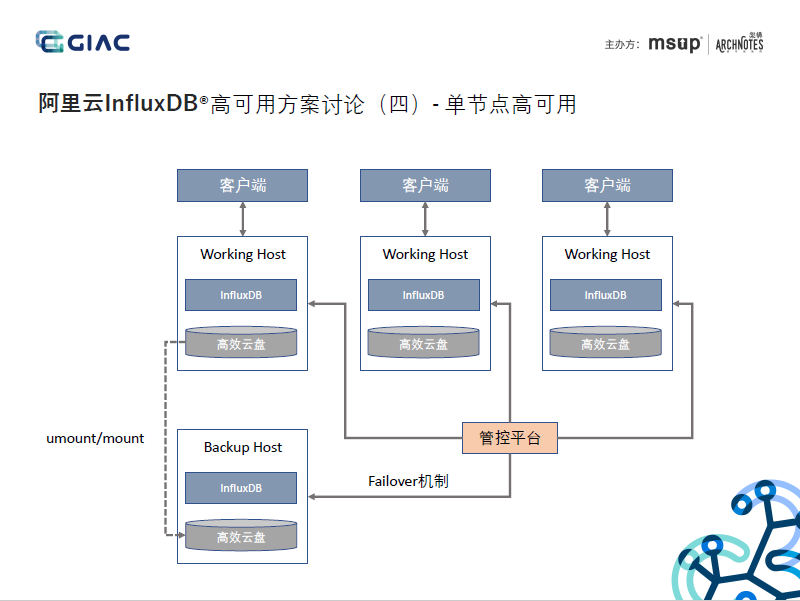
5. 云盤能保障資料的可靠性,但無法保障接入的可用性,可用性敏感的業務或實時要求高的業務,還是推薦多節點的集群模式,
6. 開源版InfluxDB(單機)性能不錯,InfluxDB Enterprise性能不錯,但如何保障補齊集群能力的卓越性能,取決于集群架構、并發架構等,是由集群功能的開發者決定的,這次未見提及性能資料,期待后續的公布,
0x2 附錄








轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/254389.html
標籤:大數據