目錄
- 如何保證資料寫入程序中不丟
- 直接落盤的 translog 為什么不怕降低寫入吞吐量?
- 如何保證已寫資料在集群中不丟
- in-memory buffer
- 總結
- LSM Tree的詳細介紹
- 參考資料
如何保證資料寫入程序中不丟
資料寫入請求達到時,以需要的資料格式組織并寫入磁盤的程序叫做資料提交,對應es就是創建倒排索引,維護segment檔案
如果我們同步的方式,來處理上述程序,那么系統的吞吐量將很低
如果我們以異步的方式,先寫入記憶體,然后再異步提交到磁盤,則有可能因為機器故障而而丟失還未寫入到磁盤中的資料
為了解決這個問題,一般的存盤系統都會設計transag log (事務日志)或這write ahead log(預寫式日志),它的作用時,將最近的寫入資料或操作以日志的形式直接落盤,從而使得即便系統崩潰后,依然可以基于這些磁盤日志進行資料恢復,
Mysql有redo undo log ,而HBASE、LevelDB,RockDB等采用的LSM tree則提供了write ahead log 這樣的設計,來保證資料的不丟失
直接落盤的 translog 為什么不怕降低寫入吞吐量?
上述論述中,資料以同步方式落盤會有性能問題,為什么將translog和wal直接落盤不影響性能?原因如下:
- 寫的日志不需要維護復雜的資料結構,它僅用于記錄還未真正提交的業務資料,所以體量小
- 并且以順序方式寫盤,速度快
es默認是每個請求都會同步落盤translog ,即配置index.translog.durability 為request,當然對于一些可以丟資料的場景,我們可以將index.translog.durability配置為async 來提升寫入translog的性能,該配置會異步寫入translog到磁盤,具體多長時間寫一次磁盤,則通過index.translog.sync_interval來控制
前面說了,為了保證translog足夠小,所以translog不能無限擴張,需要在一定量后,將其對應的真實業務資料以其最終資料結構(es是倒排索引)提交到磁盤,這個動作稱為flush ,它會實際的對底層Lucene 進行一次commit,我們可以通過index.translog.flush_threshold_size 來配置translog多大時,觸發一次flush,每一次flush后,原translog將被洗掉,重新創建一個新的translog
elasticsearch本身也提供了flush api來觸發上述commit動作,但無特殊需求,盡量不要手動觸發
如何保證已寫資料在集群中不丟
對每個shard采用副本機制,保證寫入每個shard的資料不丟
in-memory buffer
前述translog只是保證資料不丟,為了其記錄的高效性,其本身并不維護復雜的資料結構, 實際的業務資料的會先寫入到in-memory buffer中,當呼叫refresh后,該buffer中的資料會被清空,轉而reopen一個segment,使得其資料對查詢可見,但這個segment本身也還是在記憶體中,如果系統宕機,資料依然會丟失,需要通過translog進行恢復
其實這跟lsm tree非常相似,新寫入記憶體的業務資料存放在記憶體的MemTable(對應es的in-memory buffer),它對應熱資料的寫入,當達到一定量并維護好資料結構后,將其轉成記憶體中的ImmutableMemTable(對應es的記憶體segment),它變得可查詢,
總結
-
refresh 用于將寫入記憶體in-memory buffer資料,轉為查詢可見的segment
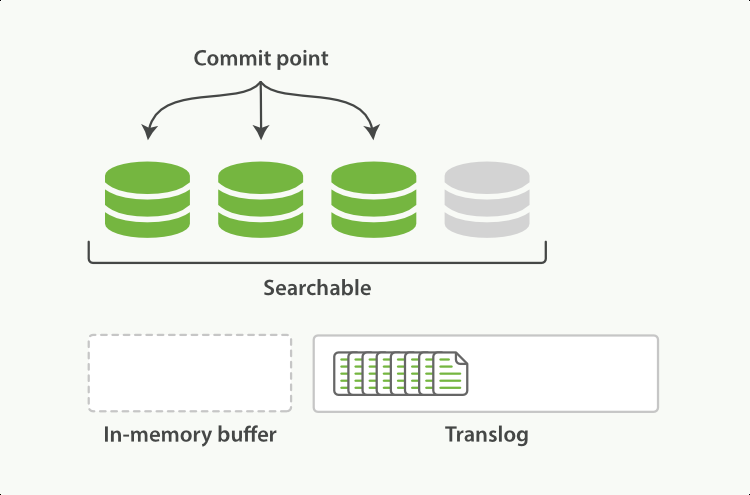
-
每次一次寫入除了寫入記憶體外in-memory buffer,還會默認的落盤translog
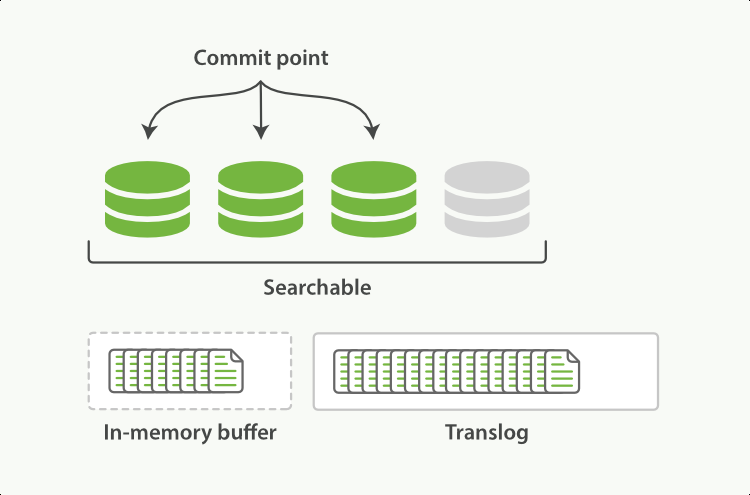
-
translog 達到一定量后,觸發in-memory buffer落盤,并清空自己,這個動作叫做flush
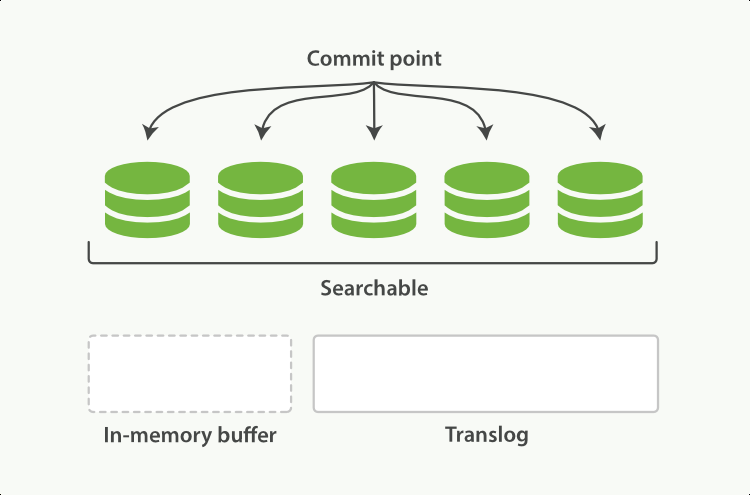
-
如遇當前寫入的shard宕機,則可以通過磁盤中的translog進行資料恢復
LSM Tree的詳細介紹
https://www.cnblogs.com/niceshot/p/14321372.html
參考資料
https://ezlippi.com/blog/2018/04/elasticsearch-translog.html
https://stackoverflow.com/questions/19963406/refresh-vs-flush
https://qbox.io/blog/refresh-flush-operations-elasticsearch-guide/
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-translog.html#index-modules-translog-retention
https://www.elastic.co/guide/cn/elasticsearch/guide/current/translog.html
歡迎關注我的個人公眾號"西北偏北UP",記錄代碼人生,行業思考,科技評論
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/255109.html
標籤:大數據
上一篇:小白求問my sql資料上傳失敗